Capítulo 5 Introdução a variáveis aleatórias
Ao realizar um experimento aleatório frequentemente estamos interessados mais em alguma função do resultado do que no próprio resultado em si:
Ao lançar dois dados, podemos estar interessados na soma “7”, sem nos importar se isso foi decorrente de (1,6),(2,5),(3,4),(4,3),(5,2) ou (6,1).
De forma semelhante, ao lançar três vezes uma moeda, podemos estar interessados no número total de “2 caras” (KK) que ocorre, sem nos preocuparmos se isso decorreu da sequência (K,K,C),(K,C,K) ou (C,K,K).
Da mesma forma, ao planejar uma família de três filhos, podemos estar interessados em ter exatamente 2 filhos do sexo masculino (MM), sem nos importar se isso resultou de (F,M,M), (M,F,M) ou (M,M,F).
Essas quantidades de interesse são formalmente tratadas no contexto do espaço de probabilidade \((\Omega, \mathcal{F}, P)\), composto por três elementos: o espaço amostral \(\Omega\), que contém todos os resultados possíveis do experimento; a \(\sigma\)-álgebra \(\mathcal{F}\), que é a coleção de todos os subconjuntos de \(\Omega\) aos quais é possível atribuir probabilidade — denominados eventos; e a medida de probabilidade \(P: \mathcal{F} \to [0,1]\), que associa a cada evento um valor em \([0,1]\).
Funções de valor real definidas sobre esse espaço, que associam cada resultado \(\omega \in \Omega\) a um número real, são conhecidas como variáveis aleatórias.
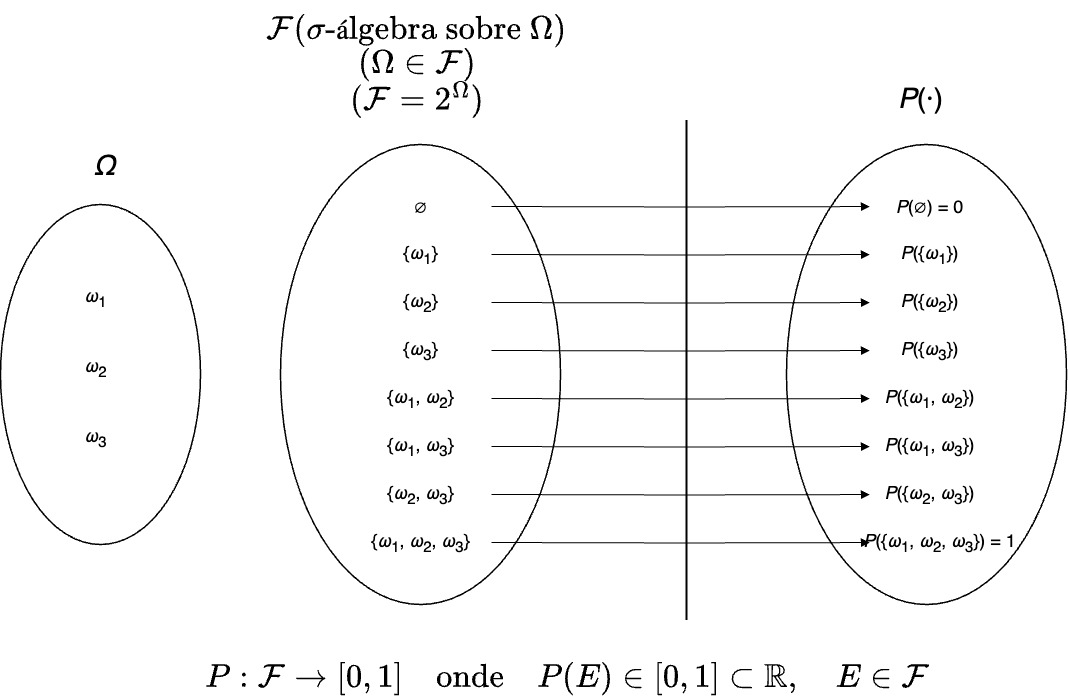
Figure 5.1: Espaço de probabilidade \((\Omega, \mathcal{F}, P)\)
De forma mais rigorosa, uma variável aleatória é uma função mensurável, geralmente representada por uma letra maiúscula (\(X\)), definida sobre o espaço de probabilidade \((\Omega, \mathcal{F}, P)\), que associa cada elemento \(\omega \in \Omega\) a um número real.
\[ X: (\Omega, \mathcal{F}) \to (\mathbb{R}, \mathcal{B}(\mathbb{R})), \quad \text{com } \mathbb{R}_{X} \subseteq \mathbb{R} \]
O domínio dessa função é o espaço amostral \(\Omega\), e seu contradomínio está contido em \(\mathbb{R}\).
