Capítulo 9 Introdução à distribuição das médias e diferenças entre médias e seus intervalos de confiança
A finalidade de uma amostra é obter uma estimativa do valor de um ou mais parãmetros de uma população.
Observa-se que os valores amostrais repetidamente extraídos de modo aleatório de uma mesma população variam de uma para outra amostra e também em relação ao verdadeiro parâmetro dessa população; todavia, demonstra-se que essa variabilidade pode ser descrita por meio de distribuições de probabilidade.
Distribuições de probabilidade quando usadas para esse propósito são denominadas de distribuições amostrais e permitem responder para cada amostra o quão próxima está a estatística amostral do verdadeiro parâmetro populacional. Essa resposta depende fundamentalmente de três fatores:
- a estatistica que está sendo utilizada: diferentes estatísticas requerem diferentes distribuições de probabilidade para modelar sua variabilidade;
- o tamanho da amostra que implica de modo inverso na variabilidade entre as amostras;
- a variabilidade existente na própria população sob estudo e amostragem.
9.1 Distribuições amostrais
Parâmetro é toda medida numérica descritiva de uma população. Quando essas medidas são calculadas sobre amostras extraídas de uma população passam a ser denominadas como estatísticas da população de origem. A média, a mediana, a variância, a proporção amostrais, assim como outras estatísticas amostrais, são exemplos de variáveis aleatórias (v.a.) uma vez que seus valores sofrem variação a cada amostra extraída.
Considere uma população com \(N\) elementos da qual se deseja extrair todas as possíveis amostras de tamanho \(n\). Para cada amostra extraída pode-se calcular uma mesma medida descritiva como, por exemplo, a média ( ou a variância, proporção ). O conjunto dos valores resultantes nos permite analisar como as estimativas amostrais se distribuem em comparação ao parâmetro que estão a estimar.
Essas distribuições são denominadas distribuições amostrais. O estudo das distribuições amostrais é um elemento fundamental na inferência estatística posto possibilitar o estabelecimento de intervalos de confiança relacionados ao valor de um parâmetro que se deseja inferir, a partir de uma estatística proveniente de uma única amostra.
O processo de extração de amostras pode ser com ou sem reposição. A extração com reposição assegura a independência entre os eventos e, eventos independentes são mais facilmente analisados.
O quantidade possível de amostras de tamanho \(n\) extraídas de uma população de tamanho \(N\) é dado por :
- com reposição: \(N^{n}\); e,
- sem reposição: \(C_{(N.n)}\)
Mais adiante veremos que processos de extração de amostras de tamanho \(n\), sem reposição de populações finitas com parâmetros \(\mu\) (média) e \(\sigma^{2}\) (variância) a esperança da v.a. de sua média amostral ainda é dada por:
\[ E(\stackrel{-}{X})=\mu \]
mas sua variância deve ser corrigida de:
\[ Var(\stackrel{-}{X}) =\frac{\sigma^{2}}{n} \]
para:
\[ Var(\stackrel{-}{X}) =\frac{\sigma^{2}}{n} \cdot (\frac{N-n}{N-1}) \]
em que \((\frac{N-n}{N-1})\) é denominado como fator de correção para populações finitas.
Para ilustrar o conceito de distribuição das médias amostrais considere uma situação onde uma empresa produz lâmpadas e a vida útil média, em horas, dessas lâmpadas segue uma distribuição Normal tal que \(VU \sim N (1600, 120)\).
Usando conceitos já explicados em uma unidade anterior podemos determinar o tamanho amostral em função de:
- um erro máximo: \(\varepsilon\)=20 horas;
- um nível de significância estabelecido: \(\alpha\)=0,05; e,
- e alguma informação sobre a medida da variabilidade da variável em estudo: \(\sigma\)=120 horas (no caso, o desvio padrão populacional).
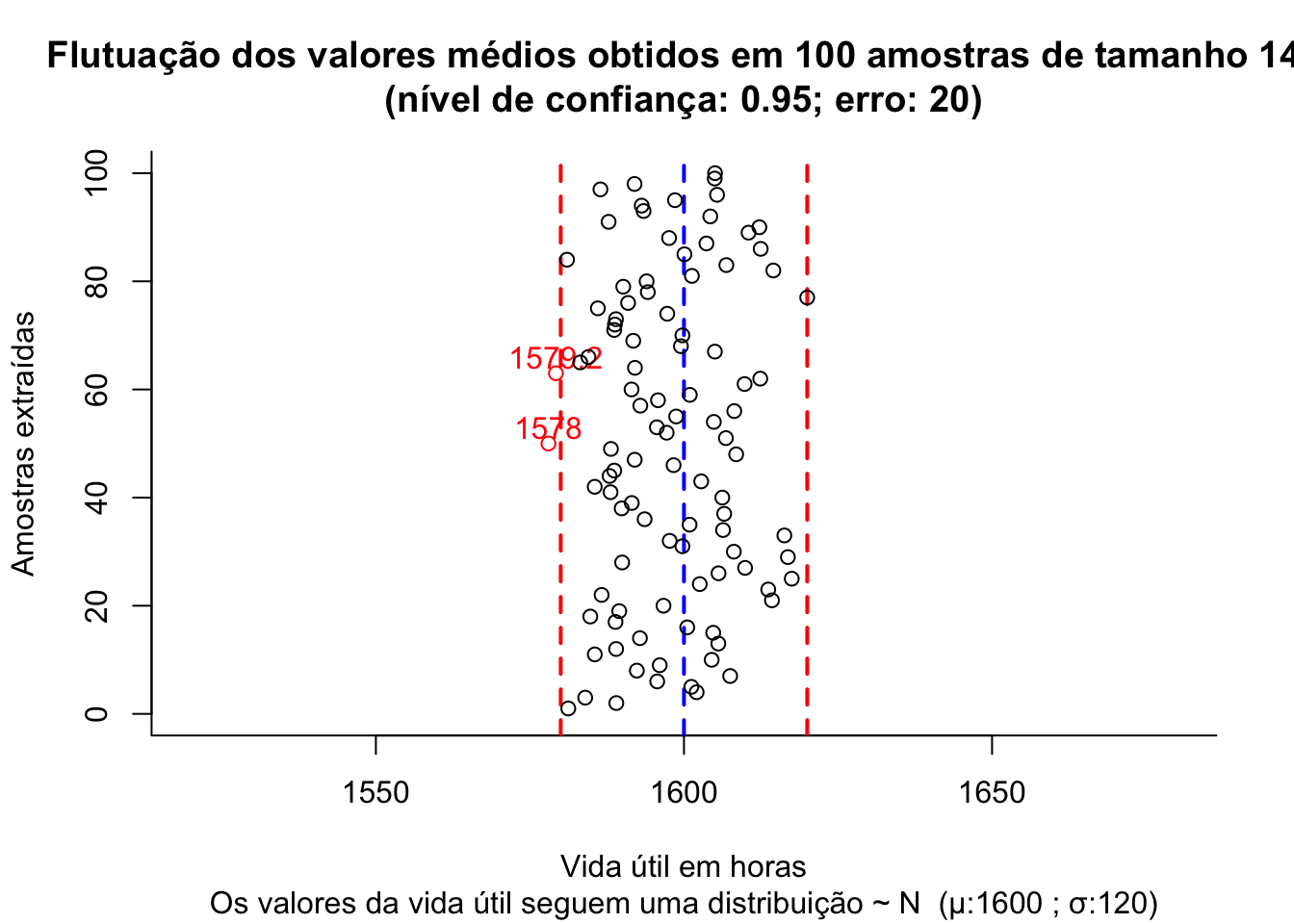
Figure 9.1: Flutuação dos valores médios para diversas amostras extraídas de uma mesma população distribuição \(\sim N (\mu; \sigma)\)
## mu media erro li ls
## 1 1600 1599 -1.0856 1580 1618
## 2 1600 1614 14.3463 1594 1635
## 3 1600 1604 4.1662 1584 1624
## 4 1600 1608 7.8953 1588 1627
## 5 1600 1613 12.6500 1593 1632
## 6 1600 1586 -14.1889 1565 1607
## 7 1600 1601 1.3962 1582 1621
## 8 1600 1619 19.3306 1598 1640
## 9 1600 1601 1.2339 1581 1621
## 10 1600 1597 -2.6549 1577 1617
## 11 1600 1588 -12.2537 1568 1607
## 12 1600 1626 25.6130 1607 1644
## 13 1600 1580 -19.8744 1558 1602
## 14 1600 1597 -3.3424 1575 1618
## 15 1600 1590 -9.9420 1571 1609
## 16 1600 1609 8.7537 1589 1628
## 17 1600 1594 -6.1080 1575 1613
## 18 1600 1593 -7.3077 1573 1612
## 19 1600 1605 4.7415 1585 1624
## 20 1600 1605 5.2196 1588 1623
## 21 1600 1605 5.3416 1585 1625
## 22 1600 1604 4.0323 1585 1623
## 23 1600 1616 15.8762 1596 1636
## 24 1600 1615 14.8850 1596 1634
## 25 1600 1601 0.8948 1584 1617
## 26 1600 1609 9.4566 1590 1629
## 27 1600 1576 -24.3111 1554 1597
## 28 1600 1612 11.5578 1591 1632
## 29 1600 1599 -1.3362 1579 1619
## 30 1600 1593 -7.3571 1573 1612
## 31 1600 1614 13.8285 1593 1635
## 32 1600 1604 3.8546 1583 1625
## 33 1600 1608 8.0541 1589 1627
## 34 1600 1586 -13.7433 1565 1608
## 35 1600 1579 -20.9693 1561 1597
## 36 1600 1600 0.2100 1581 1619
## 37 1600 1588 -11.8869 1566 1610
## 38 1600 1608 8.1950 1588 1628
## 39 1600 1597 -3.0648 1577 1617
## 40 1600 1607 7.1415 1586 1628
## 41 1600 1589 -11.2329 1568 1610
## 42 1600 1610 10.4467 1592 1629
## 43 1600 1602 2.2737 1581 1624
## 44 1600 1611 11.2299 1591 1632
## 45 1600 1616 16.1010 1597 1635
## 46 1600 1609 9.0109 1588 1630
## 47 1600 1593 -6.5897 1570 1617
## 48 1600 1602 2.4795 1584 1621
## 49 1600 1630 30.2898 1610 1650
## 50 1600 1597 -2.7439 1576 1619
## 51 1600 1600 -0.2926 1580 1620
## 52 1600 1609 8.6434 1588 1629
## 53 1600 1593 -7.1497 1574 1612
## 54 1600 1610 10.0960 1592 1628
## 55 1600 1601 1.4032 1581 1622
## 56 1600 1605 5.1321 1586 1625
## 57 1600 1616 15.7166 1598 1633
## 58 1600 1596 -3.7894 1577 1615
## 59 1600 1595 -5.2619 1574 1615
## 60 1600 1596 -3.6082 1576 1617
## 61 1600 1597 -3.0671 1577 1617
## 62 1600 1578 -22.4352 1556 1599
## 63 1600 1588 -12.0989 1569 1607
## 64 1600 1594 -6.4265 1574 1613
## 65 1600 1608 7.7605 1588 1628
## 66 1600 1590 -10.0710 1569 1610
## 67 1600 1608 8.2470 1585 1631
## 68 1600 1598 -2.1372 1578 1618
## 69 1600 1599 -0.7233 1579 1619
## 70 1600 1619 19.0269 1599 1639
## 71 1600 1605 5.4319 1584 1627
## 72 1600 1574 -26.0998 1554 1594
## 73 1600 1604 3.8444 1584 1624
## 74 1600 1627 26.6459 1608 1646
## 75 1600 1601 1.4894 1583 1620
## 76 1600 1607 7.4056 1588 1627
## 77 1600 1618 17.9718 1599 1636
## 78 1600 1615 15.3244 1598 1633
## 79 1600 1610 9.9493 1591 1629
## 80 1600 1615 14.8250 1598 1632
## 81 1600 1615 15.2885 1595 1636
## 82 1600 1607 7.4868 1585 1630
## 83 1600 1594 -6.1990 1573 1614
## 84 1600 1604 4.1309 1582 1626
## 85 1600 1585 -15.2283 1564 1605
## 86 1600 1606 6.2040 1586 1627
## 87 1600 1608 7.7099 1591 1625
## 88 1600 1597 -2.8133 1576 1618
## 89 1600 1582 -18.1541 1563 1600
## 90 1600 1586 -13.7939 1567 1606
## 91 1600 1609 9.0958 1589 1629
## 92 1600 1586 -14.4688 1567 1604
## 93 1600 1596 -4.2063 1577 1614
## 94 1600 1605 4.5591 1585 1624
## 95 1600 1597 -3.4301 1577 1616
## 96 1600 1594 -5.8995 1575 1614
## 97 1600 1611 10.7243 1591 1631
## 98 1600 1599 -1.0413 1579 1619
## 99 1600 1597 -2.5286 1576 1619
## 100 1600 1597 -3.1537 1577 1617
Observa-se no gráfico acima que algumas das amostras (em vermelho), numa proporção igual ao nível de significância estabelecido quando do dimensionamento (5%), geram médias (amostrais) se afastam do valor médio na população mais que o erro estabelecido (20 h).
9.2 Intervalos de confiança
Um intervalo de confiança (\(IC\)) pode ser entendido com a faixa de valores delimitada por um mínimo e um máximo, calculados como função direta de um nível de confiança e da variabilidade e inversa da tamanho amostral.
\[ \text{estimativa amostral} \pm confiança.\sqrt\frac{variabilidade}{n} \]
Raramente se dispõe de informação a respeito da variabilidade (\(\sigma^{2}\)) da população estudada. Assim, a variabilidade populacional será frequentemente incorporado na expressão acima, com ligeiras modificações, na forma de sua estimativa amostral (\(S^{2}\)).
De certo modo, um intervalo de confiança reflete uma estimativa objetiva da (im)precisão e do tamanho da amostra de determinada pesquisa e, assim, podemos considerá-lo como uma medida da qualidade da amostra e da pesquisa.
O nível de confiança é designado pela quantidade \((1-\alpha)\) na qual \(\alpha\) é denominado de nível de significância, uma medida da probabilidade de erro.
Dependendo do nível de confiança que escolhemos os limites superior e inferior do intervalo mudam para uma mesma estimativa amostral. Os intervalos de confiança mais utilizados na literatura são os de 90%, 95%, 99% e menos de 99,9%.
O intervalo de confiança de 95% é tradicionalmente o intervalo mais utilizado na literatura e isso está relacionado ao nível de significância estatística (\(P<0,05\)) geralmente mais aceito.
Quanto menor for a amplitude de um intervalo, maior será a precisão da estimativa. Todavia, somente estudos com amostras razoavelmente grandes resultarão em um intervalo de confiança estreito, indicando simultaneamentente com alta precisão e alto grau de confianla a estimativa do parâmetro.
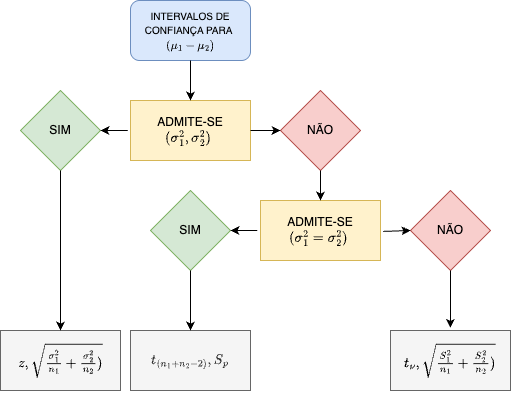
Intervalos de confiança podem ser construídos a quase todas as quantidades estatísticas e suas diferenças (quando se procura estudar se há ou não diferenças entre os parâmetros de duas populaçoes) como, por exemplo:
- médias;
- proporções; e,
- variâncias.
Um intervalo de confiança estabelecido sob certa probabilidade não deve ser interpretado como sendo a faixa de valores, delimitada por um mínimo e máximo, entre os quais o parâmetro da população (o qual se estima ou sobre o qual se infere) se insere.
Mas sim que, extraíndo-se um grande número de amostras de igual tamanho e da mesma população, e construindo-se para cada uma dessas amostras um intervalo de confiança de um mesmo nível de significância (\(\alpha\)), observaremos que uma determinada proporção desses intervalos, chamada de nível de confiança (\(1-\alpha\)) irá, de fato, conter o parâmetro sobre o qual se estima ou sobre o qual se infere. Por conseguinte, uma proporção desses intervalos chamada de nível de significância (\(\alpha\)) não irá conter o verdadeiro valor do parâmetro populacional.
Assim, \((1-\alpha)\) traduz o grau de confiança que se tem que um intervalo de confiança, calculado sobre uma estatística advinda de uma particular amostra de tamanho \(n\) da variável aleatória \(X\), inclua o verdadeiro valor do parâmetro da população:
IC.N = function (N, n, mu, sigma, conf) {
dados=data.frame()
plot(0, 0,
type="n",
xlim=c(mu-0.4*mu,mu+0.4*mu),
ylim=c(0,N),
bty="l",
xlab="Escala de valores da variável",
ylab="Intervalos amostrais construídos",
main=paste0("Intervalos com iguais níveis de confiança fixados em ", 100*conf, "% \n(",N," amostras de tamanho ",n,")") ,
sub=paste0("Parâmetros da distribuição da população Normal ( \u03bc, \u03c3) = (",mu,", ", sigma,")"))
abline(v=mu, col='red', lwd=2, lty=2)
#axis(1, at = c(mu-1*mu, mu, mu+1*mu))
zc = qnorm(1-((1-conf)/2))
#sigma.xbarra = sigma/sqrt(n)
for (i in 1:N) {
x = rnorm(n, mu, sigma)
media = mean(x)
erro= media-mu
sd = sd(x)
li = media - zc * sd/(sqrt(n))
ls = media + zc * sd/(sqrt(n))
temp=cbind(mu, media, erro, li, ls)
dados=rbind(dados, temp)
plotx = c(li,ls)
ploty = c(i,i)
if (li > mu | ls < mu) lines(plotx,ploty, col="red", lwd=2, lend=0)
else lines(plotx,ploty, lend=0)
if (li > mu | ls < mu) points(media, i, col="red", cex=1)+text(y=i+3,x=media, labels=round(media,1), cex=1, col='red')
else points(media, i, col="black", cex=1)
}
colnames(dados)=c("mu", "media", "erro", "li", "ls")
return(dados)
}
## mu media erro li ls
## 1 9.421 9.344 -0.077408 8.288 10.399
## 2 9.421 10.140 0.718552 9.252 11.027
## 3 9.421 10.007 0.585688 8.987 11.027
## 4 9.421 10.220 0.799104 9.202 11.238
## 5 9.421 9.268 -0.153111 8.306 10.230
## 6 9.421 9.985 0.563871 8.934 11.036
## 7 9.421 8.733 -0.687516 7.744 9.723
## 8 9.421 9.482 0.061217 8.467 10.498
## 9 9.421 9.353 -0.067643 8.268 10.439
## 10 9.421 9.383 -0.038413 8.303 10.462
## 11 9.421 9.137 -0.284374 7.945 10.328
## 12 9.421 8.853 -0.568324 7.777 9.929
## 13 9.421 9.381 -0.039604 8.294 10.469
## 14 9.421 8.799 -0.622063 7.496 10.102
## 15 9.421 8.923 -0.497640 7.944 9.902
## 16 9.421 9.190 -0.230536 8.258 10.123
## 17 9.421 9.184 -0.237389 8.249 10.119
## 18 9.421 9.387 -0.034080 8.466 10.308
## 19 9.421 8.796 -0.625320 7.788 9.803
## 20 9.421 8.420 -1.000647 7.252 9.589
## 21 9.421 9.880 0.459263 8.840 10.921
## 22 9.421 10.411 0.989740 9.579 11.243
## 23 9.421 9.553 0.132423 8.551 10.556
## 24 9.421 9.686 0.265474 8.634 10.739
## 25 9.421 9.732 0.311073 8.692 10.773
## 26 9.421 9.144 -0.277387 8.013 10.274
## 27 9.421 9.626 0.205006 8.545 10.707
## 28 9.421 8.905 -0.516264 7.880 9.929
## 29 9.421 8.321 -1.099800 7.286 9.357
## 30 9.421 9.521 0.100018 8.518 10.524
## 31 9.421 8.416 -1.004997 7.382 9.450
## 32 9.421 9.213 -0.208023 7.987 10.439
## 33 9.421 9.280 -0.140543 8.161 10.400
## 34 9.421 9.161 -0.259891 8.030 10.292
## 35 9.421 9.102 -0.319170 8.077 10.127
## 36 9.421 8.980 -0.441197 8.002 9.957
## 37 9.421 9.706 0.285197 8.697 10.716
## 38 9.421 10.363 0.942260 9.319 11.408
## 39 9.421 9.643 0.221782 8.695 10.590
## 40 9.421 9.738 0.317357 8.595 10.882
## 41 9.421 9.618 0.197414 8.601 10.636
## 42 9.421 10.515 1.093617 9.565 11.464
## 43 9.421 9.814 0.392513 8.818 10.809
## 44 9.421 8.946 -0.474611 7.988 9.905
## 45 9.421 9.300 -0.120994 8.225 10.375
## 46 9.421 9.199 -0.222316 8.190 10.208
## 47 9.421 9.877 0.455944 8.773 10.981
## 48 9.421 9.435 0.014165 8.350 10.520
## 49 9.421 9.066 -0.354607 8.183 9.950
## 50 9.421 9.728 0.306830 8.653 10.802
## 51 9.421 9.065 -0.355814 8.034 10.096
## 52 9.421 8.578 -0.842595 7.513 9.644
## 53 9.421 9.781 0.360113 8.792 10.771
## 54 9.421 9.411 -0.009666 8.335 10.488
## 55 9.421 8.603 -0.817612 7.658 9.549
## 56 9.421 9.914 0.493011 8.937 10.891
## 57 9.421 8.978 -0.443131 8.093 9.863
## 58 9.421 7.474 -1.947005 6.382 8.566
## 59 9.421 9.090 -0.331381 8.079 10.100
## 60 9.421 8.562 -0.858563 7.433 9.692
## 61 9.421 10.007 0.585652 8.844 11.169
## 62 9.421 8.906 -0.515387 8.074 9.737
## 63 9.421 9.825 0.404171 8.888 10.762
## 64 9.421 9.167 -0.254252 8.103 10.231
## 65 9.421 8.842 -0.578862 7.810 9.875
## 66 9.421 9.838 0.417392 8.757 10.920
## 67 9.421 9.591 0.170023 8.554 10.628
## 68 9.421 9.752 0.330629 8.654 10.849
## 69 9.421 9.563 0.141673 8.570 10.555
## 70 9.421 9.442 0.020826 8.417 10.466
## 71 9.421 10.388 0.967484 9.371 11.406
## 72 9.421 9.203 -0.218295 8.163 10.243
## 73 9.421 9.134 -0.287415 8.160 10.107
## 74 9.421 9.304 -0.117257 8.415 10.192
## 75 9.421 9.520 0.098663 8.591 10.448
## 76 9.421 8.838 -0.583425 7.699 9.976
## 77 9.421 8.485 -0.935595 7.497 9.473
## 78 9.421 8.866 -0.555385 7.689 10.042
## 79 9.421 10.497 1.075824 9.526 11.468
## 80 9.421 10.545 1.124079 9.580 11.510
## 81 9.421 9.487 0.066107 8.620 10.355
## 82 9.421 10.101 0.680126 9.184 11.018
## 83 9.421 9.414 -0.006713 8.392 10.437
## 84 9.421 9.760 0.338811 8.739 10.781
## 85 9.421 9.827 0.406379 8.886 10.768
## 86 9.421 9.022 -0.398544 7.899 10.146
## 87 9.421 9.670 0.248771 8.841 10.499
## 88 9.421 10.086 0.664643 9.182 10.989
## 89 9.421 9.356 -0.064845 8.400 10.313
## 90 9.421 9.304 -0.117167 8.198 10.410
## 91 9.421 9.059 -0.361593 8.119 10.000
## 92 9.421 9.242 -0.179090 8.039 10.445
## 93 9.421 8.701 -0.720189 7.710 9.692
## 94 9.421 9.049 -0.372195 7.949 10.148
## 95 9.421 9.116 -0.305035 7.976 10.256
## 96 9.421 9.040 -0.381194 7.812 10.268
## 97 9.421 9.478 0.057042 8.556 10.400
## 98 9.421 9.156 -0.265020 8.160 10.152
## 99 9.421 9.515 0.094158 8.558 10.472
## 100 9.421 9.389 -0.032377 8.332 10.445
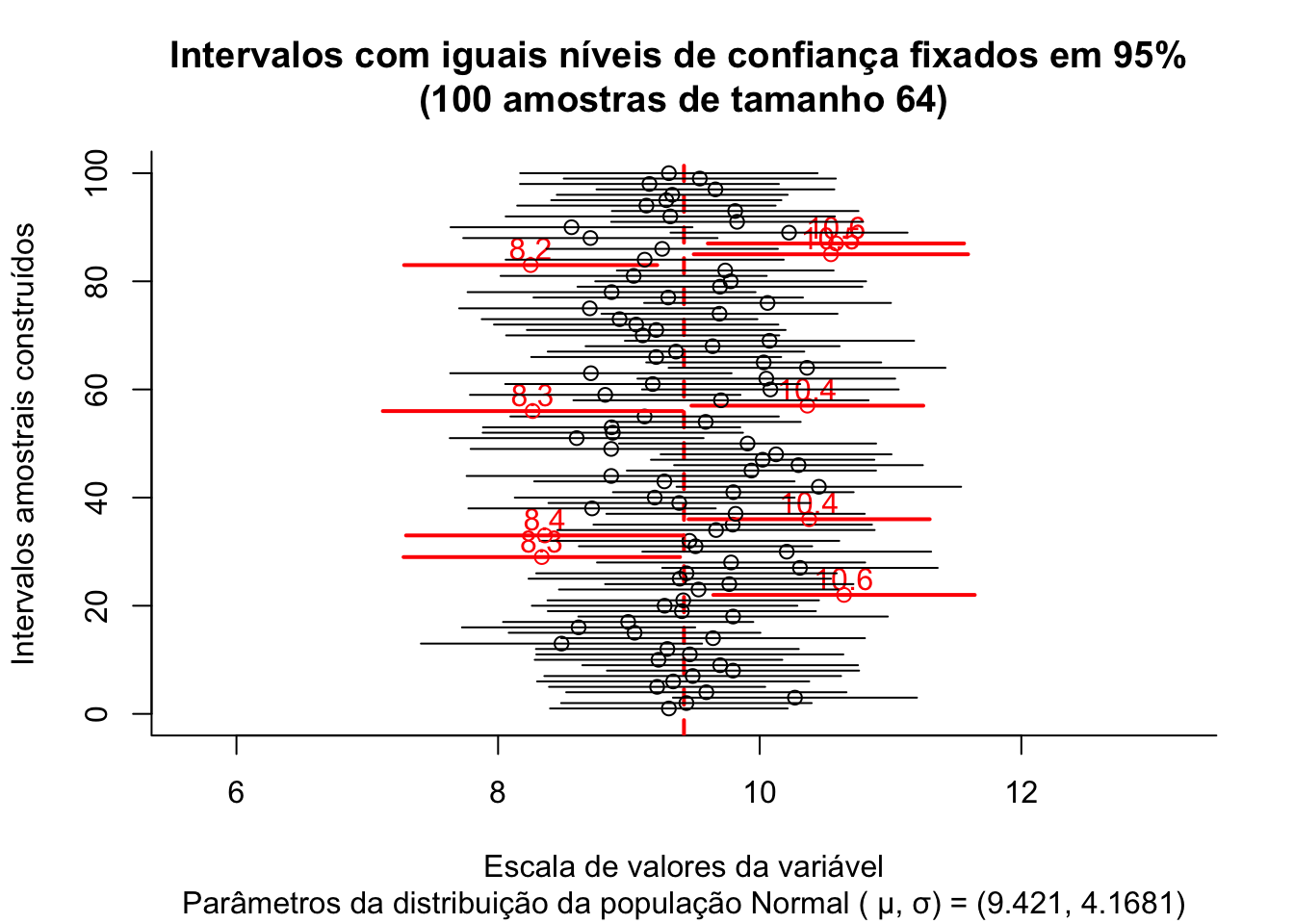
O gráfico acima expõe os intervalos de confiança: \((1-\alpha)\)=95% produzidos para as 100 médias de amostras de tamanho 64 extraídas de uma população com parâmetros \(\mu:\) 9.421 e \(\sigma:\) 4.1681.