Exemplo 1: considere o espaço amostral do experimento aleatório relacionado ao sexo do bebê em três gestações bem sucedidas:
\(\Omega=\{\omega_{1}:(FFF), \omega_{2}:(FFM),\omega_{3}:(FMF), \omega_{4}:(MFF),\\ \omega_{5}:(FMM), \omega_{6}:(MFM), \omega_{7}:(MMF), \omega_{8}:(MMM)\}.\)
Se estivermos interessados no número de nascimentos do sexo masculino, podemos definir a função \(X\) para associar cada elemento \(\omega_{i}\) em \(\Omega\) a um valor \(x_{i} \in \mathbb{R}\) que apresentará os seguintes resultados:
\(X(FFF)=0; X(FFM)=1; X(FMF)=1; X(MFF)=1;\\ X(FMM)=2; X(MFM)=2; X(MMF)=2; X(MMM)=3\)
\(\mathbb{R}_{X}=\{x_{1}=0; x_{2}=1; x_{3}=2; x_{4}=3\}\subseteq \mathbb{R}\)
Exemplo 2: considere o espaço amostral do experimento aleatório relacionado à sobrevivência de paciente ao final de 1 dia em uma UTI com quatro leitos:
\(\Omega=\{(0,0,0,0),(0,0,0,1),(0,0,1,0),(0,0,1,1),\\ (0,1,0,0),(0,1,0,1),(0,1,1,0),(0,1,1,1),(1,0,0,0),\\ (1,0,0,1),(1,0,1,0),(1,0,1,1),(1,1,0,0),(1,1,0,1),\\ (1,1,1,0),(1,1,1,1)\}.\)
Cada elemento do espaço amostral é uma sequência de quatro valores binários \((b_{1},b_{2},b_{3},b_{4})\), onde: \(b_{i}=0\) indica que o paciente no leito \(i\) sobreviveu e \(b_{i}=1\) caso contrário.
Se estivermos interessados no número de falecimentos podemos definir a função \(X\) para associar cada elemento \(\omega_{i}\) em \(\Omega\) a um valor \(x_{i} \in \mathbb{R}\) que apresentará os seguintes resultados:
\(X(0000)=0; X(0001)=1; X(0010)=1; \dots ; X(1111)=4\)
\(\mathbb{R}_{X}=\{x_{1}=0; x_{2}=1; x_{3}=2; x_{4}=3; x_{5}=4\} \subseteq \mathbb{R}\)
5.1 Variáveis aleatórias discretas e contínuas
A depender do experimento aleatório podemos propor variáveis aleatórias discretas ou contínuas:
Os valores possíveis de uma variável aleatória discreta pertencem a um conjunto finito ou infinito enumerável, como \(\{0,1,2, \dots \}\). Exemplos incluem: o número de acidentes em uma semana; o número de partículas αα emitidas por uma fonte radioativa em um intervalo de tempo; ou o número de casos de uma doença em um mês.
Os valores possíveis de uma variável aleatória contínua pertencem a um intervalo contínuo de números reais, como \([a,b]\), \([0,\infty)\) ou \((-\infty, \infty)\). Exemplos incluem: o peso ou a altura de um grupo de pessoas; o tempo de vida de uma lâmpada; o tempo de reação a um estímulo; a concentração de álcool em um certo volume de sangue, a temperatura mínima no inverno Antártico.
5.2 Função massa de probabilidade (Probability Mass Function - PMF)
Considere \(X\) uma variável aleatória discreta e seus valores possíveis \(X:\{x_{1},x_{2},x_{3}, \dots x_{n} \dots\}\).