A proporção de intervalos amostrais que não contém o verdadeiro valor do parâmetro populacional pode ser visualmente inspecionada pelas linhas em vermelho.
Intervalos de confiança bilaterais: intervalos delimitados por dois valores: mínimo e máximo, para a proporção amostral, dentro do qual todos os valores possuem um mesmo nível de confiança de ocorrência.
Intervalos de confiança unilaterais: intervalos delimitados apenas em um de seus lados, nos quais todos os valores possuem um mesmo nível de confiança. Podem ser limitados à direita por um valor máximo ou limitados à esquerda por um valor mínimo.
9.3 Distribuição das médias amostrais e seus intervalos de confiança
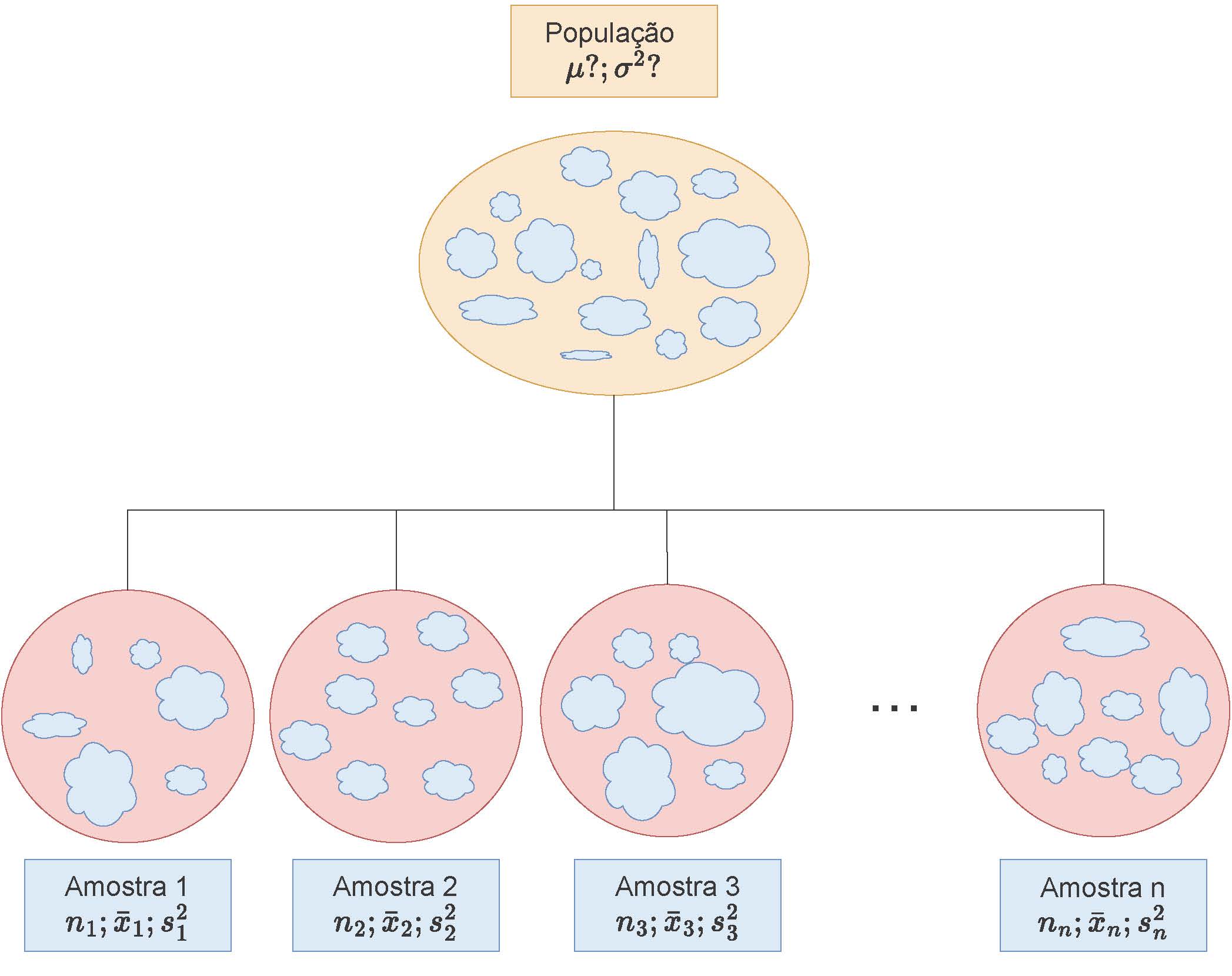
Figure 9.2: Ilustração esquemática de \(n\) amostras extraídas de uma mesma população de parâmetros \(\mu\) e \(\sigma\), cada uma apresentando as respectivas estatísticas calculadas
Para estudarmos a distribuição das médias amostrais considerem uma população com parâmetros \(\mu\) (média) e \(\sigma^{2}\) (variância).
A distribuição das médias amostrais expressa como se distribuem os valores dessa estatística calculada para todas as possíveis amostras de tamanho n extraídas de uma população cujo valor desse parãmetro é desconhecido.
A convergência da forma de distribuição e dos parâmetros da distribuição das médias amostrais são elucidadas pelas Leis (fraca e forte) dos Grandes Números e pelo Teorema Central do Limite (George Pólya, 1920).
De acordo com a teoria, pelo uso de simulações computacionais consegue-se ilustrar que para uma amostra de tamanho n (onde \(x_{1},x_{1},...,x_{n}\) são os valores assumidos das variáveis aleatórias \(X_{1},X_{1},...,X_{n}\)) em amostras extraídas de uma população infinita de tamanho N com média \(\mu\) e variância \(\sigma^{2}\)) a distribuição das médias amostrais (v.a. \(\stackrel{-}{X}\)) segue uma distribuição com os média \(=\mu\) e variância \(=\frac{\sigma^{2}}{n}\) pois:
\[\begin{align*} E(\stackrel{-}{X}) & = \frac{1}{n} \cdot \{E(X_{1})+E(X_{2})+...+E(X_{n})\} \\ & = (\frac{1}{n})\cdot\{\mu+\mu+...+\mu\} = \frac{n\cdot\mu}{n} = \mu \end{align*}\]
\[\begin{align*} Var(\stackrel{-}{X}) & = \frac{1}{n^{2}} \cdot \{Var(X_{1})+Var(X_{2}+...+Var(X_{n})\} \\ & = (\frac{1}{n^{2}}) \cdot \{\sigma^{2}+\sigma^{2}+...+\sigma^{2}\} = n \cdot \frac{\sigma^{2}}{n^{2}} = \frac{\sigma^{2}}{n} \end{align*}\]
Equivale afirmar que, independentemente da forma de distribuição da população de origem da qual são extraídas as amostras, a distribuição dos valores da variável aleatória \(\stackrel{-}{X}\) tenderá a seguir uma distribuição \(\sim N(\mu;\frac{\sigma^{2}}{n}\)) à medida que n , o tamanho da amostra aumenta, como ilustrado nas Figuras 9.3 e 9.5.
O TCL garante a aproximação da distribuição de \(\stackrel{-}{X}\) a uma distribuição Normal com média \(\mu\) e variância \(\frac{\sigma^{2}}{n}\) quando \(n\) é grande, independentemente da distribuição da população de origem. Na prática, essa aproximação é usada quando \(n\ge 30\).
Portanto, para populações infinitas ou amostragem com reposição:
\[ \stackrel{-}{X} \sim N(\mu, \frac{\sigma^{2}}{n}) \]
Demostração usando amostras extraídas de uma população com distribuição \(\sim U (v_{min}; v_{max})\)
# Definindo os parãmetros e a amostra
min_1=2
max_1=6
NN=5000
pop_1=runif(NN, min=min_1, max=max_1)
df=as.data.frame(pop_1)
# A distribuição da população ilustrada em um histograma
ggplot(df, aes(x=pop_1)) +
geom_histogram( binwidth=1,color="black", fill="lightblue")+
scale_y_continuous(name="Frequência") +
scale_x_continuous(name="Valores")+
labs(title= paste("Histograma de uma população com Distribuição Uniforme"),
subtitle = paste("Parâmetros: valor min =",min_1,"; valor max =", max_1))+
theme(plot.title = element_text(size = 10, face = "bold"),
axis.text.x = element_text(angle=0, hjust=1, size=10),
axis.text.y = element_text(angle=0, hjust=1, size=10),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))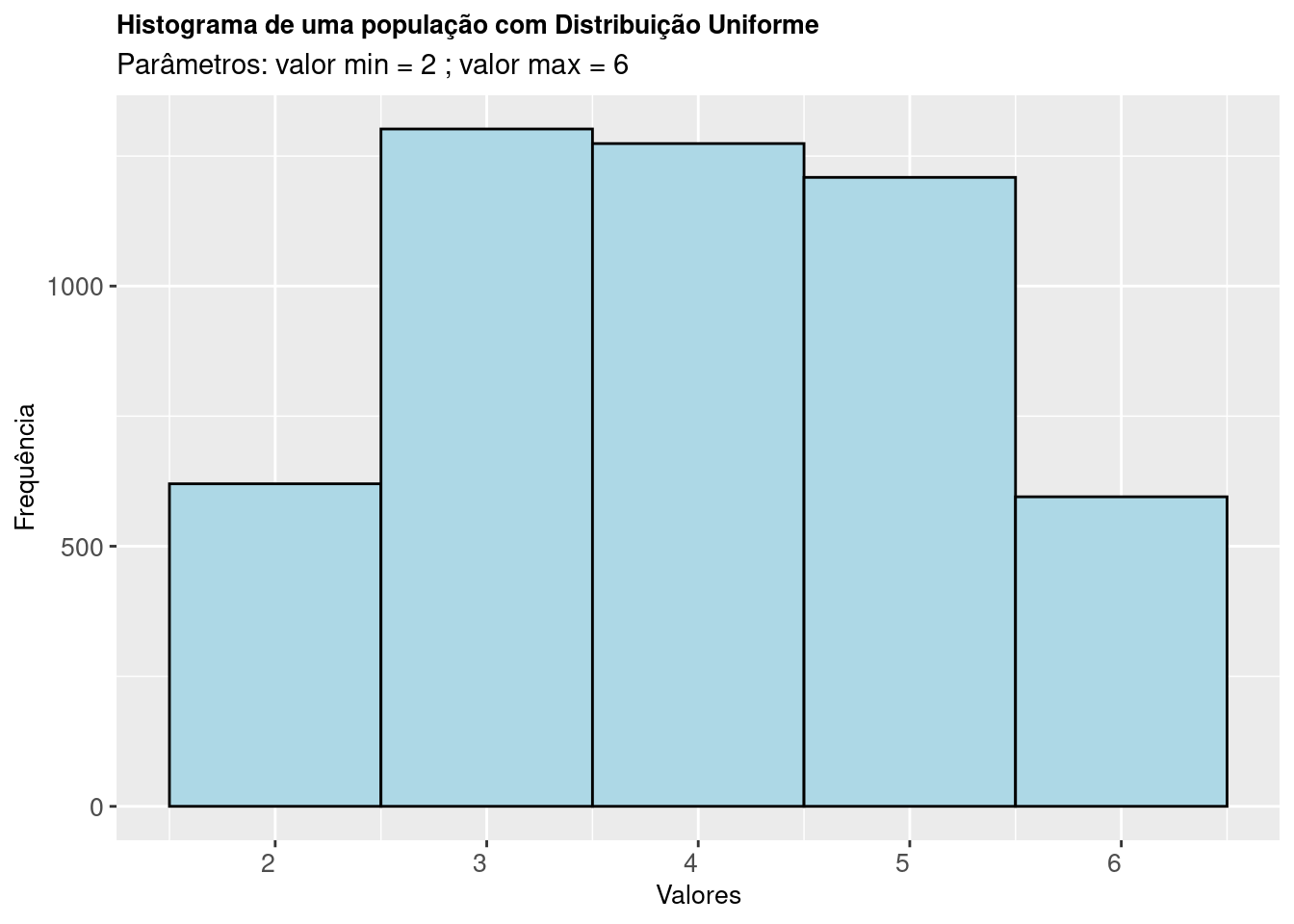
Figure 9.3: Histograma de uma população cuja característica de interesse segue uma Distribuição Uniforme
A Figura 9.3 mostra o histograma de uma amostra de 5000 elementos de uma população com Distribuição Uniforme de parâmetros \(v_{min}:\) 2 e \(v_{max}:\) 6.
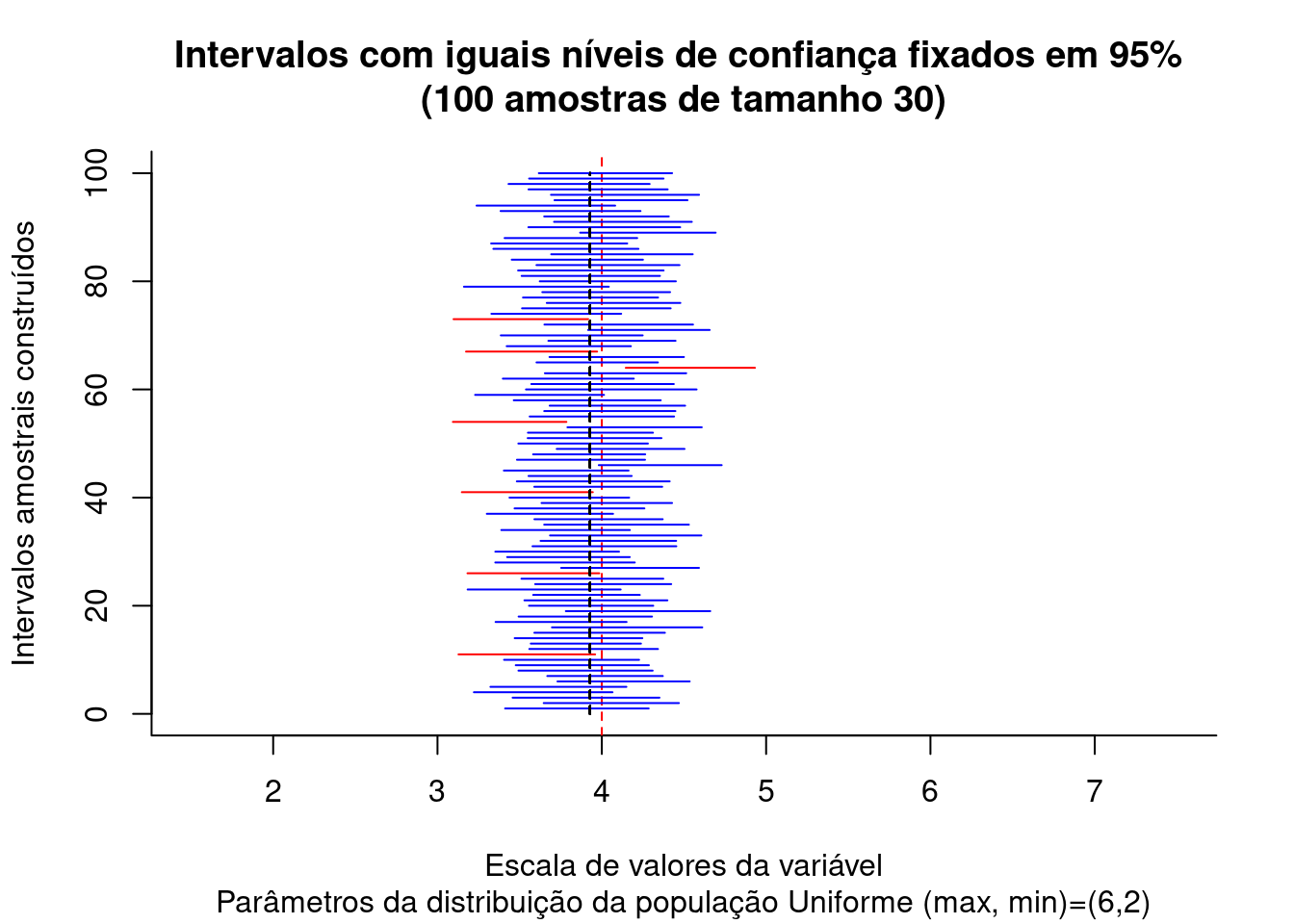
Figure 9.4: Intervalos de confiança construídos para diversas estimativas amostrais de uma população com Distribuição \(\sim N (\mu= \frac{max-min}{2}; \sigma^2=\frac{1}{12}(max-min)^2)\)
A Figura 9.4 expõe os intervalos sob nível de confiança de \((1-\alpha)\)=95% produzidos para as 100 médias de amostras de tamanho 30 extraídas de uma população Uniforme com parâmetros \(v_{max}:\) 6 e \(v_{min}:\) 2 e, conforme assegura o TCL, o valor médio das médias amostrais (linha tracejada preta) converge assintoticamente para a média da população de origem (linha tracejada em vermelho) com o incremento do tamanho das amostras.
meu_titulo1=paste("Distribuição das médias de", N, "amostras de tamanho n=",n,"\n população de origem sob Dist. Unif. (min: ", min_1, "; max: ", max_1, ")")
meu_titulo2=paste("As médias amostrais ~ N( x=",round(mean(m),2),";sd=",round(sd(m),2),")")
dados=as.data.frame(m)
ggplot(dados, aes(m)) +
geom_histogram(aes(y = stat(density)), bins=10, fill="lightblue", col="black") +
geom_area(stat = "function",
fun = dnorm,
args = list(mean=mean(m), sd=sd(m)),
fill = NA,
colour="red") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores das médias amostrais") +
labs(title=meu_titulo1)+
geom_segment(aes(x = mean(m), y = 0, xend = mean(m), yend = max(dnorm(m))), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=mean(m), y=max(dnorm(m)),
label=meu_titulo2, angle=0, vjust=-0.5, hjust=0.5, color="blue",size=6)+
theme(plot.title = element_text(size = 10, face = "bold"),
axis.text.x = element_text(angle=0, hjust=1, size=10),
axis.text.y = element_text(angle=0, hjust=1, size=10),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))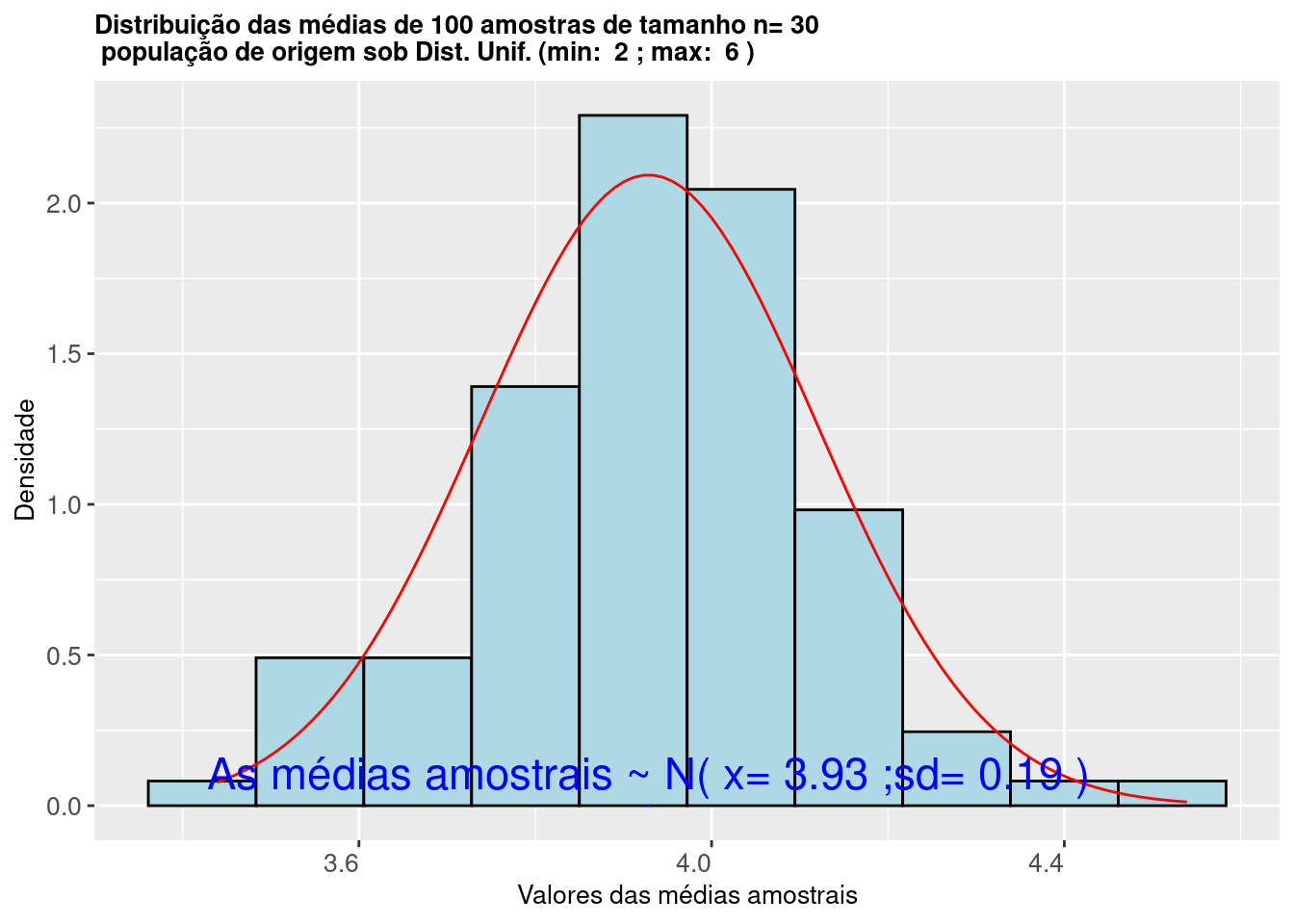
Figure 9.5: Histograma da distribuição das médias de amostras extraidas de uma população com Distribuição Uniforme mostra que as mesmas seguem uma Distribuição \(\sim N (\mu= \frac{max-min}{2};\sigma^2=\frac{1}{12}(max-min)^2)\)
O histograma da Figura 9.5 ilustra que os valores das médias calculadas de 30 amostras extraídas de uma população com distribuição Uniforme \(\sim U (v_{min}, v_{max}\)) seguem uma distribuição Normal \(\sim N (\mu= \frac{v_{max}-v_{min}}{2}; \sigma^2=\frac{1}{12}(v_{max}-v_{min})^2)\).
Demostração usando amostras extraídas de uma população com distribuição \(\sim N (\mu;\sigma)\)
# Definindo os parãmetros e a amostra
media=80
desvio=4
NN=5000
pop_2=rnorm(n=NN, mean = media, sd = desvio)
df=as.data.frame(pop_2)
# A distribuição da população ilustrada em um histograma
ggplot(df, aes(x=pop_2)) +
geom_histogram( binwidth=1,color="black", fill="lightblue")+
scale_y_continuous(name="Frequêcia") +
scale_x_continuous(name="Valores")+
labs(title= paste("Histograma de uma população com Distribuição Normal"),
subtitle = paste("Parâmetros: média =",media,"; desv. padrão =", desvio))+
theme(plot.title = element_text(size = 10, face = "bold"),
axis.text.x = element_text(angle=0, hjust=1, size=10),
axis.text.y = element_text(angle=0, hjust=1, size=10),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))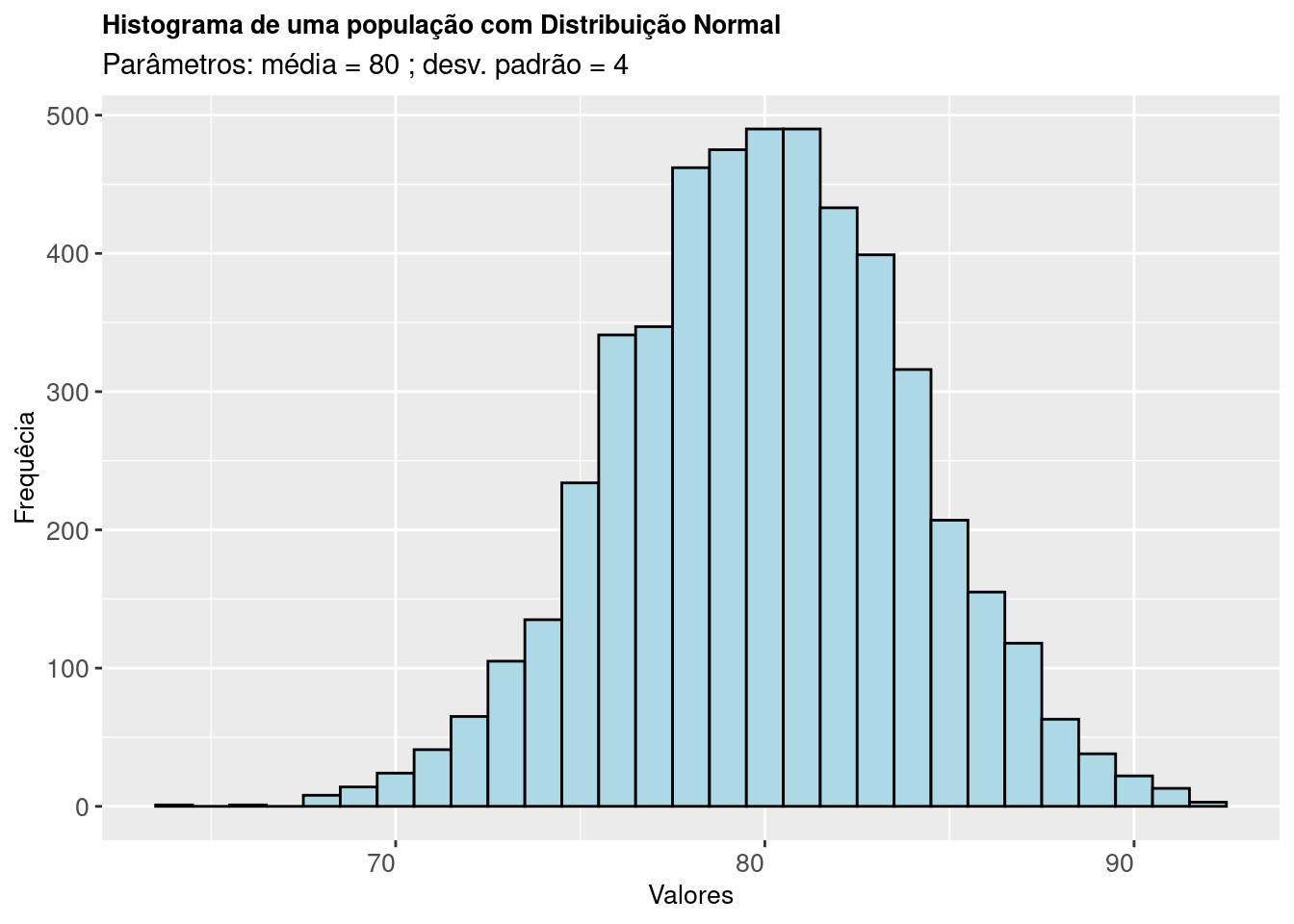
Figure 9.6: Histograma de uma população cuja característica de interesse segue uma Distribuição Normal
A Figura 9.6 mostra o histograma de uma amostra de 5000 elementos de uma população com Distribuição Normal de parâmetros média= 80 e desvio padrão =4.
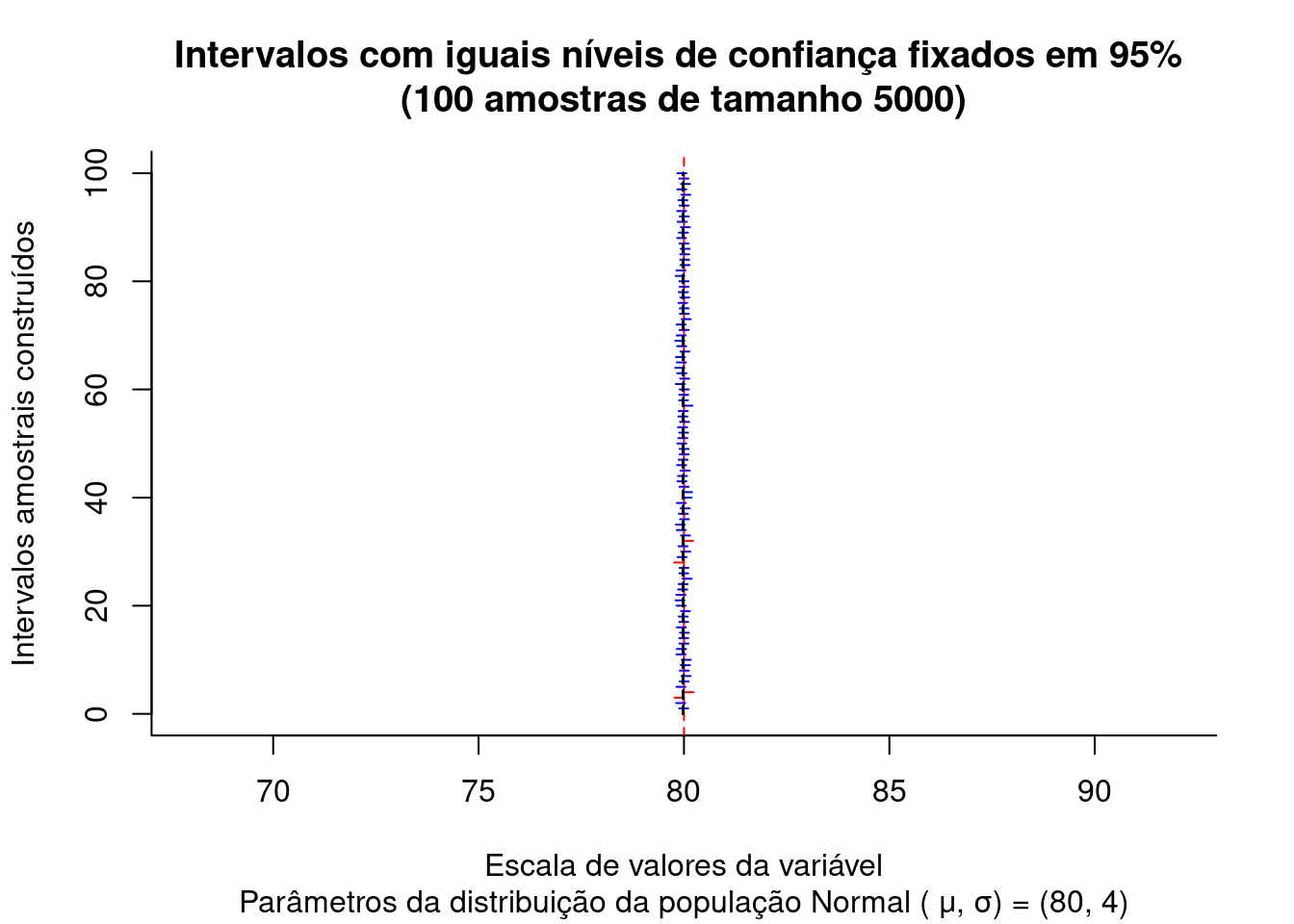
Figure 9.7: Intervalos de confiança construídos para diversas estimativas amostrais de uma população com Distribuição \(\sim N (\mu; \sigma)\)
A Figura 9.7 expõe os intervalos sob nível de confiança de \((1-\alpha)\)=95% produzidos para as 100 médias de amostras de tamanho 5000 extraídas de uma população Uniforme com parâmetros \(v_{max}:\) 6 e \(v_{min}:\) 2 e, conforme assegura o TCL, o valor médio das médias amostrais (linha tracejada preta) converge assintoticamente para a média da população de origem (linha tracejada em vermelho) com o incremento do tamanho das amostras.
meu_titulo1=paste("Distribuição das médias de", N, "amostras de tamanho n=",n,"\n população de origem sob Dist. Normal ( \u03bc: ", media, ", \u03c3: ", desvio, ")")
meu_titulo2=paste("As médias amostrais ~ N( x\u0304=",round(mean(m),2),";sd=",round(sd(m),2),")")
dados=as.data.frame(m)
ggplot(dados, aes(m)) +
geom_histogram(aes(y = stat(density)), bins=10, fill="lightblue", col="black") +
geom_area(stat = "function",
fun = dnorm,
args = list(mean=mean(m), sd=sd(m)),
fill = NA,
colour="red") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores das médias amostrais") +
labs(title=meu_titulo1)+
geom_segment(aes(x = mean(m), y = 0, xend = mean(m), yend = max(dnorm(m))), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=mean(m), y=max(dnorm(m)),
label=meu_titulo2, angle=0, vjust=-0.5, hjust=0.5, color="blue",size=6)+
theme(plot.title = element_text(size = 10, face = "bold"),
axis.text.x = element_text(angle=0, hjust=1, size=10),
axis.text.y = element_text(angle=0, hjust=1, size=10),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))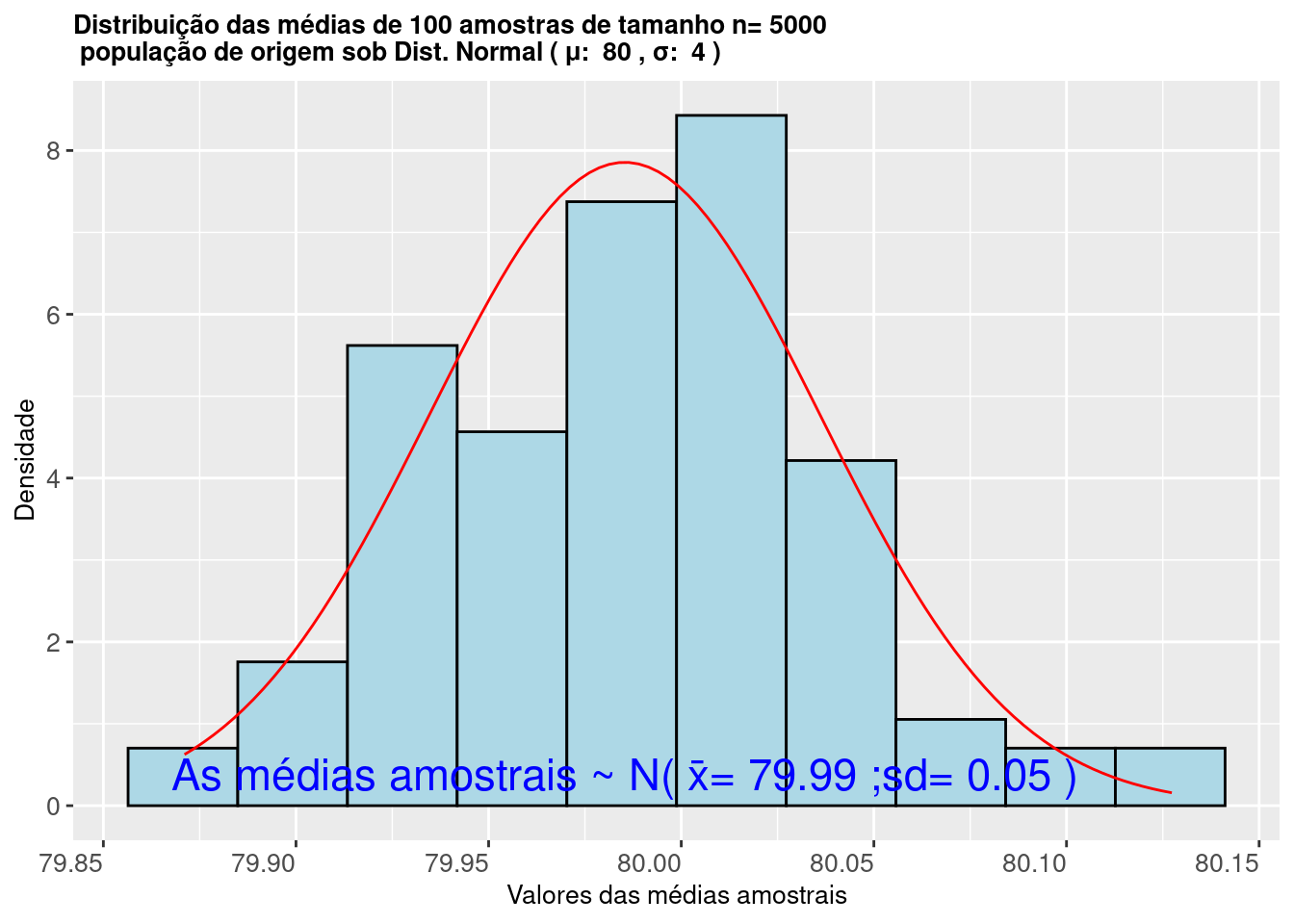
Figure 9.8: Histograma da distribuição das médias de amostras extraidas de uma população Normal mostra que as mesmas seguem uma Distribuição \(\sim N (\stackrel{-}{x}= \mu; s=\frac{\sigma}{\sqrt{n}})\)
O histograma da Figura 9.8 ilustra que os valores das médias calculadas de 5000 amostras extraídas de uma população com distribuição Normal \(\sim N (\mu, \sigma)\) seguem uma distribuição Normal \(\sim N (\mu= \mu; \sigma=\frac{\sigma}{\sqrt{n}})\).
Sendo o erro amostral expresso como: \(\varepsilon=\stackrel{-}{X} - \mu\), o histograma abaixo ilustra que os valores dos erros calculados de 5000 amostras extraídas de uma população com distribuição Normal \(\sim N (\mu, \sigma)\) seguem uma distribuição Normal \(\sim N (\mu= \mu; \sigma=\frac{\sigma}{\sqrt{n}})\).