Uma função (de distribuição) de probabilidade \(f(x)\) é assim denominada quando, aplicada a cada um dos possíveis valores \(x_{i}\) que a variável aleatória \(X\) assume, entregar a probabilidade de sua ocorrência: para \(x = x_{i}\), \(f(x_{i}) = P(X=x_{i})=p(x{i})\).
Desse modo, sendo \(f(x)\) uma função de distribuição de probabilidade, ela precisa necessariamente atender às seguintes condições:
Postulado do intervalo:
\[ 0 < f(x_{i}) < 1 \]
para qualquer \(x_{i} \in \mathcal{R}_{X}\), onde \(\mathcal{R}_{X}\) é o contradomínio de \(X\).
Postulado do evento certo:
\[ \sum _{i=1}^{n}f\left(x_{i}\right) = 1. \]
Equivale afirmar que a probabilidade de ocorrência de um dos valores que a variável aleatória pode assumir está sempre compreendida no intervalo \(0 \leq P(X = x_{i}) \leq 1\). E mais, que a soma das probabilidades de todos os possíveis valores de \(X\) será 1.
Observação: somente se a soma acma for finita há a posibilidade de se ter probabilidades \(p(x_{i})\) iguais para todos \(x_{i}\)
Exemplo: Suponha que uma moeda seja lançada duas vezes e que \(X\) seja a variável aleatória que represente o número de \(caras\) verificado. Defina o espaço amostral, associe para cada evento possível o valor da variável aleatória e definda uma função discreta de probabilidade correspondente.
O espaço amostral desse experimento é S = {(cara,cara), (cara,coroa), (coroa,cara), (coroa,coroa)} e a tabela abaixo relaciona o número de caras (o valor da variável aleatória \(X\)) associado a cada evento possível desse experimento:
| Ponto amostral | (cara,cara) | (cara,coroa) | (coroa,cara) | (coroa,coroa) |
|---|---|---|---|---|
| X | 2 | 1 | 1 | 0 |
As probabilidades de ocorrência de cada um desses eventos é:
\[\begin{align*} P(cara,cara) & = \frac{1}{4} \\ P(cara,coroa) & = \frac{1}{4}\\ P(coroa,cara) & = \frac{1}{4} \\ P(coroa,coroa) & = \frac{1}{4}\\ \end{align*}\]