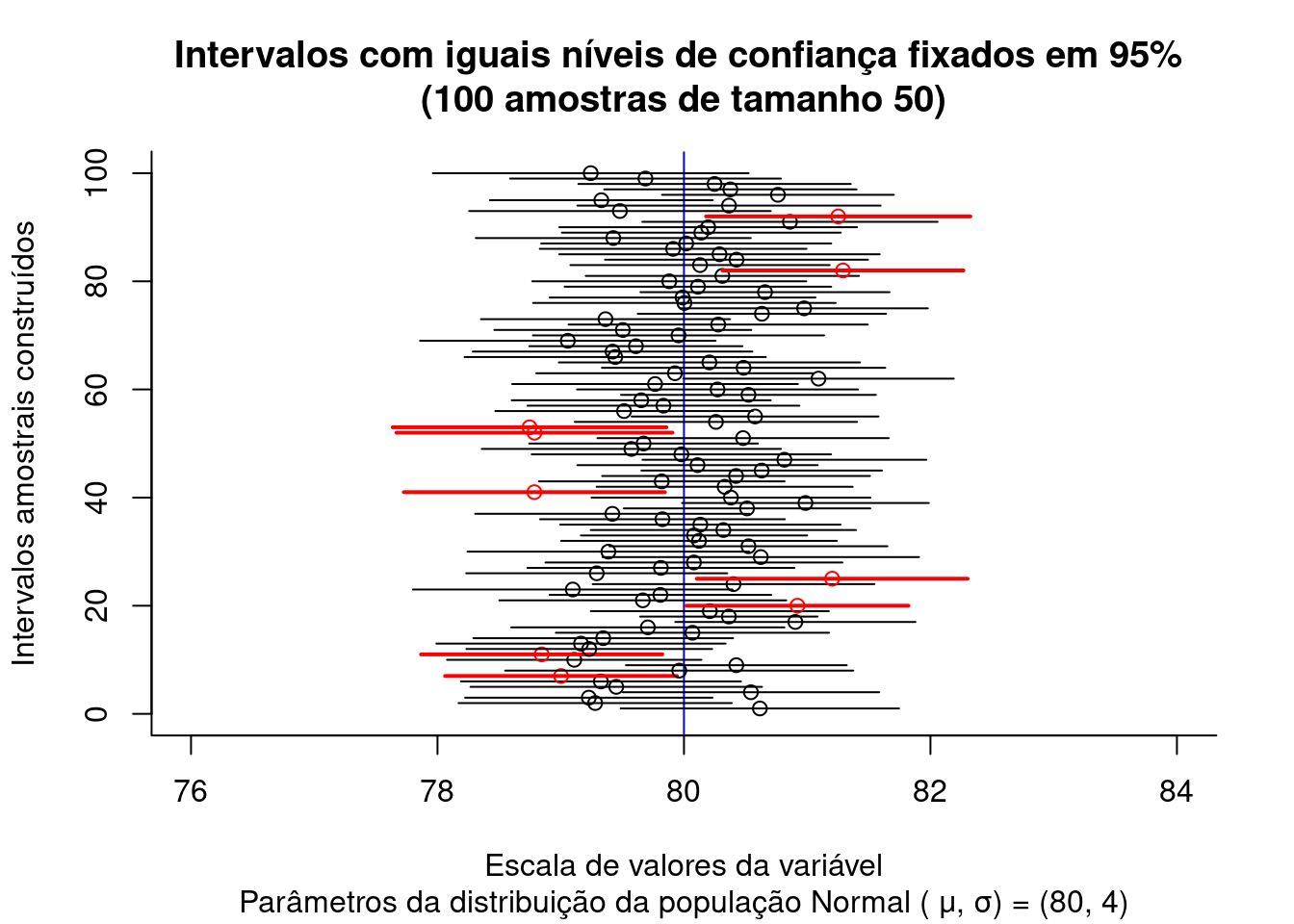
Figure 9.9: Histograma da distribuição dos erros de amostras de tamanho n, extraidas de uma população com distribuição \(\sim N(\mu; \sigma)\) mostra que os mesmos seguem uma distribuição \(\sim N (0; s=\frac{\sigma}{\sqrt{n}})\)
erro_min=min(matriz$erro)
erro_max=max(matriz$erro)
meu_titulo1=paste("Distribuição dos erros de", N, "amostras de tamanho n=",n,"\n extraídas de uma população Normal ( \u03bc: ", mu, ", \u03c3: ", sigma, ")")
meu_titulo2=paste("Os erros amostrais ~ N( x\u0304=",round(mean(matriz$erro),2),"~0 ; sd=",round(sd(matriz$erro),2)," ~\u03c3/sqrt(n))")
ggplot(matriz, aes(x=erro)) +
geom_histogram(aes(y = stat(density)), bins=round(sqrt(N),0), fill="lightblue", col="black") +
geom_area(stat = "function",
fun = dnorm,
args = list(mean=mean(matriz$erro), sd=sd(matriz$erro)),
fill = NA,
colour="red") +
scale_y_continuous(name="Frequência") +
scale_x_continuous(name="Valores dos erros amostrais", limits=c(-2,2) )+
labs(title=meu_titulo1)+
annotate(geom="text",
label=meu_titulo2, x=-0.7,y= 0.9,
angle=0, vjust=-0.5, hjust=0.5,
color="blue",size=4)+
theme(plot.title = element_text(size = 10, face = "bold"),
axis.text.x = element_text(angle=0, hjust=1, size=10),
axis.text.y = element_text(angle=0, hjust=1, size=10),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))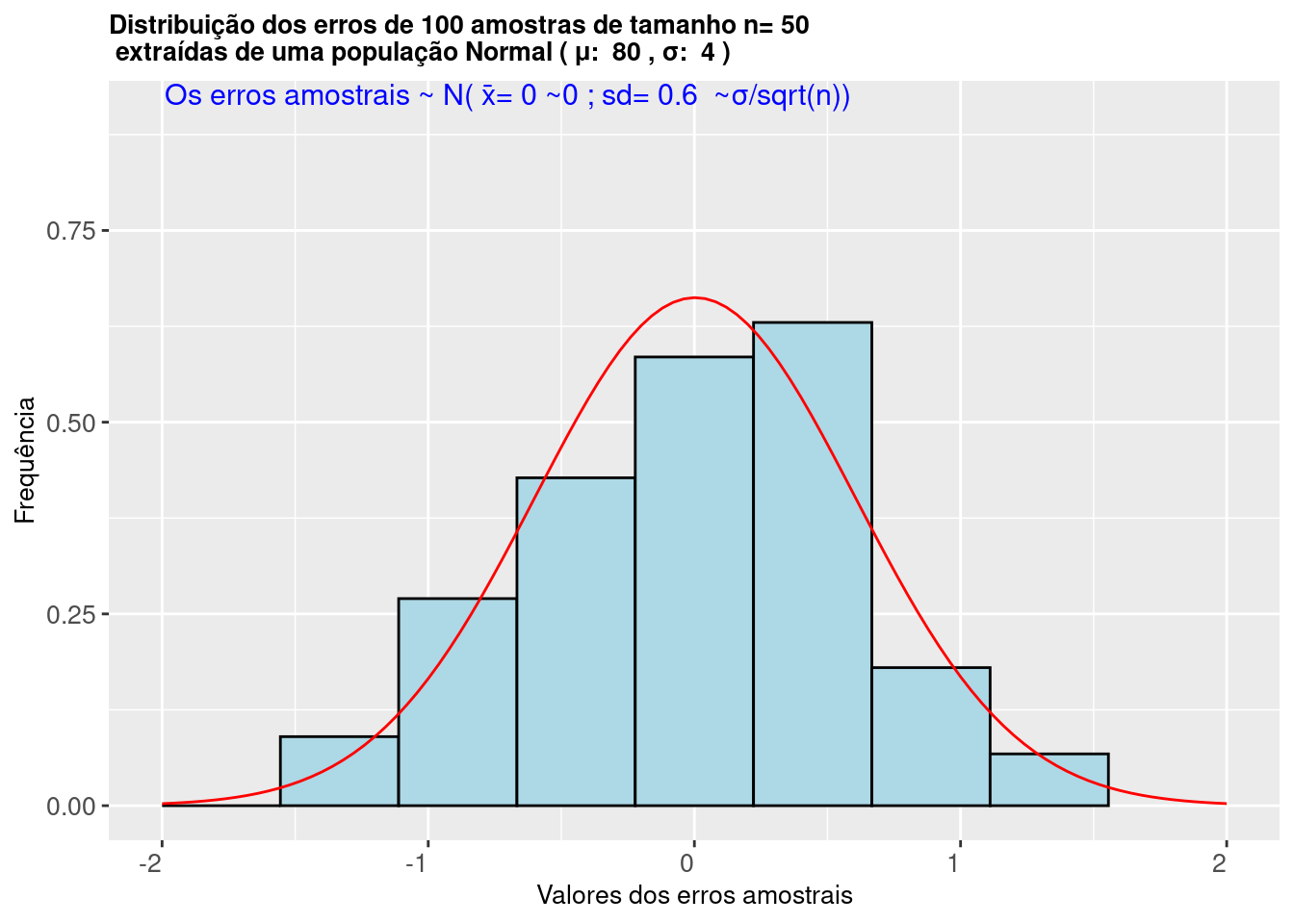
Figure 9.10: Histograma da distribuição dos erros de amostras de tamanho n, extraidas de uma população com distribuição \(\sim N(\mu; \sigma)\) mostra que os mesmos seguem uma distribuição \(\sim N (0; s=\frac{\sigma}{\sqrt{n}})\)
Corolário: se \((X_{1}, X_{2},...,X{n})\) for uma amostra aleatória simples da população \(X\) de média \(\mu\) e variância \(\sigma^{2}\) conhecida, e \(\stackrel{-}{X}= \frac{(X_{1}+X_{2}+...+X{n})}{n}\), tal que \(n\ge 30\), então a estatística \(Z\) pode ser definida, bem como sua correspondente distribuição:
\[ Z = \frac{\stackrel{-}{X} - \mu}{\frac{\sigma}{\sqrt{n}}} \sim N(0 ,1) \]
Uma vez que a estatística \(Z \sim N(0 ,1)\) (ela ``decorre’’ da padronização da variável aleatória \(\stackrel{-}{X}\)) as probabilidades para os intervalos desejados de valores \(Z\) podem ser facilmente encontrados em tabelas, como mais adiante se verá na constução de intervalos de confiança.
9.3.1 Fator de correção para populações finitas
Se amostras de tamanho \(n\) sem reposição são extraídas de uma população finita de tamanho N aplica-se o fator de correção para populações finitas (\(\sqrt{\frac{(N-n)}{(N-1)}}\)) junto ao desvio padrão das expressões do erro máximo \(\varepsilon\) anteriormente expostas:
\[\begin{align*} \varepsilon & =(\stackrel{-}{x}-\mu)={z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}} \cdot \sqrt{\frac{(N-n)}{(N-1)}} \\ & =(\stackrel{-}{x}-\mu)={z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}} \cdot \sqrt{\frac{(N-n)}{(N-1)}}\\ & =(\stackrel{-}{x}-\mu)= ({t}_{(1-\frac{\alpha }{2}, (n-1))} \cdot \frac{S}{\sqrt{n}} \cdot \sqrt{\frac{(N-n)}{(N-1)}})\\ \end{align*}\]
Portanto, para populações finitas com amostragem sem reposição (com \(n<N\)):
\[ \stackrel{-}{X} \sim N(\mu, \frac{\sigma^{2}}{n} \cdot \frac{(N-n)}{(N-1)} ) \]
9.3.2 Intervalo de confiança para a média de uma população Normal
Se, por alguma razão, a variância populacional (\(\sigma^{2}\)) é conhecida, podemos utilizar \(\stackrel{-}{X}\) como estimador pontual da média.
Assim, \(X\) seguirá uma distribuição Normal tal que:
\[ \stackrel{-}{X} \sim N(\mu, \frac{\sigma^{2}}{n}) \]
Segue também que a estatística \(Z\), como antes definida, seguirá uma distribuição Normal tal que:
\[ Z = \frac{\stackrel{-}{X} - \mu}{\frac{\sigma}{\sqrt{n}}} \sim N(0 ,1) \] com:
- \(\stackrel{-}{X}\) é uma média amostral;
- \(\mu\) é a média populacional;
- \(\sigma\) é o desvio padrão populacional; e,
- \(n\) é o tamanho da amostra extraída.
Entretanto, a situação mais usual é aquela na qual não termos informação alguma sobre a variância populacional (\(\sigma^{2}\)).
Nessas situações, se o tamanho da amostra é grande (na prática \(n\ge 30\)), podemos substituir \(\sigma\) na estatística \(Z\) por \(S\): substituir o desvio padrão populacional pelo desvio padrão da amostra extraída, sem que o erro cometido com esta substituição seja grande.
Com tal substituição, a estatística \(Z\) e passa a ser tal que:
\[ Z = \frac{\stackrel{-}{X} - \mu}{\frac{S}{\sqrt{n}}} \sim N(0 , 1) \]
em que:
- \(\stackrel{-}{X}\) é uma média amostral;
- \(\mu\) é a média populacional;
- \(S\) é o desvio padrão da amostra; e,
- \(n\) é o tamanho da amostra.
Caso a variância populacional (\(\sigma^{2}\)) não seja conhecida e o tamanho da amostra não possa ser admitido como grande (\(n<30\)) e sendo o estimador da variância amostral assim definido:
\[ {S}^{2}=\frac{1}{\left(n-1\right)}\sum _{i=1}^{n}{\left({X}_{i}-\stackrel{-}{{X}_{1}}\right)}^{2} \]
Definindo-se a variável \(Y = \frac{(n-1)\cdot s^{2}}{\sigma^{2}}\) tem uma distribuição \(\chi^{2}\) com (n-1) graus de liberdade tal que:
\[ Y = \frac{(n-1)\cdot s^{2}}{\sigma^{2}} \sim \chi^{2}_{(n-1)}, \]
e considerando-se que \(Z\) é tal que:
\[ Z = \frac{\stackrel{-}{X} - \mu}{\frac{\sigma}{\sqrt{n}}} \sim N(0 ,1) \]
segue a estatística \(T\) e sua correspondente distribuição, denominada por t de Student :
\[
T=\frac{Z}{\sqrt{\frac{Y}{\left(n-1\right)}}} \sim {t}_{\left(n-1\right)}.
\]
Para essa situação na qual a variância populacional não é conhecida e o tamanho amostral é pequeno, com alguma manipulação chega-se à estatística \(T\) e sua correspondente distribuição:
\[ T = \frac{(\stackrel{-}{X} - \mu)}{ \frac{S}{\sqrt{n}} } \sim t_{(n-1)} \]
em que:
- \(\stackrel{-}{X}\) é uma média amostral;
- \(\mu\) é a média populacional;
- \(S\) é o desvio padrão da amostra; e,
- \(n\) é o tamanho da amostra; e,
- \((n-1)\) é uma quantidade denominada como graus de liberdade.
As probabilidades associadas a um intervalo para um determinado valor da estatística ``t’’ da distribuição de Student encontram-se tabeladas para variados graus de liberdade , como mais adiante se verá na constução de intervalos de confiança.
9.3.3 Intervalos de confiança para a média de uma população Normal com variância conhecida (Figura 6.9)
\[ Z = \frac{\stackrel{-}{X} - \mu}{\frac{\sigma}{\sqrt{n}}} \sim N(0 ,1) \]
em que:
- \(\stackrel{-}{X}\) é uma média amostral;
- \(\mu\) é a média populacional;
- \(\sigma\) é o desvio padrão populacional;
- \(n\) é o tamanho da amostra; e,
- \(Z\) é a estatística a ser calculada para a construção do intervalo de confiança sob o nível de significância \(\alpha\) estabelecido.
alfa=0.05
prob_desejada1=alfa/2
z_desejado1=round(qnorm(prob_desejada1),4)
d_desejada1=dnorm(z_desejado1, 0, 1)
prob_desejada2=1-alfa/2
z_desejado2=round(qnorm(prob_desejada2),4)
d_desejada2=dnorm(z_desejado2, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(-4, z_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(z_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(0, z_desejado2),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(z_desejado2,4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
labs(title=
"Curva da função densidade \nDistribuição Normal Padrão",
subtitle = "P(-z, z)=(1-\u03b1) em cinza (nível de confiança) \nP(-\U221e; -z)= P(z; \U221e)= \u03b1/2 em vermelho ")+
geom_segment(aes(x = z_desejado1, y = 0, xend = z_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
geom_segment(aes(x = z_desejado2, y = 0, xend = z_desejado2, yend = d_desejada2), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=z_desejado1-0.1, y=d_desejada1, label="-z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado2+0.3, y=d_desejada2, label="z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1-1.8, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado2+0.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo fechado \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()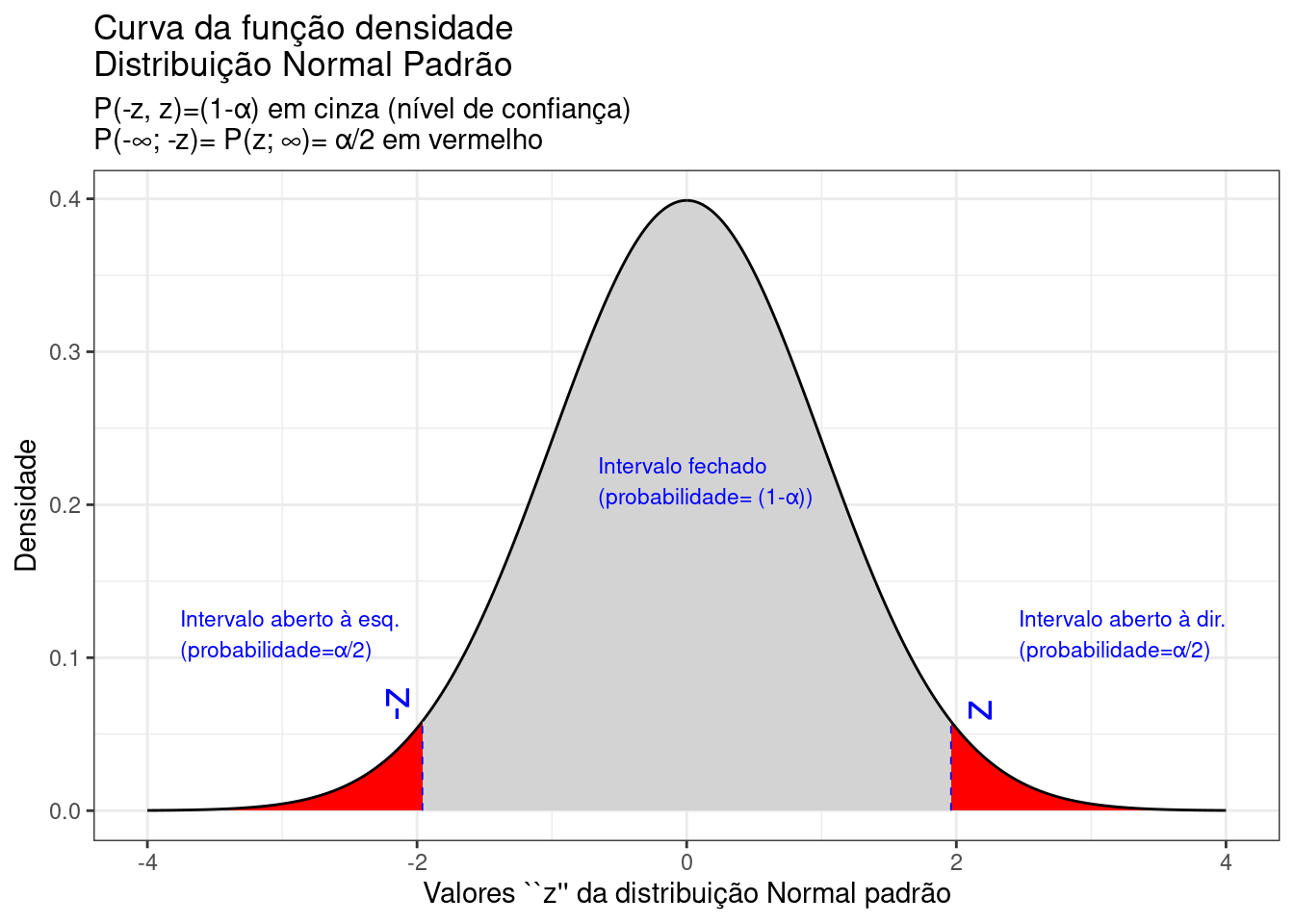
Figure 9.11: Regiões críticas, aquém e além das quais, a probabilidade associada aos valores \(Z\) é inferior a \(\frac{\alpha}{2}\), estabelecendo assim um intervalo com nível de confiança igual a \((1-\alpha)\)
Na Figura 9.11 observa-se:
- o nível de significância \(\alpha\);
- o nível de confiança \((1-\alpha)\); e,
- o valor tabelado da estatística \(Z\) para o nível de confiança fixado.
Assim,
\[\begin{align*} P\left[-{Z}_{(1-\frac{\alpha }{2})}\le Z \le {Z }_{(1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P\left[-{z}_{(1-\frac{\alpha }{2})}\le \frac{\stackrel{-}{x}-\mu }{\frac{\sigma}{\sqrt{n}}} \le {z}_{(1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P[\stackrel{-}{x}-({z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}}) \le \mu \le \stackrel{-}{x}+({z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}}) ] & = (1-\alpha) \end{align*}\]
\[ IC(\mu)_{(1-\alpha)} = [\stackrel{-}{x} \pm {z}_{c} \cdot \frac{\sigma}{\sqrt{n}}] \]
Assim, se \(\stackrel{-}{x}\) é usado como estimativa de \(\mu\), podemos afirmar estar \(100.(1-\alpha)\)% confiantes de que o erro não excederá \(({z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}})\).
A quantidade \(\varepsilon=(\stackrel{-}{x}-\mu)={z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}}\) é chamada de Erro máximo da estimativa ao se arbitrar um nível de confiança \(\alpha\) para um determinado tamanho amostral.
Exemplo: As vendas de 15 lojas de uma região do país apresentam uma média igual a US$ 20.000,00. Sabendo-se que as vendas de todas as lojas da região é uma variável aleatória que segue uma distribuição Normal, com desvio padrão igual a US$ 8.300,00, construa o intervalo de confiança para a média ao nível de confiança de 95%.
Dados do problema:
- o tamanho da amostra: \(n=15\);
- a média amostral: \(\stackrel{-}{x}\) = US$ 20.000;
- o desvio padrão populacional: \(\sigma\)= US$ 8.300;
- nível de confiança: \((1-\alpha) = 0,95\); e,
- valor extraído da tabela \(z=1,96\) correspondente ao nível de confiança estipulado \((1-\alpha)=95\%\).
\[\begin{align*} P[\stackrel{-}{x}-({z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}}) \le \mu \le \stackrel{-}{x}+({z}_{(1-\frac{\alpha }{2})} \cdot \frac{\sigma}{\sqrt{n}}) ] & = (1-\alpha) \\ P[20.000 - (1,96 \cdot \frac{8.300}{\sqrt{15}}) \le \mu \le 20000 + ( 1,96 \cdot \frac{8.300}{\sqrt{15}}) ] & = 0,95 \\ P[20.000 - 4.200,38 \le \mu \le 20.000 + 4.200,38 ] & = 0,95 \\ \end{align*}\]
\[ IC_{(1-\alpha=0,95)} = [US\$ 15.799,62; US\$ 24.200,38] \]
Se quisermos ser rigorosos na interpretação do intervalo de confiança calculado podemos explicar que, se extrairmos um grande número de amostras de tamanho 15 dessa população, e para todas elas calcularmos intervalos de confiança como o acima definido, a proporção desses intervalos onde poderemos encontrar a média populacional de vendas será de 0,95 (95 intervalos em 100).
De uma forma mais sintética, podemos afirmar que o intervalo aleatório ]US$ 15.799,62; US$ 24.200,38[, é um intervalo de confiança a 95% para a média de vendas.