Para definir uma função discreta de distribuição de probabilidade deveremos associar a cada valor que a variável aleatória \(X\) assume sua correspondente probabilidade de ocorrência.
\[\begin{align*} P(X=0) & = P(coroa,coroa) = \frac{1}{4} \\ P(X=1) & = P[(cara,coroa) \cup (coroa,cara)] \\ & = P(cara,coroa) + P(coroa,cara)\\ & = \frac{1}{4} + \frac{1}{4} \\ & = \frac{1}{2} \\ P(X=2) & = P(cara,cara) = \frac{1}{4} \end{align*}\]
| xk | 0 | 1 | 2 |
|---|---|---|---|
| P(X = xk) = f(xk) | 1/4 | 1/2 | 1/4 |
# Valores possíveis para o número de caras
x <- c(0, 1, 2)
# Probabilidades associadas (calculadas com o modelo binomial)
p <- c(0.25, 0.5, 0.25)
# Criando o gráfico de barras
barplot(
p,
names.arg = x,
xlab = "x",
ylab = expression(f(x)),
col = "gray",
ylim = c(0, 1),
main = "Probabilidade de observar caras ao lançar 2 moedas"
)
# Adicionando linhas no eixo y para reforçar a interpretação
abline(h = seq(0, 1, by = 0.25), col = "lightgray", lty = 2)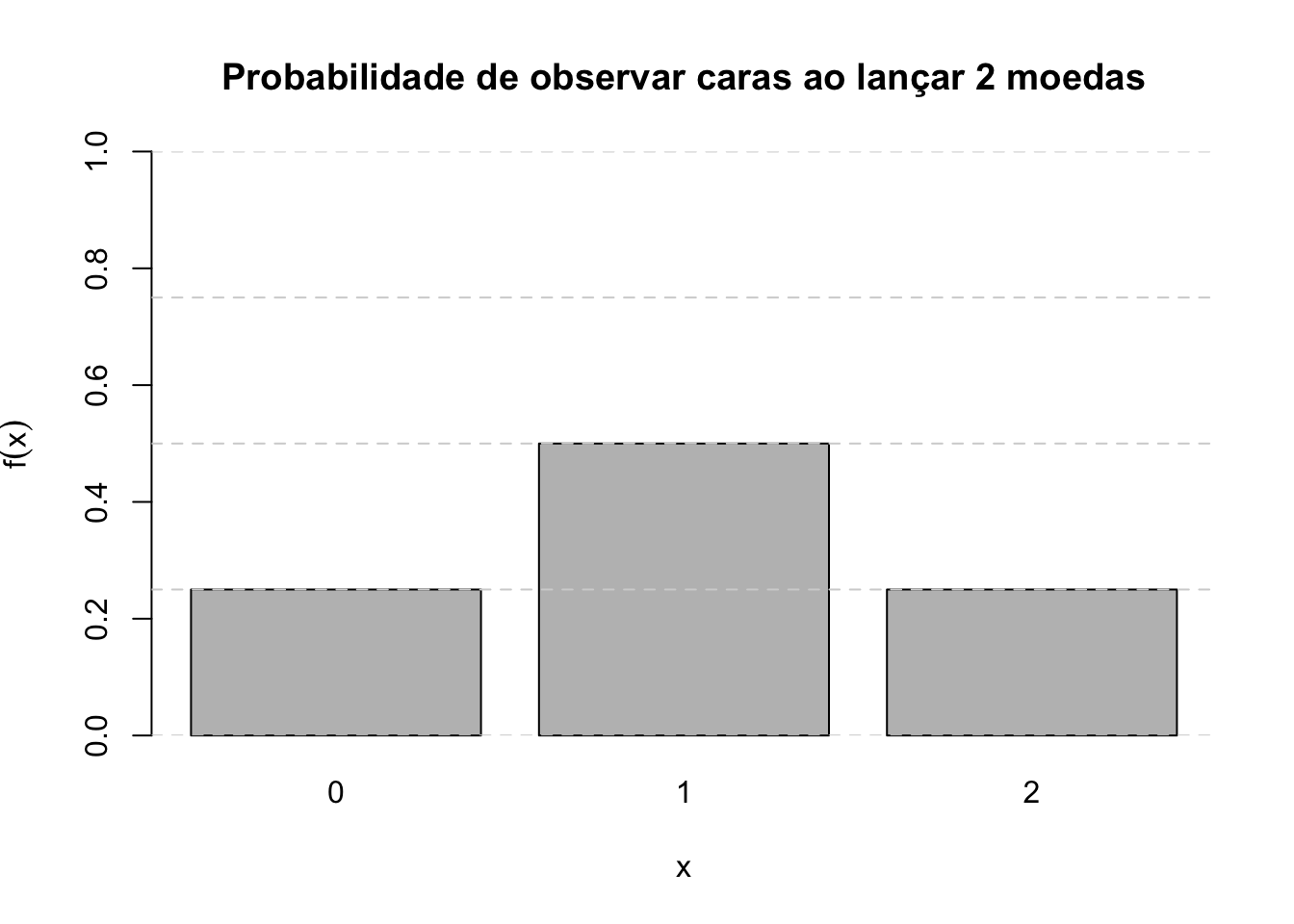
5.3 Função cumulativa de probabilidade
Uma função de distribuição cumulativa \(F(x)\) para uma variável aleatória \(X\) exprime a probabilidade de que a variável aleatória \(X\) assuma um valor menor ou igual a determinado \(x\) , sendo definida por:
\[ F(x) = P(X \leq x) \]
Propriedades:
1- \(0 \leq F(x) \leq 1\) (os valores da função estão no intervalo de probabilidade);
2- \(F(x)\) é não decrescente: \(F(x) \leq F(y)\) se \(x \leq y\) (a probabilidade cumulativa nunca diminui);
- \(F(- \infty) = \underset{x\to -\infty }{lim}F\left(x\right)=0\) (a probabilidade cumulativa no limite inferior é zero);
4- \(F(+ \infty) = \underset{x\to \infty }{lim}F\left(x\right)=1\) (a probabilidade cumulativa no limite superior é um).