De forma mais corrente, embora menos correta em termos teóricos, é usual afirmar que, com 95% de confiança a média de vendas se situa entre os valores US$ 15.799,62 e US$ 24.200,38.
Intervalos de confiança unilaterais para uma média amostral sob variância populacional conhecida.
A Figura 6.10 ilustra um intervalo de confiança unilateral limitado à direita por um valor máximo, dde tal sorte que a probabilidade associada ao intervalo de valores da estatística \(Z\) inferiores a esse limitante é
\[ P\left [\mu \le \bar{x} + {z}_{c} \cdot \frac{\sigma}{\sqrt{n}} \right ] = (1- \alpha) \]
prob_desejada=0.95
z_desejado=round(qnorm(prob_desejada),4)
d_desejada=dnorm(z_desejado, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(-4, 0),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(0, z_desejado),
colour="black")+
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c( z_desejado, 4),
colour="black")+
labs(title=
"Curva da função densidade
\nDistribuição Normal Padrão",
subtitle = "P(-\U221e; z)=(1-\u03b1) em cinza (nível de confiança) \nP(z, + \U221e)= \u03b1, em vermelho ")+
annotate(geom="text", x=z_desejado1+3.5, y=d_desejada1, label="z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1+4.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo aberto à esq. \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()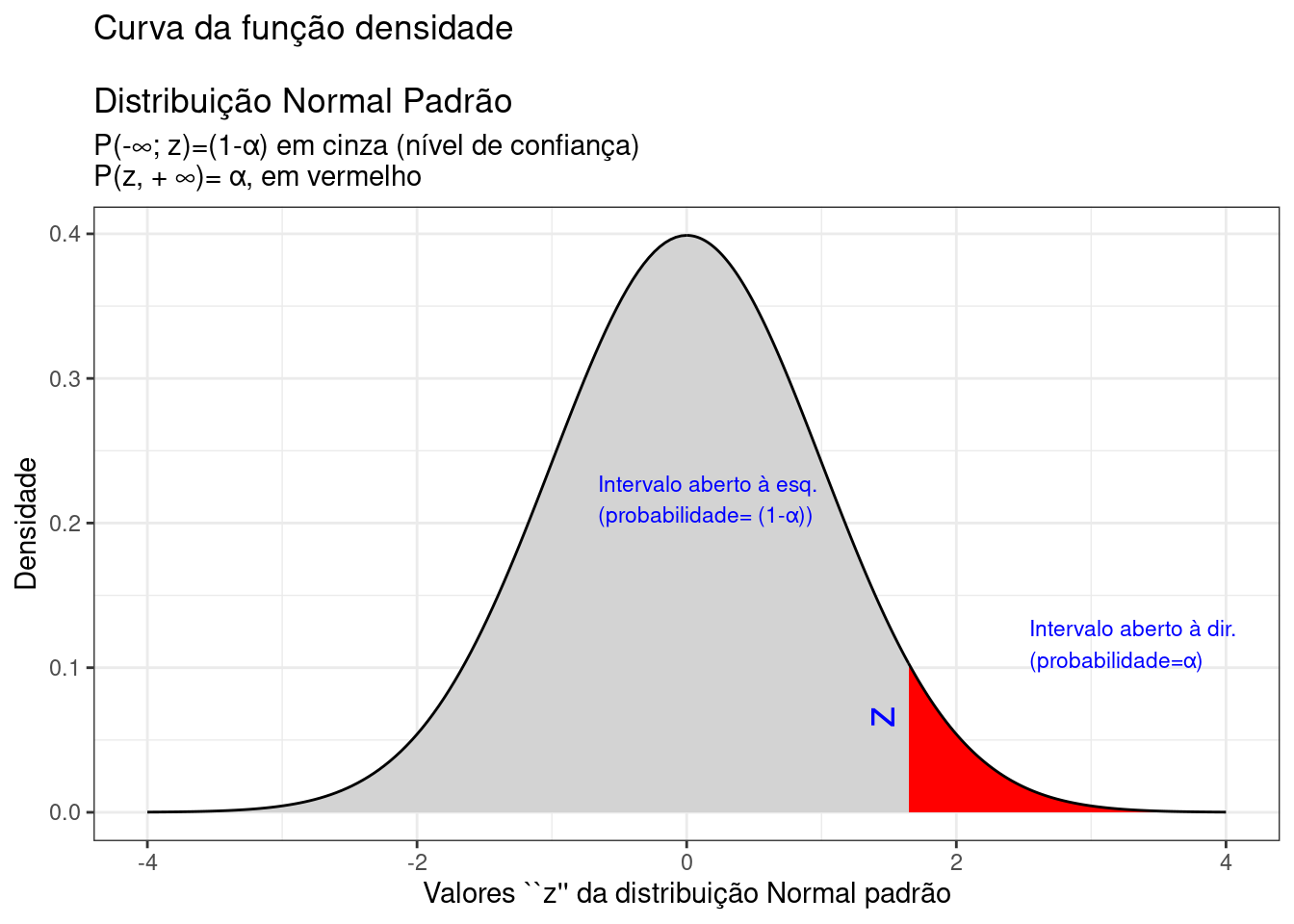
Figure 9.12: Região crítica, além da qual, a probabilidade associada aos valores \(Z\) é inferior a \(\alpha\), delimitando assim, à esquerda, um intervalo aberto com nível de confiança igual a \((1-\alpha)\)
A Figura 9.13 ilustra um intervalo de confiança unilateral limitado à esquerda por um valor mínimo, de tal sorte que a probabilidade associada ao intervalo de valores da estatística \(Z\) superiores a esse limitante é
\[ P\left [\mu \ge \bar{x} - {z}_{c} \cdot \frac{\sigma}{\sqrt{n}} \right ] = (1- \alpha) \]
prob_desejada=0.05
z_desejado=round(qnorm(prob_desejada),4)
d_desejada=dnorm(z_desejado, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(-4, 0),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(-4, z_desejado),
colour="black")+
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c( z_desejado, 4),
colour="black")+
labs(title=
"Curva da função densidade
\nDistribuição Normal Padrão",
subtitle = "P(-\U221e; z)=\u03b1, em vermelho \nP(z, + \U221e)= (1-\u03b1) em cinza")+
annotate(geom="text", x=z_desejado1+0.5, y=d_desejada1, label="-z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1-2, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo aberto à dir. \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()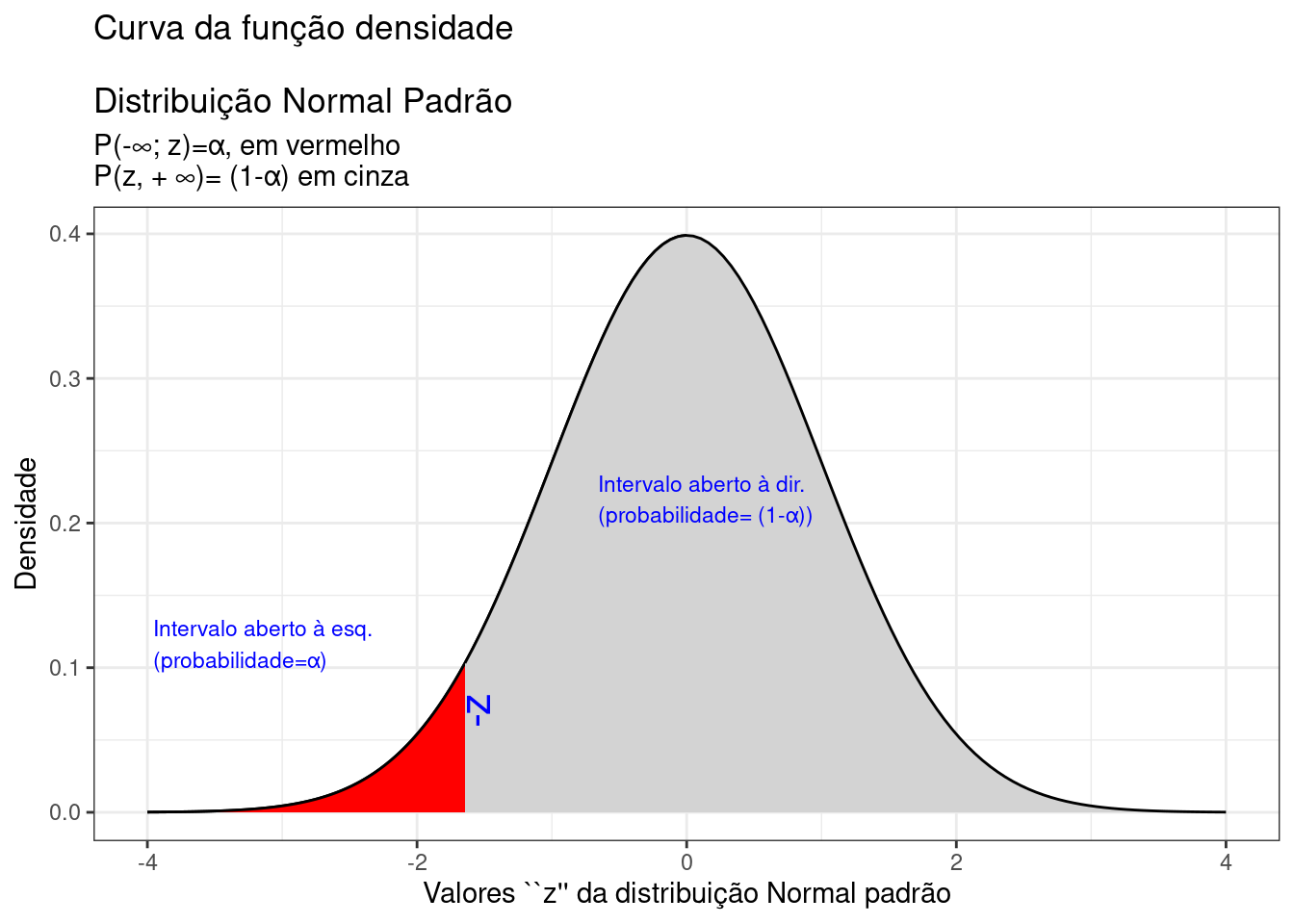
Figure 9.13: Região crítica, aquém da qual, a probabilidade associada aos valores \(Z\) é inferior a \(\alpha\), delimitando assim, à direita, um intervalo aberto com nível de confiança igual a \((1-\alpha)\)
9.3.4 Intervalos de confiança para a média de uma população Normal de variância desconhecida mas amostra não tão pequena: \(n \ge 30\) (Figura 9.14)
\[ Z = \frac{\stackrel{-}{X} - \mu}{\frac{S}{\sqrt{n}}} \sim N(0 , 1) \]
em que:
- \(\stackrel{-}{X}\) é uma média amostral;
- \(\mu\) é a média populacional;
- \(S\) é o desvio padrão amostral;
- \(n\) é o tamanho da amostra; e,
- \(Z\) é a estatística a ser calculada para a construção do intervalo de confiança sob o nível de significância \(\alpha\) estabelecido.
alfa=0.05
prob_desejada1=alfa/2
z_desejado1=round(qnorm(prob_desejada1),4)
d_desejada1=dnorm(z_desejado1, 0, 1)
prob_desejada2=1-alfa/2
z_desejado2=round(qnorm(prob_desejada2),4)
d_desejada2=dnorm(z_desejado2, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(-4, z_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(z_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(0, z_desejado2),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(z_desejado2,4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
labs(title=
"Curva da função densidade \nDistribuição Normal Padrão",
subtitle = "P(-z; z)=(1-\u03b1) em cinza (nível de confiança) \nP(-\U221e; -z)= P(z; \U221e)= \u03b1/2 em vermelho")+
geom_segment(aes(x = z_desejado1, y = 0, xend = z_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
geom_segment(aes(x = z_desejado2, y = 0, xend = z_desejado2, yend = d_desejada2), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=z_desejado1-0.1, y=d_desejada1, label="-z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado2+0.3, y=d_desejada2, label="z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1-1.8, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado2+0.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo fechado \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()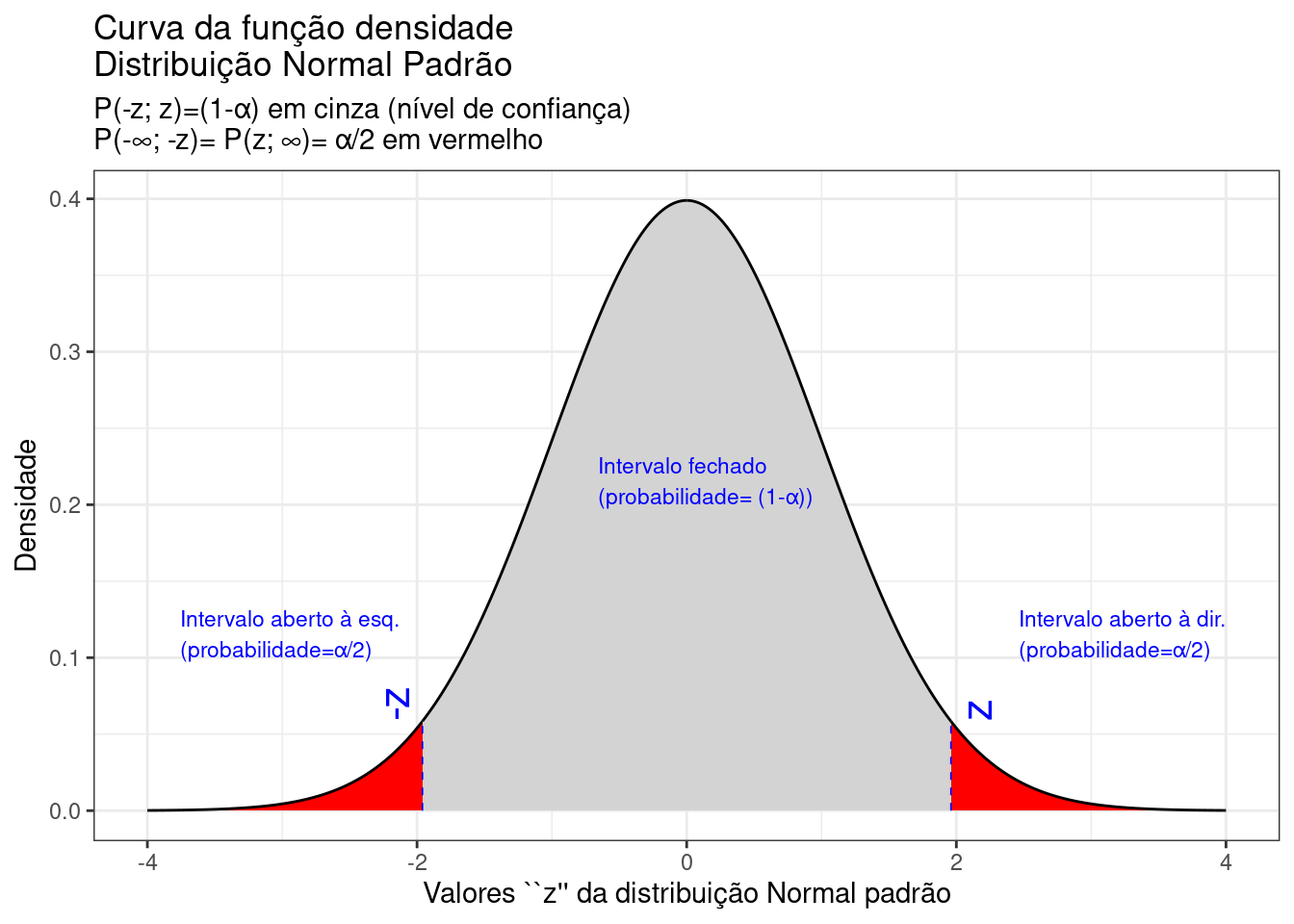
Figure 9.14: Regiões críticas, aquém e além das quais, a probabilidade associada aos valores \(Z\) é inferior a \(\frac{\alpha}{2}\), estabelecendo assim um intervalo com nível de confiança igual a \((1-\alpha)\)
Na Figura 9.14 observa-se:
- o nível de significância \(\alpha\);
- o nível de confiança \((1-\alpha)\); e,
- o valor tabelado da estatística \(Z(z)\) para o nível de confiança fixado.
Assim,
\[\begin{align*} P\left[-{Z}_{(1-\frac{\alpha }{2})}\le Z \le {Z }_{(1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P\left[-{z}_{(1-\frac{\alpha }{2})}\le \frac{\stackrel{-}{x}-\mu }{(\frac{S}{\sqrt{n})}} \le {z}_{(1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P[\stackrel{-}{x}-({z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}) \le \mu \le \stackrel{-}{x}+({z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}) ] & = (1-\alpha) \end{align*}\]
\[ IC(\mu)_{(1-\alpha)} = [\stackrel{-}{x} \pm {z}_{c} \cdot \frac{S}{\sqrt{n}} ] \]
Assim, se \(\stackrel{-}{x}\) é usado como estimativa de \(\mu\) podemos afirmar estar \(100(1-\alpha)\)% confiantes de que o erro não excederá \(({z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}})\).
A quantidade \(\varepsilon=(\stackrel{-}{x}-\mu)={z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}\) é chamada de Erro máximo da estimativa ao se arbitrar um nível de confiança \(\alpha\) para um determinado tamanho amostral.
Exemplo: As vendas de 60 lojas de uma região do país apresentam uma média igual a US$ 20.000,00 e desvio padrão de US$ 8.300,00. Construa o intervalo de confiança para a média ao nível de confiança de 95%.
Dados do problema:
- o tamanho da amostra: \(n=60\);
- a média amostral: \(\stackrel{-}{x}=US\$ 20.000\);
- o desvio padrão amostral: \(s=US\$ 8.300\);
- nível de confiança: \((1-\alpha)=0,95\); e,
- valor extraído da tabela \(z=1,96\) correspondente ao nível de confiança estipulado \((1-\alpha)=95\%\).
\[\begin{align*} P[\stackrel{-}{x}-({z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}) \le \mu \le \stackrel{-}{x}+({z}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}) ] & = (1-\alpha) \\ P[20.000 - (1,96 \cdot \frac{8.300}{\sqrt{60}}) \le \mu \le 20.000 + ( 1,96 \cdot \frac{8.300}{\sqrt{60}}) ] & = 0,95 \\ P[20.000 - 2.100,19 \le \mu \le 20.000 + 2.100,19 ] & = 0,95 \end{align*}\]
\[ IC_{(1-\alpha=0,95)} = [US\$ 17.899,81;US\$ 22.100,19] \]
Se quisermos ser rigorosos na interpretação do intervalo de confiança calculado podemos explicar que se extrairmos um grande número de amostras de tamanho 60 dessa população, e para todas elas calcularmos intervalos de confiança como o acima definido, a proporção desses intervalos onde poderemos encontrar a média populacional de vendas será de 0,95 (95 intervalos em 100).
De uma forma mais sintética, podemos afirmar que o intervalo aleatório ]US$ 17.899,81; US$ 22.100,19[, é um intervalo de confiança a 95% para a média de vendas.
De forma mais corrente, embora menos correta em termos teóricos, é usual afirmar que, com 95% de confiança a média de vendas se situa entre os valores US$ 17.899,81 e US$ 22.100,19.
Intervalos de confiança unilaterais para a média sob variância populacional desconhecida mas amostras não tão pequenas: \(n \ge 30\).