Relação com a Função de Probabilidade:
Para uma variável aleatória discreta \(X\), a função massa de probabilidade \(f(x)\) pode ser derivada da função de distribuição cumulativa \(F(x)\). Especificamente, para todo \(x\) em \((-\infty, \infty)\)):
\[
f(x) = P(X = x) = F(x) - F(x^-),
\]
onde \(F(x^-)\) é o valor de \(F(x)\) imediatamente antes de \(x\), considerando a natureza discreta da variável.
Além disso, a definição cumulativa da função \(F(x)\) para valores discretos \(x\) pode ser escrita como:
\[ F\left(x\right)=P\left(X\le x\right)=\sum _{u\le n}f\left(u\right), \]
em que \(u\) são os valores possíveis da variável aleatória \(X\). Equivale dizer que é a soma sobre todos os valores \(u\) assumidos por \(X\) para os quais \(u \leq x\).
Se \(X\) é discreta e assume um número finito de valores \(x_{1},x_{2}, \dots, x_{n}\), então sua função de probabilidade cumulativa \(F(x)\) será dada por:
\[ F(x) = \begin{cases} 0, & \text{se } -\infty < x < x_{1}, \\ f(x_{1}), & \text{se } x_{1} \leq x < x_{2}, \\ f(x_{1}) + f(x_{2}), & \text{se } x_{2} \leq x < x_{3}, \\ \vdots & \\ f(x_{1}) + f(x_{2}) + \dots + f(x_{n}), & \text{se } x_{n} \leq x < \infty. \end{cases} \]
Essa expressão mostra que \(F(x)\) é obtida pela soma cumulativa das probabilidades associadas aos valores discretos de \(X\), até um ponto \(x\).
Exemplo: Suponha que uma moeda seja lançada duas vezes e que \(X\) seja a variável aleatória que represente o número de caras verificado. Especifique sua função de probabilidade cumulativa dessa variável aleatória e apresente seu gráfico.
| xk | 0 | 1 | 2 |
|---|---|---|---|
| P(X = xk) = f(xk) | 1/4 | 1/2 | 1/4 |
Sua função de probabilidade cumulativa é dada por:
O gráfico de sua função de probabilidade cumulativa é:
# Valores possíveis para o número de caras
x <- c(0, 1, 2)
# Probabilidades associadas (calculadas com o modelo binomial)
p <- c(0.25, 0.5, 0.25)
# Probabilidade acumulada
p_cumulative <- cumsum(p)
# Criando o gráfico de probabilidade acumulada com linhas verticais
plot(
x,
p_cumulative,
type = "s", # Tipo "steps" para probabilidade acumulada
xlab = "x",
ylab = expression(F(x)),
ylim = c(0, 1),
xlim = c(0, 3), # Expandido para incluir margens
main = "Função de distribuição acumulada (CDF)",
col = "blue",
lwd = 2,
axes = FALSE # Desabilita os eixos padrão para customização
)
# Adicionando linhas verticais para conectar os valores
segments(
x0 = x[-1], # Exclui o primeiro valor (X=0)
y0 = c(0, p_cumulative[-length(p_cumulative)])[-1], # Exclui o valor inicial (F(0))
x1 = x[-1],
y1 = p_cumulative[-1], # Exclui o valor inicial (F(0))
col = "red",
lty = 2 # Linhas tracejadas
)
# Adicionando bolinhas abertas nos limites inferiores (apenas X > 0)
points(x[-1], c(0, p_cumulative[-length(p_cumulative)])[-1], pch = 1, col = "blue", cex = 1.5)
# Adicionando bolinhas fechadas no limite superior de cada degrau
points(x, p_cumulative, pch = 16, col = "blue", cex = 1.5)
# Customizando o eixo X
axis(1, at = 0:3, labels = 0:3)
# Customizando o eixo Y com frações
axis(2, at = c(0, 0.25, 0.5, 0.75, 1), labels = c("0", "1/4", "1/2", "3/4", "1"), las = 1)
# Adicionando grades para facilitar a interpretação
grid(nx = NULL, ny = NULL, col = "lightgray", lty = "dotted")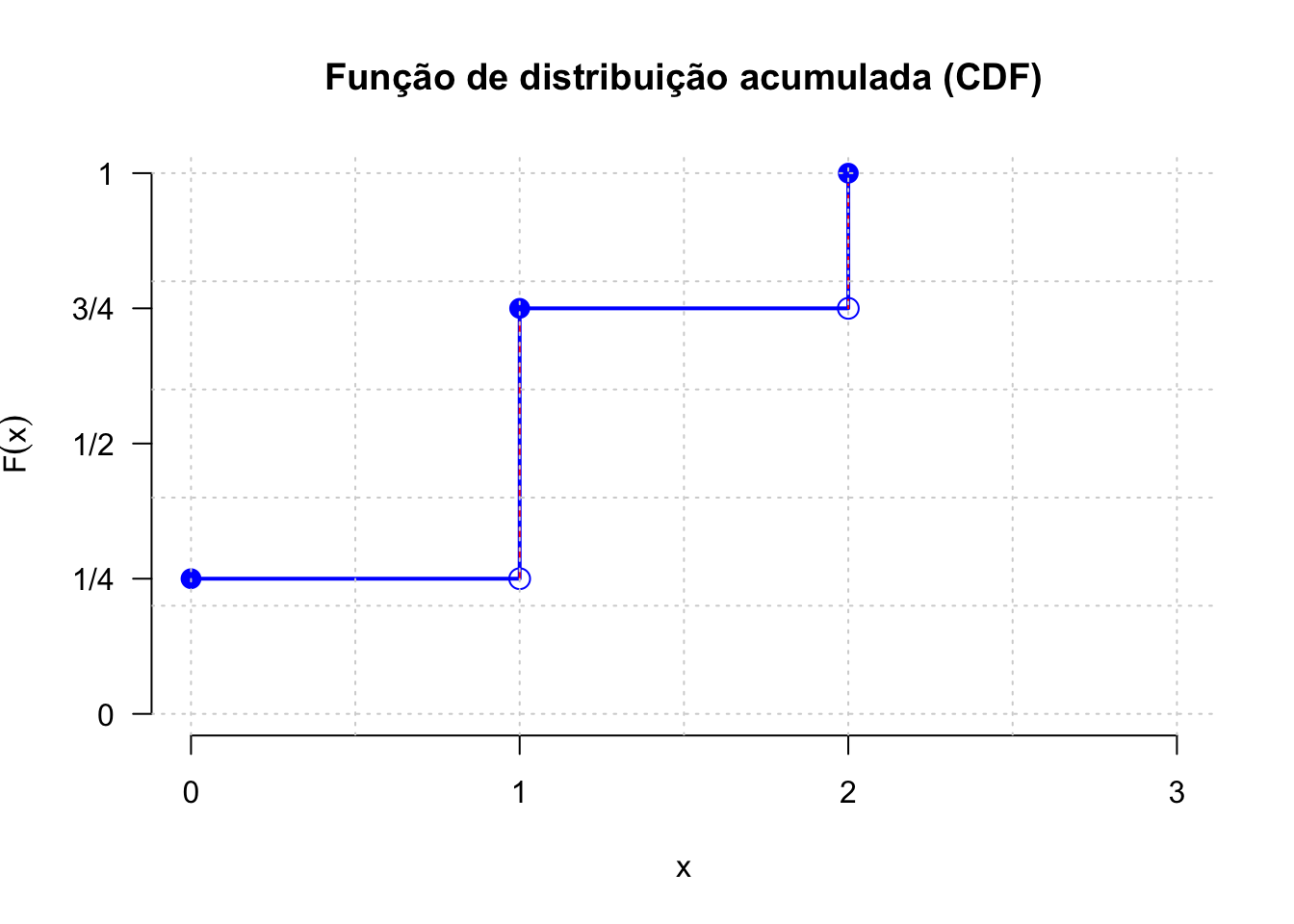
5.4 Função de densidade de probabilidade (Probability Density Function - PDF)
Considerem que os cinco alvos da imagem abaixo sejam como que espaços amostrais (\(\Omega_{1},\dots \Omega_{5}\)) representativos de 5 experimentos aleatórios nos quais uma pessoa irá atirar um dardo.