A Figura 9.15 ilustra um intervalo de confiança unilateral limitado à direita por um valor máximo, de tal sorte que a probabilidade associada ao intervalo de valores da estatística \(Z\) inferiores a esse limitante é
\[ P\left [\mu \le \bar{x} + {z}_{c} \cdot \frac{S}{\sqrt{n}} \right ] = (1- \alpha) \]
prob_desejada=0.95
z_desejado=round(qnorm(prob_desejada),4)
d_desejada=dnorm(z_desejado, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(-4, 0),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(0, z_desejado),
colour="black")+
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c( z_desejado, 4),
colour="black")+
labs(title=
"Curva da função densidade
\nDistribuição Normal Padrão",
subtitle = "P(-\U221e; z)=(1-\u03b1) em cinza (nível de confiança) \nP(z, + \U221e)= \u03b1, em vermelho ")+
annotate(geom="text", x=z_desejado1+3.5, y=d_desejada1, label="z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1+4.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo aberto à esq. \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()
Figure 9.15: Região crítica, além da qual, a probabilidade associada aos valores \(Z\) é inferior a \(\alpha\), delimitando assim, à esquerda, um intervalo aberto com nível de confiança igual a \((1-\alpha)\)
A Figura 9.16 ilustra um intervalo de confiança unilateral limitado à esquerda por um valor mínimo, de tal sorte que a probabilidade associada ao intervalo de valores da estatística \(Z\) superiores a esse limitante é
\[ P\left [\mu \ge \bar{x} - {z}_{c} \cdot \frac{S}{\sqrt{n}} \right ] = (1- \alpha) \]
prob_desejada=0.05
z_desejado=round(qnorm(prob_desejada),4)
d_desejada=dnorm(z_desejado, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(-4, 0),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(-4, z_desejado),
colour="black")+
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c( z_desejado, 4),
colour="black")+
labs(title=
"Curva da função densidade
\nDistribuição Normal Padrão",
subtitle = "P(-\U221e; z)=\u03b1, em vermelho \nP(z, + \U221e)= (1-\u03b1) em cinza")+
annotate(geom="text", x=z_desejado1+0.5, y=d_desejada1, label="-z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1-1.5, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo aberto à dir. \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()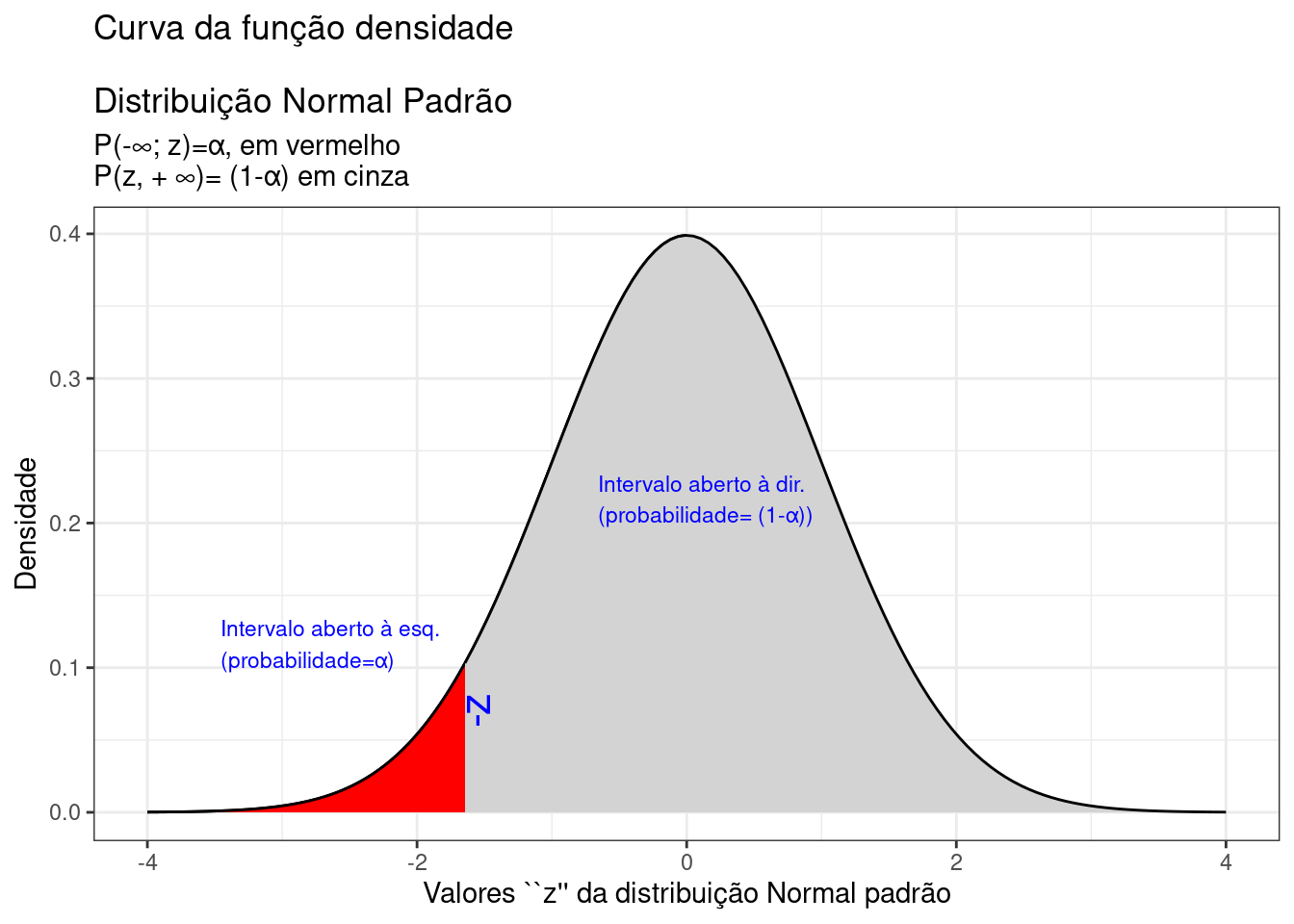
Figure 9.16: Região crítica, aquém da qual, a probabilidade associada aos valores \(Z\) é inferior a \(\alpha\), delimitando assim, à direita, um intervalo aberto com nível de confiança igual a \((1-\alpha)\)
9.3.5 Intervalos de confiança para a média de uma população Normal com variância desconhecida e amostra de qualquer tamanho (Figura 9.17)
\[ T = \frac{(\stackrel{-}{X} - \mu)}{ \frac{S}{\sqrt{n}} } \sim t_{(n-1)} \]
em que:
- \(\stackrel{-}{X}\) é uma média amostral;
- \(\mu\) é a média populacional;
- \(S\) é o desvio padrão amostral;
- \(n\) é o tamanho da amostra; e,
- \(T\) é a estatística a ser calculada para a construção do intervalo de confiança sob o nível de significância \(\alpha\) estabelecido.
alfa=0.05
prob_desejada1=alfa/2
df=20
t_desejado1=round(qt(prob_desejada1,df ),4)
d_desejada1=dt(t_desejado1,df)
prob_desejada2=1-alfa/2
df=20
t_desejado2=round(qt(prob_desejada2, df),4)
d_desejada2=dt(t_desejado2,df)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(-4, t_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(t_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(0, t_desejado2),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(t_desejado2,4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``t'' da distribuição de Student com gl=n-1") +
labs(title= "Curva da função densidade \nDistribuição t ",
subtitle = "P(-t; t)=(1-\u03b1) em cinza (nível de confiança) \nP(-\U221e; -t)= P(t; \U221e)= \u03b1/2 em vermelho ")+
geom_segment(aes(x = t_desejado1, y = 0, xend = t_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
geom_segment(aes(x = t_desejado2, y = 0, xend = t_desejado2, yend = d_desejada2), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=t_desejado1-0.1, y=d_desejada1, label="-t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado2+0.3, y=d_desejada2, label="t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado1-1.8, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado2+0.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado1+1.3, y=0.2, label="Intervalo fechado \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+ theme_bw()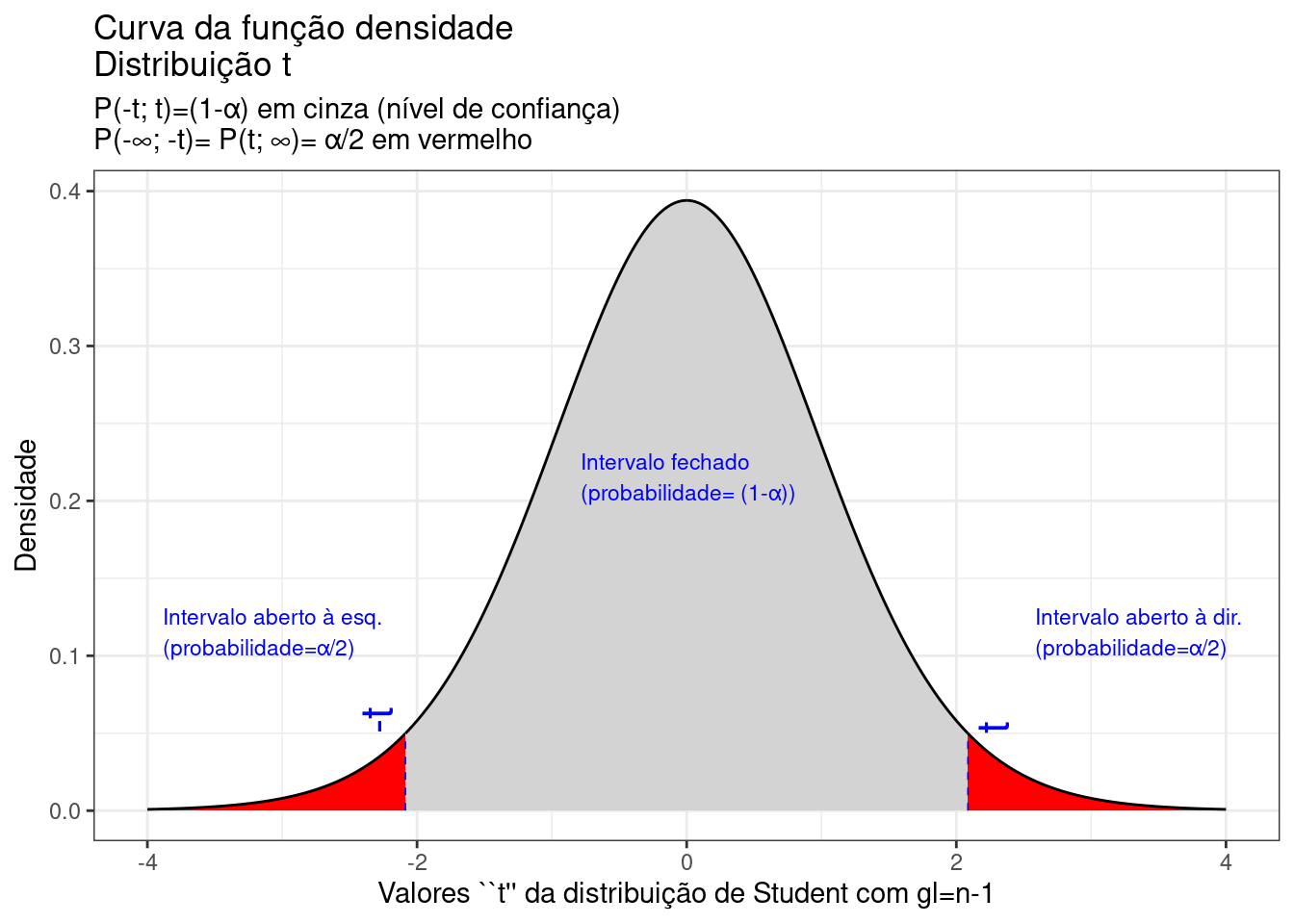
Figure 9.17: Regiões críticas, aquém e além das quais, a probabilidade associada aos valores \(T\) (\((n-1)\) graus de liberdade) é inferior a \(\frac{\alpha}{2}\), estabelecendo assim um intervalo com nível de confiança igual a \((1-\alpha)\)
Na Figura 9.17 observa-se:
- o nível de significância \(\alpha\);
- o nível de confiança \((1-\alpha)\); e,
- o valor tabelado da estatística \(T(t)\) sob \(n-1\) graus de liberdade para o nível de confiança fixado.
Assim,
\[\begin{align*} P\left[-{T}_{(1-\frac{\alpha }{2}, (n-1))}\le T \le {T }_{(1-\frac{\alpha }{2}, (n-1))}\right] & = (1-\alpha) \\ P\left[-{t}_{(1-\frac{\alpha }{2}, (n-1))}\le \frac{\stackrel{-}{x}-\mu }{\frac{S}{\sqrt{n}}} \le {t}_{(1-\frac{\alpha }{2}, (n-1))}\right] & = (1-\alpha) \\ P[\stackrel{-}{x}-({t}_{(1-\frac{\alpha }{2}, (n-1))} \cdot \frac{S}{\sqrt{n}}) \le \mu \le \stackrel{-}{x}+({t}_{(1-\frac{\alpha }{2}, (n-1))} \cdot \frac{S}{\sqrt{n}}) ] & = (1-\alpha) \end{align*}\]
\[ IC(\mu)_{(1-\alpha)}= [\stackrel{-}{x} \pm {t}_{c_{(n-1)}} \cdot \frac{S}{\sqrt{n}}] \]
Assim, se \(\stackrel{-}{x}\) é usado como estimativa de \(\mu\) podemos afirmar estar \(100(1-\alpha)\)% confiantes de que o erro não excederá \(({t}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}})\).
A quantidade \(\varepsilon=(\stackrel{-}{x}-\mu)= ({t}_{(1-\frac{\alpha }{2}, (n-1))} \cdot \frac{S}{\sqrt{n}})\) é chamada de Erro máximo da estimativa ao se arbitrar um nível de confiança \(\alpha\), (n-1) graus de liberdade e um determinado tamanho amostral.
Exemplo: As vendas de 15 lojas de uma região do país apresentam uma média igual a US$ 20.000,00 e desvio padrão de US$ 8.300,00. Construa o intervalo de confiança para a média ao nível de confiança de 95%.
Dados do problema:
- o tamanho da amostra: \(n=15\);
- a média amostral: \(\stackrel{-}{x}=US\$ 20.000\);
- o desvio padrão amostral: \(s=US\$ 8.300\);
- nível de confiança: \((1-\alpha)=0,95\); e,
- valor extraído da tabela da distribuição de sob \((n-1=15-1=14)\) graus de liberdade \(t_{c}=2,1448\) associado ao nível de confiança estipulado \((1-\alpha)=95\%\).
\[\begin{align*} P[\stackrel{-}{x}-({t}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}) \le \mu \le \stackrel{-}{x}+({t}_{(1-\frac{\alpha }{2})} \cdot \frac{S}{\sqrt{n}}) ] & = (1-\alpha) \\ P[20000 - ( 2,1448 \cdot \frac{8300}{\sqrt{15}}) \le \mu \le 20000 + ( 2,1448 \cdot \frac{8300}{\sqrt{15}}) ] & = 0,95\\ P[20000 - 4596,41 \le \mu \le 20000 + 4596,41 ] & = 0,95 \end{align*}\]
\[ IC_{(1-\alpha=0,95)} = [US\$ 15403,59 ; US\$ 24496,41] \]
Se quisermos ser rigorosos na interpretação do intervalo de confiança calculado podemos explicar que se extrairmos um grande número de amostras de tamanho 15 dessa população, e para todas elas calcularmos intervalos de confiança como o acima definido, a proporção desses intervalos onde poderemos encontrar a média populacional de vendas será de 0,95 (95 intervalos em 100).
De uma forma mais sintética, podemos afirmar que o intervalo aleatório ]US$ 15.403,59; US$ 24.496,41[, é um intervalo de confiança a 95% para a média de vendas.
De uma forma mais corrente, embora menos correta em termos teóricos, é usual afirmar que, com 95% de confiança a média de vendas se situa entre os valores US$ 15.403,59 e US$ 24.496,41.
Intervalos de confiança unilaterais para a média sob variância populacional desconhecida e amostras de qualquer tamanho
A Figura 9.18 ilustra um intervalo de confiança unilateral limitado à direita por um valor máximo, de tal sorte que a probabilidade associada ao intervalo de valores da estatística \(T\) inferiores a esse limitante é
\[ P\left [\mu \le \bar{x} + {t}_{c_{(n-1)}} \cdot \frac{S}{\sqrt{n}} \right ] = (1- \alpha) \]
alfa=0.95
prob_desejada1=alfa
df=20
t_desejado1=round(qt(prob_desejada1,df ),4)
d_desejada1=dt(t_desejado1,df)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c( t_desejado1, 4),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(0, t_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(-4, 0),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``t'' da distribuição de Student com gl=n-1") +
labs(title= "Curva da função densidade \nDistribuição t ",
subtitle = "P(-\U221e, t)=(1-\u03b1) em cinza \nP(t, \U221e)= \u03b1 em vermelho ")+
geom_segment(aes(x = t_desejado1, y = 0, xend = t_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=t_desejado1+0.5, y=d_desejada1, label="t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado1+1, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado1-2.5, y=0.2, label="Intervalo aberto \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+ theme_bw()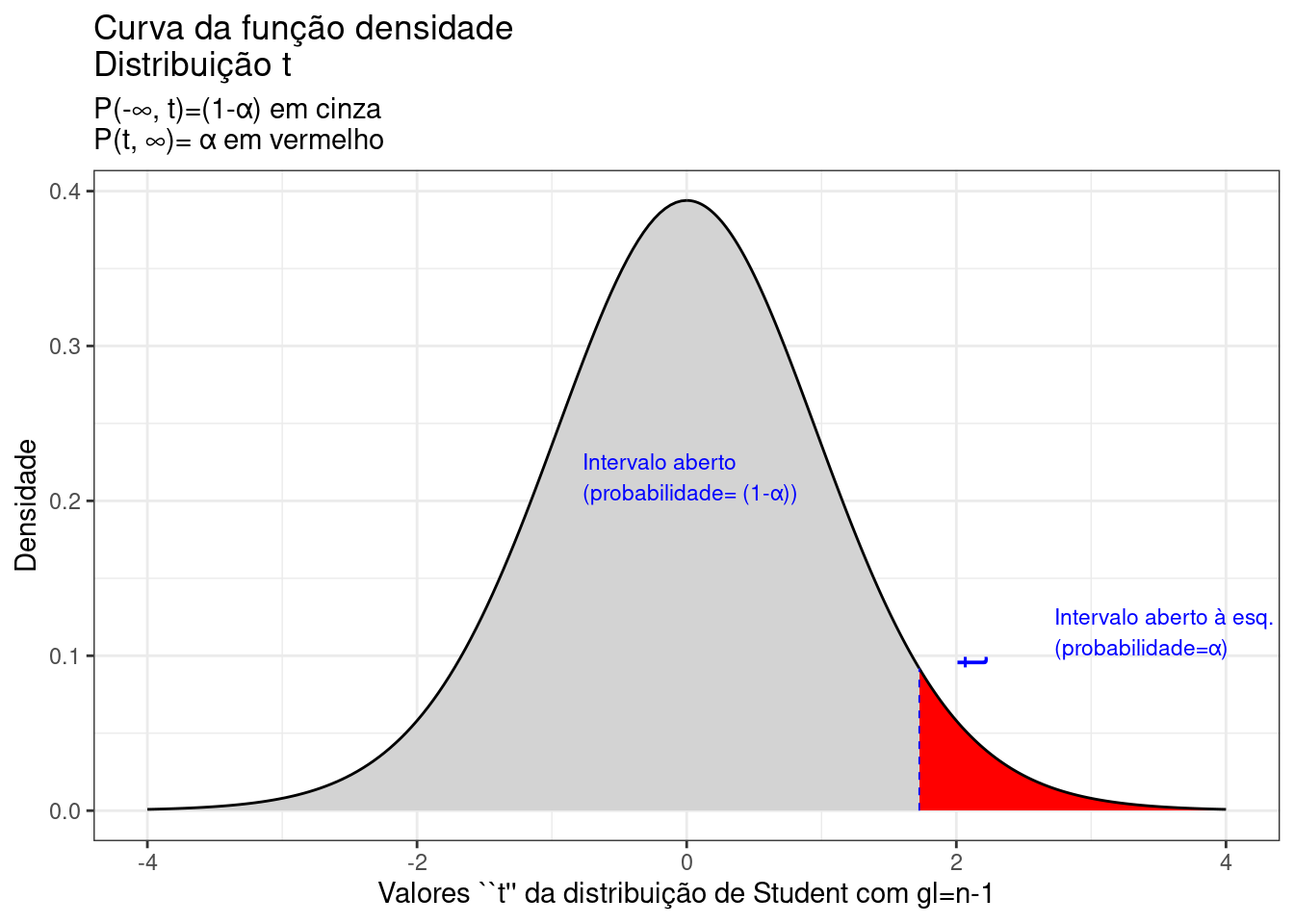
Figure 9.18: Região crítica, além da qual, a probabilidade associada aos valores \(T\) (\((n-1)\) graus de liberdade) é inferior a \(\alpha\), delimitando assim, à esquerda, um intervalo aberto com nível de confiança igual a \((1-\alpha)\)
A Figura 9.19 ilustra um intervalo de confiança unilateral limitado à esquerda por um valor mínimo, de tal sorte que a probabilidade associada ao intervalo de valores da estatística \(T\) superiores a esse limitante é
\[ P\left [\mu \ge \bar{x} - {t}_{c} \cdot \frac{S}{\sqrt{n}} \right ] = (1- \alpha) \]
alfa=0.05
prob_desejada1=alfa
df=20
t_desejado1=round(qt(prob_desejada1,df ),4)
d_desejada1=dt(t_desejado1,df)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(-4, t_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(t_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(0, 4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``t'' da distribuição de Student com gl=n-1") +
labs(title= "Curva da função densidade \nDistribuição t ",
subtitle = "P(-t, \U221e)=(1-\u03b1) em cinza \nP(-\U221e; -t)= \u03b1 em vermelho ")+
geom_segment(aes(x = t_desejado1, y = 0, xend = t_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=t_desejado1-0.1, y=d_desejada1, label="-t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado1-2.5, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado1+1, y=0.2, label="Intervalo aberto \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+ theme_bw()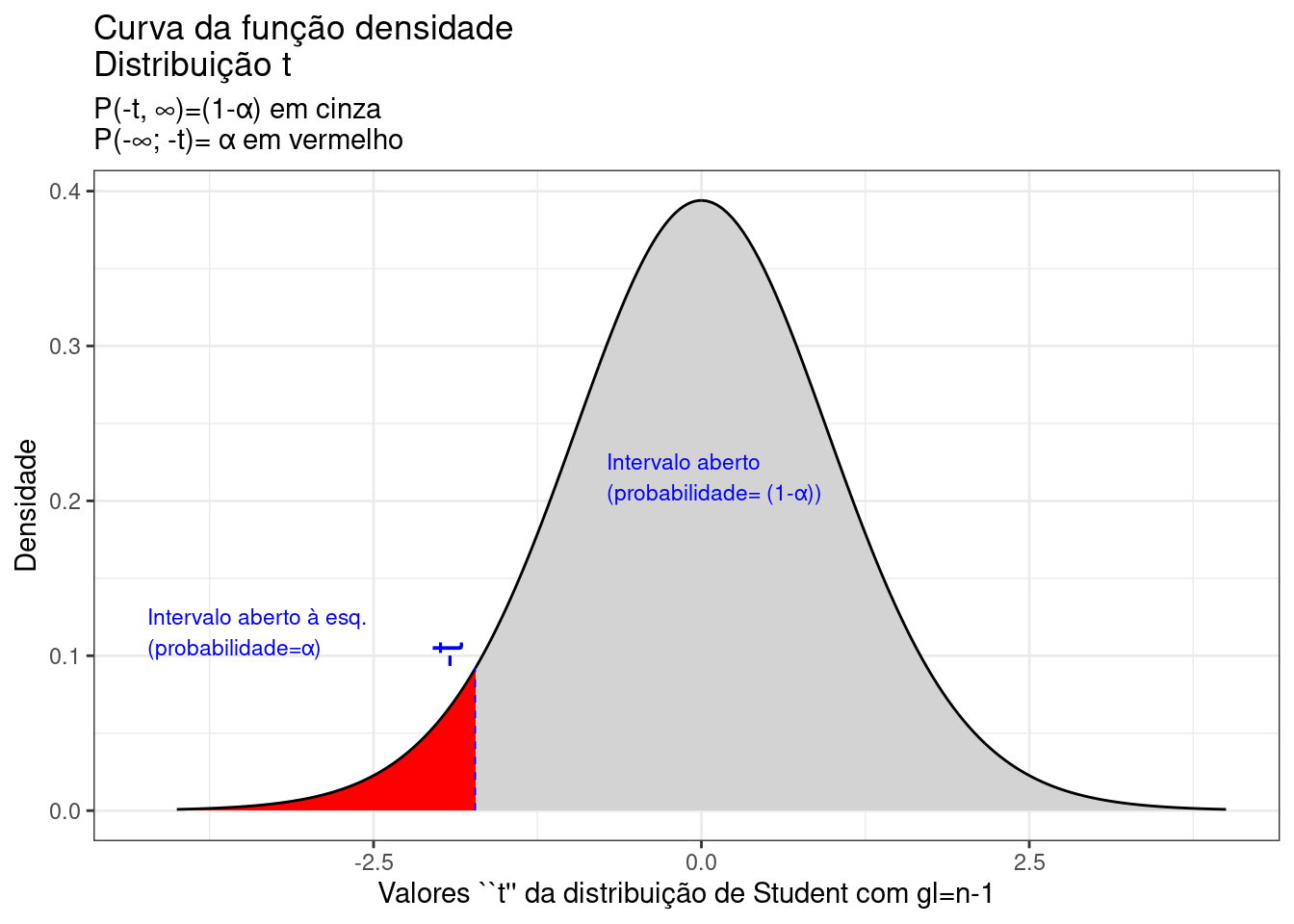
Figure 9.19: Região crítica, aquém da qual, a probabilidade associada aos valores \(T\) (\((n-1)\) graus de liberdade) é inferior a \(\alpha\), delimitando assim, à direita, um intervalo aberto com nível de confiança igual a \((1-\alpha)\)
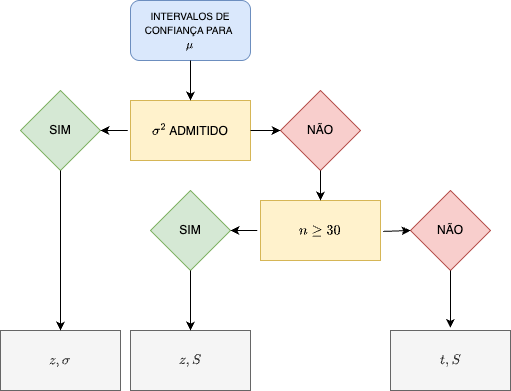
9.4 Distribuição das diferenças das médias de duas populações Normais e seus intervalos de confiança
Consideremos duas populações \(X\) e \(Y\) com médias \(\mu_{1}\) e \(\mu_{2}\) e variâncias \(\sigma_{1}^{2}\) e \(\sigma_{2}^{2}\), respectivamente.
Conforme seções anteriores, as médias amostrais \(\stackrel{-}{X}\) e \(\stackrel{-}{Y}\) são duas variáveis aleatórias tais que:
\[\begin{align*} \stackrel{-}{X} & \sim N(\mu_{1}, \frac{\sigma^{2}_{1}}{n_{1}} )\\ \stackrel{-}{Y} & \sim N(\mu_{2}, \frac{\sigma^{2}_{2}}{n_{2}} ) \end{align*}\]
Pode-se demonstrar, pelas propriedades da esperança e da variância, que a média e a variância de uma variável aleatória (população) que resulta da soma ou diferença de duas outras, \(X\) e \(Y\), é:
\[\begin{align*} \mu_{(X \pm Y)} & = \mu_{1} \pm \mu_{2}\\ \sigma^{2}_{(X \pm Y)} & = \sigma_{1}^{2} + \sigma_{2}^{2} \end{align*}\]
E a média e variância da soma ou diferença das distribuições amostrais das médias de \(X\) e \(Y\) é:
\[\begin{align*} \mu_{(\stackrel{-}{X} \pm \stackrel{-}{Y})} & = \mu_{1} \pm \mu_{2} \\ \sigma^{2}_{(\stackrel{-}{X} \pm \stackrel{-}{Y})} & = \frac{\sigma_{1}^{2}}{n_{1}} + \frac{\sigma_{2}^{2}}{n_{2}} \end{align*}\]
9.4.1 Intervalos de confiança para a diferença das médias de duas populações Nomrais de variâncias conhecidas e amostras independentes de qualquer tamanho
Se \((X_{1}, X_{2},...,X{n_{1}})\) e \((Y_{1}, Y_{2},...,Y{n_{2}})\) forem amostras aleatórias simples das populações \(X\) e \(Y\) com médias \(\mu_{1}\) e \(\mu_{2}\), e variâncias \(\sigma_{1}^{2}\) e \(\sigma_{2}^{2}\) conhecidas, e \(\stackrel{-}{X}=\frac{(X_{1}+X_{2}+...+X{n_{1}})}{n}\) e \(\stackrel{-}{Y}=\frac{(Y_{1}+Y_{2}+...+Y{n_{2}})}{n_{2}}\), então:
\[\begin{align*} {X} & \sim N( \mu_{1} , \frac{\sigma_{1}}{\sqrt{n_{1}}} ) \\ {Y} & \sim N( \mu_{2} , \frac{\sigma_{2}}{\sqrt{n_{2}}} ) \end{align*}\]
Demonstra-se que a diferença entre \(\stackrel{-}{X} e \stackrel{-}{Y}\) é tal que:
\[ \stackrel{-}{X} - \stackrel{-}{Y} \sim N((\mu_{1}-\mu_{2}) , \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) \]
Demonstra-se que a estatística \(Z\) pode ser assim definida, bem como sua correspondente distribuição (cf.Figura 9.21):
\[
Z = \frac{ (\stackrel{-}{X}-\stackrel{-}{Y}) - (\mu_{1}-\mu_{2})}{ \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } } \sim N(0 ,1)
\]
em que:
- \(\stackrel{-}{X}\)e \(\stackrel{-}{Y}\) são médias amostrais;
- \(\mu_{1}\) e \(\mu_{2}\) são as médias populacionais;
- \(\sigma_{1}^{2}\) e \(\sigma_{2}^{2}\) são as variâncias populacionais; e,
- \(n_{1}\) e \(n_{2}\) são os tamanhos das amostras
alfa=0.05
prob_desejada1=alfa/2
z_desejado1=round(qnorm(prob_desejada1),4)
d_desejada1=dnorm(z_desejado1, 0, 1)
prob_desejada2=1-alfa/2
z_desejado2=round(qnorm(prob_desejada2),4)
d_desejada2=dnorm(z_desejado2, 0, 1)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(-4, z_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(z_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "lightgrey",
xlim = c(0, z_desejado2),
colour="black") +
geom_area(stat = "function",
fun = dnorm,
fill = "red",
xlim = c(z_desejado2,4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``z'' da distribuição Normal padrão") +
labs(title=
"Curva da função densidade \nDistribuição Normal Padrão",
subtitle = "P(-z; z)=(1-\u03b1) em cinza (nível de confiança) \nP(-\U221e; -z)= P(z; \U221e)= \u03b1/2 em vermelho")+
geom_segment(aes(x = z_desejado1, y = 0, xend = z_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
geom_segment(aes(x = z_desejado2, y = 0, xend = z_desejado2, yend = d_desejada2), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=z_desejado1-0.1, y=d_desejada1, label="-z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado2+0.3, y=d_desejada2, label="z", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=z_desejado1-1.8, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado2+0.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=z_desejado1+1.3, y=0.2, label="Intervalo fechado \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+
theme_bw()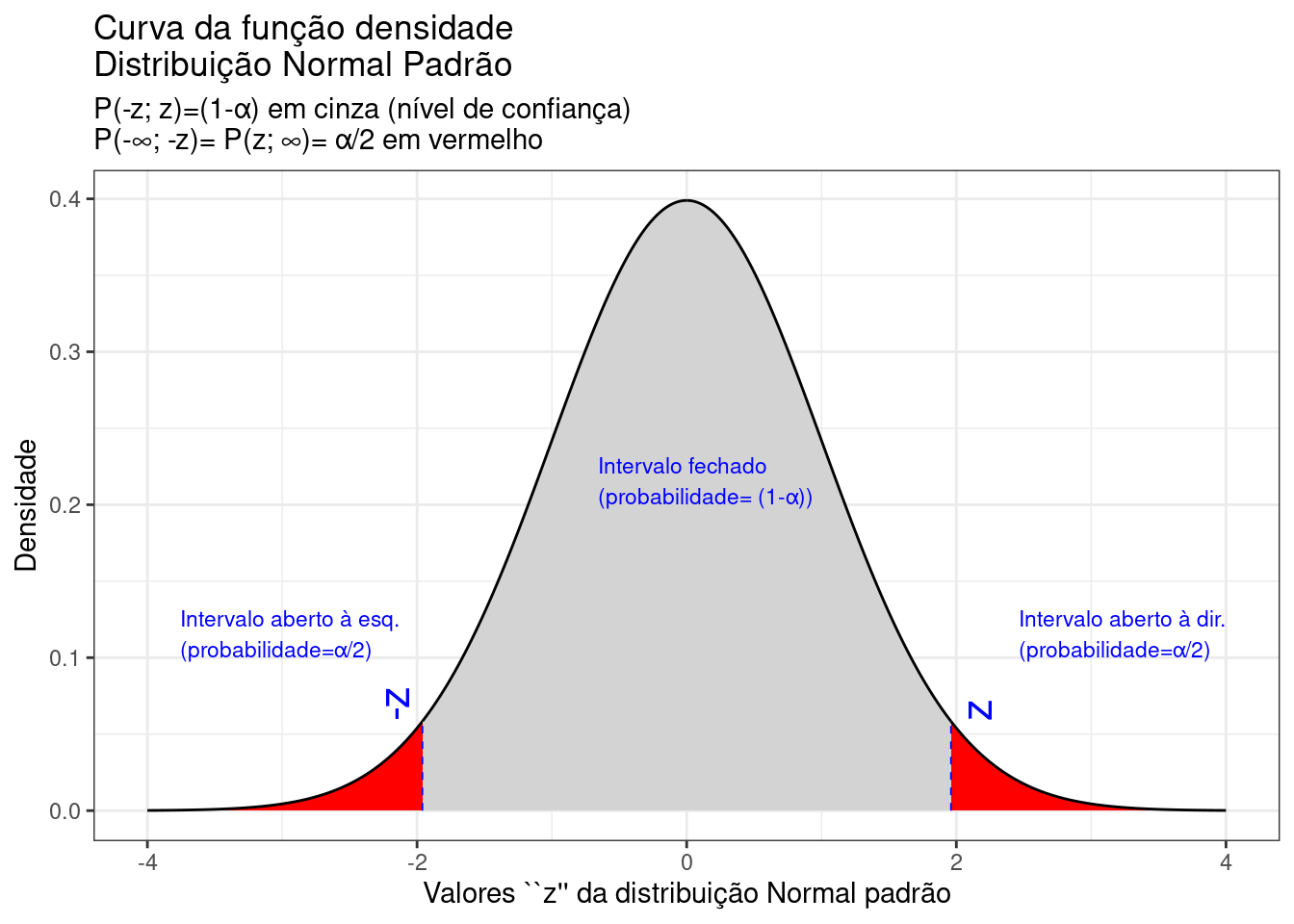
Figure 9.21: Regiões críticas, aquém e além das quais, a probabilidade associada aos valores da estatística \(Z\) é inferior a \(\frac{\alpha}{2}\), estabelecendo assim um intervalo com nível de confiança igual a \((1-\alpha)\)
Na Figura 9.21 observa-se:
- o nível de significância \(\alpha\);
- o nível de confiança \((1-\alpha)\); e,
- o valor tabelado da estatística \(Z(z)\) para o nível de confiança fixado.
Assim,
\[\begin{align*} P\left[-{Z}_{(1-\frac{\alpha }{2})}\le Z \le {Z }_{(1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P\left[-{z}_{(1-\frac{\alpha }{2})}\le \frac{ (\stackrel{-}{x}-\stackrel{-}{y}) - (\mu_{1}-\mu_{2})}{ \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } } \le {z}_{(1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({z}_{(1-\frac{\alpha }{2})} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({z}_{(1-\frac{\alpha }{2})} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) ] & = (1-\alpha) \end{align*}\]
\[ IC(\mu_{1}-\mu_{2})_{(1-\alpha)}=[ (\stackrel{-}{x}-\stackrel{-}{y} ) \pm {z}_{c} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ] \]
Exemplo: Uma empresa possui duas filiais (A e B). Uma amostra das vendas de 20 dias forneceu uma venda média diária de 40 unidades dessa peça a filial A e de 30 unidades da mesma peça para a filial B. Os desvios padrão das vendas diárias dessa peça são de 5 e 3, respectivamente. Admitindo que a distribuição diária das vendas dessa peça siga uma distribuição Normal, qual o intervalo de confiança para a diferença de médias das vendas nas duas filiais com um nível de confiança de 95%?
Dados do problema:
- \(\stackrel{-}{x}=40\) e \(\stackrel{-}{y}=30\) são as médias amostrais (vendas médias diárias nas filiais A e B, respectivamente);
- \(\sigma_{1}^{2}=25\) e \(\sigma_{2}^{2}=9\) são as variâncias populacionais;
- \(n_{1} = n_{2}=20\) são os tamanhos das amostras; e,
- valor extraído da tabela \(z=1,96\) correspondente ao nível de confiança estipulado \((1-\alpha)=95\%\).
\[\begin{align*} P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({z}_{(1-\frac{\alpha }{2})} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({z}_{(1-\frac{\alpha }{2})} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) ] & =(1-\alpha) \\ P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({z}_{(1-\frac{\alpha }{2})} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({z}_{(1-\frac{\alpha }{2})} \cdot \sqrt{\frac{\sigma^{2}_{1}}{n_{1}} + \frac{\sigma^{2}_{2}}{n_{2}} } ) ] & = (1-\alpha) \\ P[10 - ( 1,96 \cdot \sqrt{\frac{25}{20} + \frac{9}{20}} ) \le (\mu_{1}-\mu_{2}) \le ( 10 + ( 1,96 \cdot \sqrt{\frac{25}{20} + \frac{9}{20} } ) ] & = 0,95 \\ P[10 - (1,96 \times 1,3038) \le (\mu_{1}-\mu_{2}) \le 10 + (1,96 \times 1,3038) ] & = 0,95 \end{align*}\]
\[ IC (\mu_{1} - \mu_{2})_{0,95} = [7; 13] \]
Se quisermos ser rigorosos na interpretação do intervalo de confiança calculado podemos explicar que, se extrairmos um grande número de amostras dessas mesmas dimensões das vendas dessa peça nas duas empresas, e para cada uma delas calcularmos suas médias e as diferenças entre elas, e calcularmos os intervalos de confiança como o acima definido, a proporção desses intervalos onde podemos encontrar a diferença das médias de vendas dessa peça da filial A para a filial B será de 0,95 (95 intervalos em 100).
De uma forma mais sintética podemos afirmar que, o anterior intervalo aleatório [7 ; 13], é um intervalo de confiança a 95% para a diferença das médias de vendas dessa peça nas duas empresa
De uma forma mais corrente, embora menos correta em termos teóricos, é usual afirmar que, com 95% de confiança a diferença das médias de vendas dessa peça da filial A para a filial B se situa entre os valores 7 e 13.
Uma segunda observação se faz pertinente e se refere à natureza dos dados analisados e a forma de apresentação do resultado. Por serem dados discretos, o intervalo de confiança deverá ser apresentado em igual forma, sem ultrapassar os limites estabelecidos. Isto posto: \(IC (\mu_{1} - \mu_{2})_{0,95} = [7; 13]\) .
9.4.2 Intervalos de confiança para a diferença das médias de duas populações Normais de variâncias desconhecidas e amostras independentes grandes
A estatística \(Z\) fica assim definida e sua distribuição aproximada:
\[
Z = \frac{ (\stackrel{-}{X}-\stackrel{-}{Y}) - (\mu_{1}-\mu_{2})}{ \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } } \approx N(0 ,1)
\]
em que:
- \(\stackrel{-}{X}\)e \(\stackrel{-}{Y}\) são médias amostrais;
- \(\mu_{1}\) e \(\mu_{2}\) são as médias populacionais;
- \(S_{1}^{2}\) e \(S_{2}^{2}\) são as variâncias populacionais; e,
- \(n_{1}\) e \(n_{2}\) são os tamanhos das amostras, necessariamente maiores que 30
9.4.3 Intervalos de confiança para a diferença das médias de duas populações Normais de variâncias desconhecidas mas iguais
Se \((X_{1}, X_{2},...,X{n_{1}})\) e \((Y_{1}, Y_{2},...,Y{n_{2}})\) forem amostras aleatórias simples das populações \(X\) e \(Y\) com médias \(\mu_{1}\) e \(\mu_{2}\), e variâncias \(\sigma_{1}^{2}\) e \(\sigma_{2}^{2}\) desconhecidas porém iguais (\(\sigma_{1}^{2}=\sigma_{2}^{2}=\sigma^{2}\)), e \(\stackrel{-}{X}=\frac{(X_{1}+X_{2}+...+X{n_{1}})}{n}\) e \(\stackrel{-}{Y}=\frac{(Y_{1}+Y_{2}+...+Y{n_{2}})}{n_{2}}\), então:
\[\begin{align*} {X} & \sim N( \mu_{1} , \frac{\sigma}{\sqrt{n_{1}}} )\\ {Y} & \sim N( \mu_{2} , \frac{\sigma}{\sqrt{n_{2}}} ) \end{align*}\]
Demonstra-se que a estatística \(T\) pode ser assim definida, bem como sua correspondente distribuição (cf. Figura \(\ref{fig62}\)):
\[ T = \frac{ (\stackrel{-}{X}-\stackrel{-}{Y}) - (\mu_{1}-\mu_{2})}{S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } } \sim t(n_{1}+n_{2}-2) \]
em que:
- \(\stackrel{-}{X}\)e \(\stackrel{-}{Y}\) são médias amostrais;
- \(S_{1}^{2}\) e \(S_{2}^{2}\) são as variâncias amostrais;
- \(\mu_{1}\) e \(\mu_{2}\) são as médias populacionais;
- \(S_{p}\) é um desvio padrão amostral ponderado para as duas amostras;
- \(n_{1}\) e \(n_{2}\) são os tamanhos das amostras;
O desvio padrão ponderado \(S_{p}\) é dado por:
\[
S_{p} = \sqrt{\frac{(n_{1}-1)\cdot S^{2}_{1} + (n_{2}-1)\cdot S^{2}_{2}}{n_{1}+n_{2}-2}}
\]
alfa=0.05
prob_desejada1=alfa/2
df=20
t_desejado1=round(qt(prob_desejada1,df ),4)
d_desejada1=dt(t_desejado1,df)
prob_desejada2=1-alfa/2
df=20
t_desejado2=round(qt(prob_desejada2, df),4)
d_desejada2=dt(t_desejado2,df)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(-4, t_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(t_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(0, t_desejado2),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(t_desejado2,4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``t'' da distribuição de Student") +
labs(title= "Curva da função densidade \nDistribuição t (df=20)",
subtitle = "P(-t; t)=(1-\u03b1) em cinza (nível de confiança) \nP(-\U221e; -t)= P(t; \U221e)= \u03b1/2 em vermelho ")+
geom_segment(aes(x = t_desejado1, y = 0, xend = t_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
geom_segment(aes(x = t_desejado2, y = 0, xend = t_desejado2, yend = d_desejada2), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=t_desejado1-0.1, y=d_desejada1, label="-t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado2+0.3, y=d_desejada2, label="t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado1-1.8, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado2+0.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado1+1.3, y=0.2, label="Intervalo fechado \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+ theme_bw()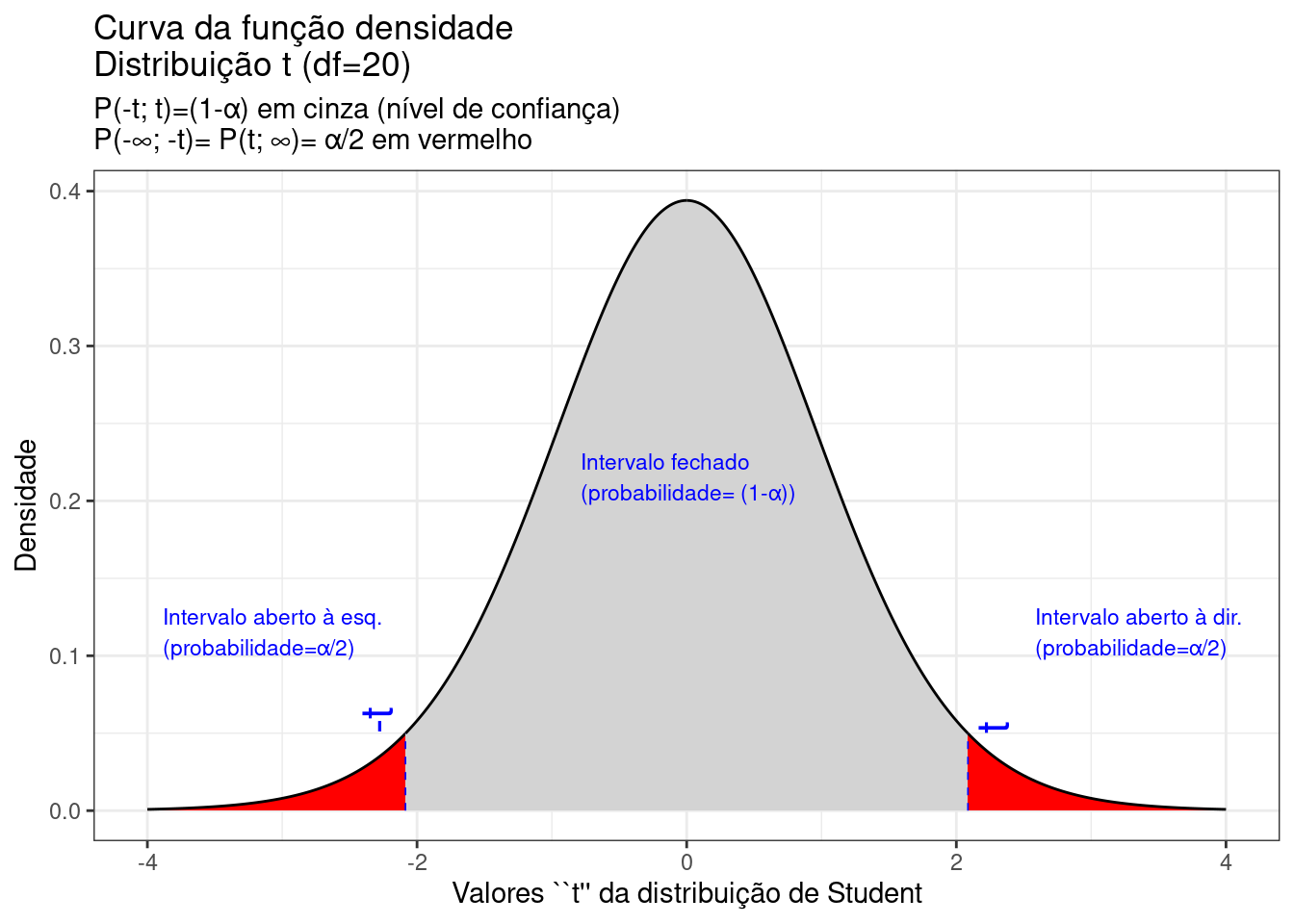
Figure 9.22: Regiões críticas, aquém e além das quais, a probabilidade associada aos valores da estatística \(T\) (\((n-1)\) graus de liberdade) é inferior a \(\frac{\alpha}{2}\), estabelecendo assim um intervalo com nível de confiança igual a \((1-\alpha)\)
Na Figura 9.22 observa-se:
- o nível de significância \(\alpha\);
- o nível de confiança \((1-\alpha)\); e,
- o valor tabelado da estatística \(T(t)\) sob \((n_{1}+n_{2}-2)\) graus de liberdade para o nível de confiança fixado.
Assim,
\[\begin{align*} P\left[-{T}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})}\le T \le {T}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P\left[-{t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})}\le \frac{ (\stackrel{-}{x}-\stackrel{-}{y}) - (\mu_{1}-\mu_{2})}{S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } } \le {t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})}\right] & =(1-\alpha) \\ P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) ] & =(1-\alpha) \end{align*}\]
\[ IC(\mu_{1}-\mu_{2})_{(1-\alpha)}=[ (\stackrel{-}{x}-\stackrel{-}{y} ) \pm {t}_{c(n_{1}+n_{2}-2)} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ] \]
Exemplo: De uma grande turma extraiu-se uma pequena amostra de quatro notas de uma prova: 64, 66, 89, 77. De uma outra turma, extraiu-se uma outra amostra, independente, de três notas: 56, 71, 53. Se for razoável admitir que as variâncias das duas turmas (\(\sigma^{2}_{1}\) e \(\sigma^{2}_{2}\)) sejam iguais, qual seria o intervalo de confiança para a diferença observada entre essas médias, a um nível de confiança de 95%?
Dados do problema:
- \(\stackrel{-}{X}=74\) e \(\stackrel{-}{Y}=60\) são as médias calculadas sobre as duas amostras (notas nas turmas);
- \(S_{1}^{2}=132,67\) e \(S_{2}^{2}=93\) são as variâncias calculadas sobre as duas amostras;
- \(n_{1} = 4\) e \(n_{2}=3\) são os tamanhos das amostras;
- \(n_{1}+ n_{2}-2=5\) são os graus de liberdade; e,
- \(t=2,57\) o valor tabelado da estatística para um nível de significância \(\alpha=5\%\) e graus de liberdade \(gl=5\).
\[\begin{align*} P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) ]=(1-\alpha) \end{align*}\]
O desvio padrão ponderado \(S_{p}\) é dado por:
\[\begin{align*} S_{p} & = \sqrt{\frac{(n_{1}-1)\cdot S^{2}_{1} + (n_{2}-1)\cdot S^{2}_{2}}{n_{1}+n_{2}-2}} \\ S_{p} & = \sqrt{\frac{( 4-1)\cdot 132,67 + ( 3 -1)\cdot 93 }{4 + 3 - 2}} \\ S_{p} & = 10,81 \end{align*}\]
\[\begin{align*} P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({t}_{(n_{1}+n_{2}-2, 1-\frac{\alpha }{2})} \cdot S_{p} \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) ] & = (1-\alpha) \\ P[ 14 - ( 2,57 \cdot 10,81 \cdot \sqrt{\frac{1}{4} + \frac{1}{3} } ) \le (\mu_{1}-\mu_{2}) \le 14 +( 2,57 \cdot 10,81 \cdot \sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}} } ) ] & = 0,95 \\ P[ 14 - 21,23 \le (\mu_{1}-\mu_{2}) \le 14 + 21,23 ] & =0,95 \end{align*}\]
\[ IC (\mu_{1} - \mu_{2})_{0,95} = [-7,23; 35,23 ] \]
Se quisermos ser rigorosos na interpretação do intervalo de confiança calculado podemos explicar que, se extrairmos um grande número de amostras dessas mesmas dimensões das vendas dessa peça nas duas empresas, e para cada uma delas calcularmos suas médias e as diferenças entre elas, e calcularmos os intervalos de confiança como o acima definido, a proporção desses intervalos onde podemos encontrar a diferença das médias de vendas dessa peça da filial A para a filial B será de 0,95 (95 intervalos em 100).
De uma forma mais sintética podemos afirmar que o intervalo aleatório [-7,23; 35,23], é um intervalo de confiança a 95% para a diferença das médias das notas dessas provas nas duas turmas.
De uma forma mais corrente, embora menos correta em termos teóricos, é usual afirmar que, com 95% de confiança a diferença das médias das notas da primeira turma para a segunda turma se situa entre os valores -7,23 e 35,23.
Uma importante conclusão pode ser extraída ao se analisar um pouco mais atentamente o intervalo calculado [-7,23 ; 35,23]. Vê-se que encontra-se dentro desse intervalo o valor 0 indicando que a diferença entre as médias amopstrais pode ser zero sob esse nível de confiança, o que equivale dizer que sob esse nível de confiança não se pode afirmar existir diferença significativa (i.e. sob o nível de significância) entre as médias das notas dessas duas turmas.
9.4.4 Intervalos de confiança para a diferença das médias de duas populações Normais de variâncias desconhecidas e desiguais
Se \((X_{1}, X_{2},...,X{n_{1}})\) e \((Y_{1}, Y_{2},...,Y{n_{2}})\) forem amostras aleatórias simples das populações \(X\) e \(Y\) com médias \(\mu_{1}\) e \(\mu_{2}\), e variâncias \(\sigma_{1}^{2}\) e \(\sigma_{2}^{2}\) desconhecidas porém iguais (\(\sigma_{1}^{2}=\sigma_{2}^{2}=\sigma^{2}\)), e \(\stackrel{-}{X}=\frac{(X_{1}+X_{2}+...+X{n_{1}})}{n}\) e \(\stackrel{-}{Y}=\frac{(Y_{1}+Y_{2}+...+Y{n_{2}})}{n_{2}}\), então:
\[\begin{align*} {X} & \sim N( \mu_{1} , \frac{\sigma}{\sqrt{n_{1}}} ) \\ {Y} & \sim N( \mu_{2} , \frac{\sigma}{\sqrt{n_{2}}} ) \end{align*}\]
Demonstra-se que a estatística \(T\) pode ser assim definida, bem como sua correspondente distribuição (cf. Figura \(\ref{fig63}\)):
\[ T = \frac{ (\stackrel{-}{X}-\stackrel{-}{Y}) - (\mu_{1}-\mu_{2})}{ \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}}}} \sim t_{\nu} \]
em que:
- \(\stackrel{-}{X}\)e \(\stackrel{-}{Y}\) são as médias das amostras extraídas;
- \(\mu_{1}\) e \(\mu_{2}\) são as médias populacionais;
- \(n_{1}\) e \(n_{2}\) são os tamanhos das amostras; e,
- \(S_{1}^{2}\) e \(S_{2}^{2}\) são as variâncias das amostras.
O número de graus de liberdade (\(\nu\)) é dado por:
\[ \nu = \frac{ (\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}})^{2} } { \frac{(\frac{S^{2}_{1}}{n_{1}})^{2}}{n_{1}-1} + \frac{(\frac{S^{2}_{2}}{n_{2}})^{2}}{n_{2}-1} }, \]
arredondado para o inteiro inferior mais próximo.
alfa=0.05
prob_desejada1=alfa/2
df=20
t_desejado1=round(qt(prob_desejada1,df ),4)
d_desejada1=dt(t_desejado1,df)
prob_desejada2=1-alfa/2
df=20
t_desejado2=round(qt(prob_desejada2, df),4)
d_desejada2=dt(t_desejado2,df)
ggplot(NULL, aes(c(-4,4))) +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(-4, t_desejado1),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(t_desejado1,0),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "lightgrey",
xlim = c(0, t_desejado2),
colour="black") +
geom_area(stat = "function",
fun = dt,
args=list(df),
fill = "red",
xlim = c(t_desejado2,4),
colour="black") +
scale_y_continuous(name="Densidade") +
scale_x_continuous(name="Valores ``t'' da distribuição de Student") +
labs(title= "Curva da função densidade \nDistribuição t (df=20)",
subtitle = "P(-t; t)=(1-\u03b1) em cinza (nível de confiança) \nP(-\U221e; -t)= P(t; \U221e)= \u03b1/2 em vermelho ")+
geom_segment(aes(x = t_desejado1, y = 0, xend = t_desejado1, yend = d_desejada1), color="blue", lty=2, lwd=0.3)+
geom_segment(aes(x = t_desejado2, y = 0, xend = t_desejado2, yend = d_desejada2), color="blue", lty=2, lwd=0.3)+
annotate(geom="text", x=t_desejado1-0.1, y=d_desejada1, label="-t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado2+0.3, y=d_desejada2, label="t", angle=90, vjust=0, hjust=0, color="blue",size=6)+
annotate(geom="text", x=t_desejado1-1.8, y=0.1, label="Intervalo aberto à esq. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado2+0.5, y=0.1, label="Intervalo aberto à dir. \n(probabilidade=\u03b1/2)", angle=0, vjust=0, hjust=0, color="blue",size=3)+
annotate(geom="text", x=t_desejado1+1.3, y=0.2, label="Intervalo fechado \n(probabilidade= (1-\u03b1))", angle=0, vjust=0, hjust=0, color="blue",size=3)+ theme_bw()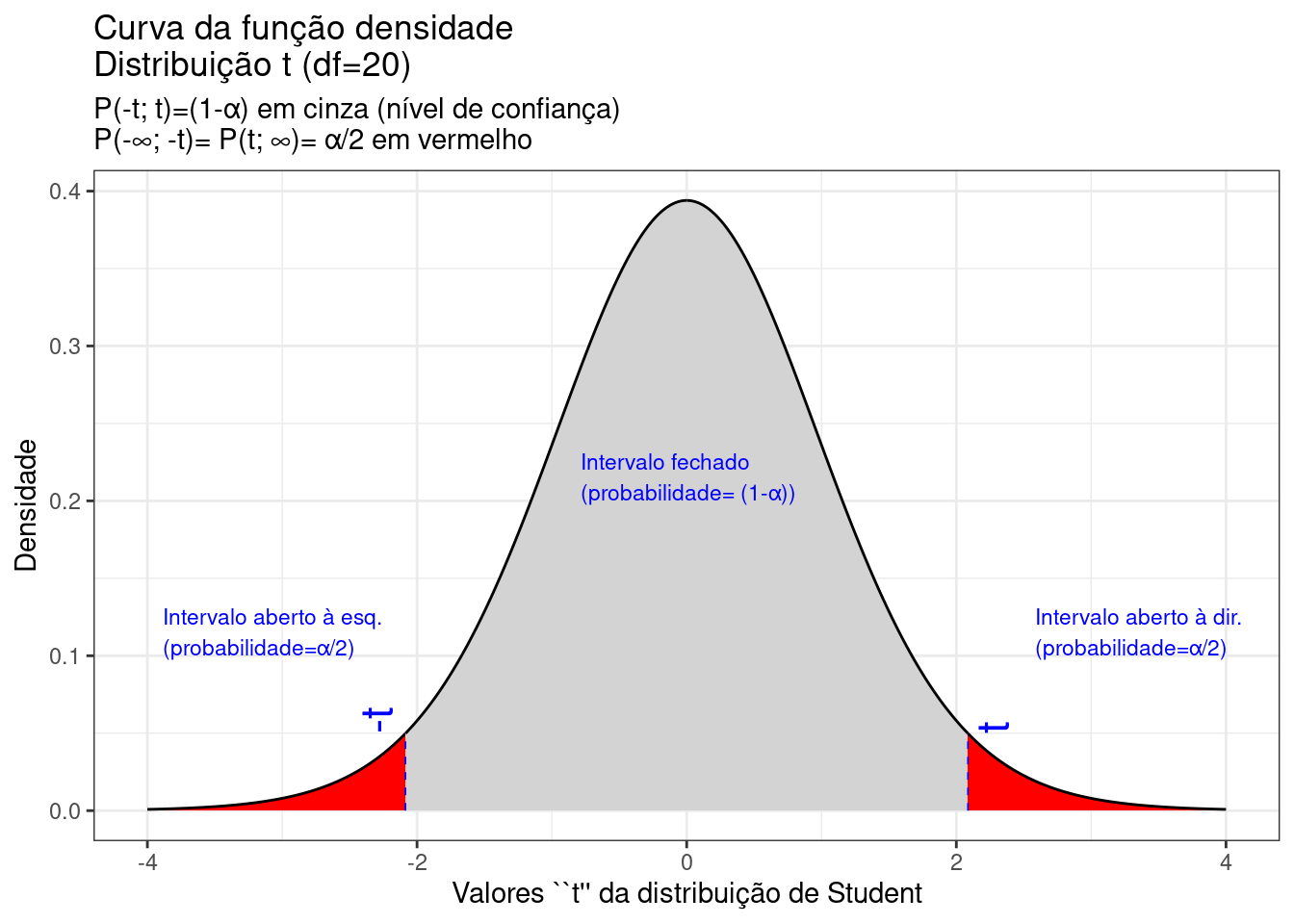
Figure 9.23: Regiões críticas, aquém e além das quais, a probabilidade associada aos valores da estatística \(T\) (com \(\nu\) graus de liberdade) é inferior a \(\frac{\alpha}{2}\), estabelecendo assim um intervalo com nível de confiança igual a \((1-\alpha)\)
Na Figura 9.23 observa-se:
- o nível de significância \(\alpha\);
- o nível de confiança \((1-\alpha)\); e,
- o valor tabelado da estatística \(T(t)\) sob \(\nu\) graus de liberdade para o nível de confiança fixado.
Assim,
\[\begin{align*} P\left[-{T}_{(\nu, 1-\frac{\alpha }{2})}\le T \le {T}_{( \nu, 1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P\left[-{t}_{( \nu, 1-\frac{\alpha }{2})}\le \frac{ (\stackrel{-}{x}-\stackrel{-}{y}) - (\mu_{1}-\mu_{2})}{\sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } } \le {t}_{( \nu, 1-\frac{\alpha }{2})}\right] & = (1-\alpha) \\ P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({t}_{( \nu, 1-\frac{\alpha }{2})} \cdot \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({t}_{( \nu, 1-\frac{\alpha }{2})} \cdot \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } ) ] & = (1-\alpha) \end{align*}\]
\[ IC(\mu_{1}-\mu_{2})_{(1-\alpha)} = [(\stackrel{-}{x}-\stackrel{-}{y} ) \pm {t}_{c (\nu)} \cdot \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } ] \]
Exemplo: De uma pequena classe do curso de ensino médio tomou-se uma amostra de 4 provas de matemática, obtendo-se um valor médio de 81 sob uma variância de 2. Outra amostra, de 6 provas de biologia, forneceu um valor médio de 77 sob uma variância de 14,4. Qual seria o intervalo de confiança para a diferença observada entre essas médias, sob um nível de confiança de 95%?
Dados do problema:
Dados do problema:
- \(\stackrel{-}{X}=81\) e \(\stackrel{-}{Y}=77\) são as médias calculadas sobre as duas amostras (notas nas turmas);
- \(S_{1}^{2}=2\) e \(S_{2}^{2}=14,40\) são as variâncias calculadas sobre as duas amostras;e,
- \(n_{1} = 4\) e \(n_{2}=6\) são os tamanhos das amostras.
O número de graus de liberdade (\(\nu\)) é dado por:
\[\begin{align*} \nu & = \frac{ (\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}})^{2} } { \frac{(\frac{S^{2}_{1}}{n_{1}})^{2}}{n_{1}-1} + \frac{(\frac{S^{2}_{2}}{n_{2}})^{2}}{n_{2}-1} } \\ \nu & = \frac{ (\frac{2}{4} + \frac{14,40}{6})^{2}}{\frac{(\frac{2}{4})^{2}}{4-1} + \frac{(\frac{14,40}{6})^{2}}{6-1} } \\ \nu & = \frac{ 2,90^{2}}{0,083 + 1,152} \\ \nu & = \frac{ 8,41}{1,23} = 6,83 \sim 6 \\ \end{align*}\]
Portanto, \(t=2,44\) é o valor tabelado da estatística para um nível de significância \(\alpha=5\%\) e graus de liberdade \(gl=6\).
\[\begin{align*} P[(\stackrel{-}{x}-\stackrel{-}{y} ) - ({t}_{( \nu, 1-\frac{\alpha }{2})} \cdot \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } ) \le (\mu_{1}-\mu_{2}) \le (\stackrel{-}{x}-\stackrel{-}{y}) +({t}_{( \nu, 1-\frac{\alpha }{2})} \cdot \sqrt{\frac{S^{2}_{1}}{n_{1}} + \frac{S^{2}_{2}}{n_{2}} } ) ] & = (1-\alpha) \\ P[ 4 - ( 2,44 \cdot \sqrt{\frac{ 2}{4} + \frac{14,40}{6}} ) \le (\mu_{1}-\mu_{2}) \le 4 +( 2,44 \cdot \sqrt{\frac{ 2}{4} + \frac{14,40}{6}} ) ] & = 0,95 \\ P[ 4 - ( 2,44 \cdot 1,70 ) \le (\mu_{1}-\mu_{2}) \le 4 +( 2,44 \cdot 1,70 ) ] & = 0,95 \\ P[ 4 - 4,15 \le (\mu_{1}-\mu_{2}) \le 4 + 4,15 ) ] & = 0,95 \\ \end{align*}\]
\(IC (\mu_{1} - \mu_{2})_{0,95} = [-0,15 ; 8,15]\)
Se quisermos ser rigorosos na interpretação do intervalo de confiança calculado podemos explicar que, se extrairmos um grande número de amostras dessas mesmas dimensões das notas dessas provas nas duas turmas, e para cada uma delas calcularmos suas médias e as diferenças entre elas, e calcularmos os intervalos de confiança como o acima definido, a proporção desses intervalos onde podemos encontrar a diferença das notas notas da prova de matemática para a prova de biologia será de 0,95 (95 intervalos em 100).
De uma forma mais sintética podemos afirmar que, o anterior intervalo aleatório [-0,01; 8,01], é um intervalo de confiança a 95% para a diferença das médias das notas dessas provas nas duas turmas.
De uma forma mais corrente, embora menos correta em termos teóricos, é usual afirmar que, com 95% de confiança a diferença das médias das notas da prova de matemática para a prova de biologia situa entre os valores -0,01 e 8,01.
Uma importante conclusão pode ser extraída ao se analisar um pouco mais atentamente o intervalo calculado [-0,01 ; 8,01]. Vê-se que encontra-se dentro desse intervalo o valor 0 indicando que a diferença entre as médias amopstrais pode ser zero sob esse nível de confiança, o que equivale dizer que sob esse nível de confiança não se pode afirmar existir diferença significativa (i.e. sob o nível de significância) entre as médias dessas notas.
9.5 Distribuição das diferenças das médias de duas populações Normais com médias não independentes e seus intervalos de confiança
Na prática temos algumas situações onde as amostras não são independentes com, por exemplo, em situações quando são extraídas de uma mesma população em dois momentos distintos (antes e depois de algum fato), ou como numa situação de comparação inter laboratorial, onde dois laboratórios medem a mesma peça, as medidas entre os laboratórios não são independentes. Nestes casos diz-se que os dados são pareados.
Considere duas amostras dependentes \((X_{1}, \dots X_{n})\) e \((Y_{1}, \dots Y_{n})\). O pareamento das observações será considerado tomando-se \((X_{1}, Y_{1}), \dots, (X_{n}, Y_{n})\) e as diferenças serão tomadas a cada par \(D_{i}=X_{i} - Y_{i}\), para \(i=1, \dots, n\).
Assim obtemos uma amostra \((D_{1}, \dots, D_{n})\), resultante das diferenças entre os valores de cada par. A variável aleatória será admitida tal que
\[ D \sim N (\mu_{D}, \sigma^{2}_{D}) \]
O parâmetro da média dessa distribuição (\(\mu_{D}\)) será estimado a partir da própria amostra das diferenças, tal que:
\[ \mu_{D}=\stackrel{-}{D}=\sum_{i=1}^{n}D_{i} \]
e a variância populacional desconhecida será aproximada por:
\[ S^{2}_{D}=\sum_{i=1}^{n}\frac{(D{i}-\stackrel{-}{D})^{2}}{n-1} \]
Demonstra-se que a estatística \(T\) pode ser assim definida, bem como sua correspondente distribuição
\[ T = \frac{\stackrel{-}{D} -\mu_{D}}{\frac{S_{D}}{\sqrt{n}}} \sim t_{(n-1)} \]
Assim,
\[ IC(\mu_{D})_{(1-\alpha)} = [\stackrel{-}{D} \pm {t}_{c (n-1)} \cdot \sqrt{\frac{S_{D}^{2}}{n} } ] \]
Exemplo: Determinar o intervalo de confiança sob um nível de confiança de 95% para a diferença de médias do resultados dos testes de um grupo de 15 alunos submetidos a um vídeo instrutivo tais que a primeira amostra foi tomada antes de assistirem ao vídeo e a segunda depois, mediante a aplicação de um novo teste, similar ao primeiro.
| Aluno | Primeira nota (X) | Segunda nota (Y) |
|---|---|---|
| 1 | 74 | 80 |
| 2 | 64 | 74 |
| 3 | 79 | 83 |
| 4 | 90 | 92 |
| 5 | 89 | 96 |
| 6 | 94 | 98 |
| 7 | 55 | 59 |
| 8 | 75 | 77 |
| 9 | 88 | 93 |
| 10 | 66 | 78 |
| 11 | 70 | 75 |
| 12 | 60 | 59 |
| 13 | 59 | 61 |
| 14 | 67 | 70 |
| 15 | 69 | 74 |
\[
\stackrel{-}{D}=\sum_{i=1}^{n}D_{i}=-4,667
\]
\[\begin{align*} S^{2}_{D} & =\sum_{i=1}^{n}\frac{(D{i}-\stackrel{-}{D})^{2}}{n-1}=10,52354 \end{align*}\]
Sendo o valor crítico tabelado da estatística para um nível de significância \(\alpha=5\%\) e graus de liberdade \(gl=(n-1)=14\) igua a 1,761, o intervalo de confiança será:
\[\begin{align*} IC(\mu_{D})_{(1-\alpha)} & = [\stackrel{-}{D} \pm {t}_{c (n-1)} \cdot \sqrt{\frac{S_{D}^{2}}{n} } ]\\ IC(\mu_{D})_{(1-\alpha)} & = [-4,667 \pm 1,761 \cdot \sqrt{\frac{10,52354}{15} } ]\\ IC(\mu_{D})_{(1-\alpha)} & = [-5,396; -3,937] \end{align*}\]
Sendo negativos os valores desse intervalo de confinaça deduz-se que a primeira nota é menor que a segunda nota (\(X-Y < 0\)) e assim, o vídeo que os alunos assistiram melhorou sua compreensão do assunto e seu desempenho no segundo teste (similar ao primeiro). Caso o valor “zero” estivesse contemplado nesse intervalo, a interpretação seria de que não há diferença estatisticamente significativa nas notas dos alunos nos dois testes (o vídeo não os ajudou em coisa alguma).