Admitam também também esses espaços amostrais seja equiprováveis.
Admitam o último deles como um espaço amostral formado por \(\to\infty\) pontos.
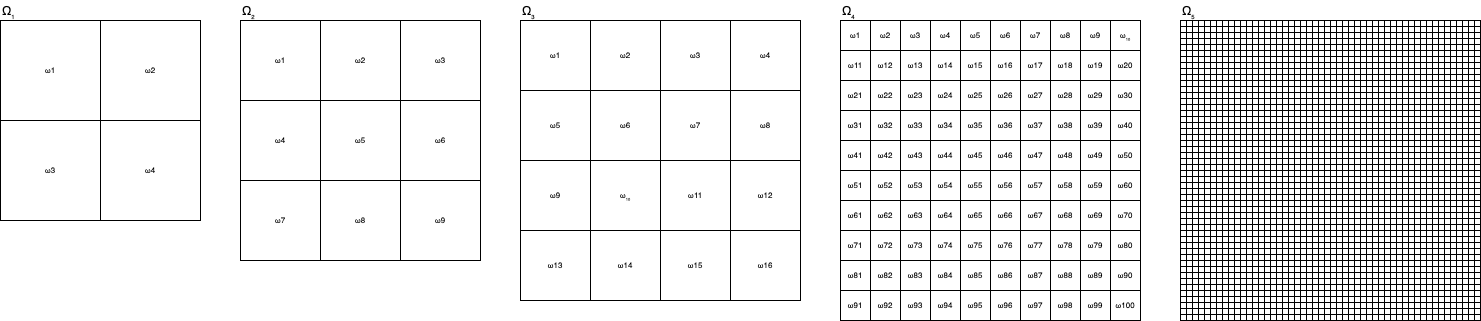
Figure 5.2: Diferentes espaços amostrais de um experimento aleatório.
Nos primeiros experimentos a probabilidade do arqueiro acertar especificamente um dos dos possíveis quadradinhos (.) parece ser bastante alta.
Mas últimos experimentos, a probabilidade do arqueiro acertar especificamente um dos dos possíveis quadradinhos (.) é sensivelmente menor.
Um espaço amostral com a característica do último pode bem representar um experimento aleatório continuo.
Sendo todos os eventos representados nos espaços amostrais equiprováveis, comparemos as probabilidades associadas a cada um desses possíveis resultados.
Em \(\Omega_{1}\), \(P(\omega_{.})=0,25\)
Em \(\Omega_{2}\), \(P(\omega_{.})=0,111\)
Em \(\Omega_{3}\), \(P(\omega_{.})=0,0625\)
Em \(\Omega_{4}\), \(P(\omega_{.})=0,01\)
Em \(\Omega_{5}\), \(P(\omega_{.}) \rightarrow 0\), à medida que o número de eventos \(n \rightarrow \infty\)
A probabilidade individual de qualquer evento do quinto espaço amostral ocorrer \(\rightarrow 0\).
Por essa razão, no caso de variáveis aleatórias contínuas, não faz sentido falar em uma probabilidade pontual exata, associada a um resultado específico. Isso ocorre porque, para qualquer valor particular, a probabilidade é sempre igual a zero.
Experimentos aleatórios nos quais os possíveis resultados assumem valores resultantes de processos de mensuração tais como, por exemplo, rendas, pesos, velocidades, tempos, comprimentos, pertencentes aos números Reais, podem ser adequadamente modelados por variáveis aleatórias contínuas.
Para estes uma função densidade de probabilidade (\(f(x)\)) é definida de modo a retornar a probabilidade de ocorrência associada a um intervalo de valores, posto a probabilidade de ocorrência de um valor aleatório contínuo específico \(x\) tender a zero: \(P(X=x) \to 0\).
A função \(f(x)\) é uma função densidade de probabilidade para a variável aleatória contínua \(X\) se atende às seguintes condições relacionadas aos axiomas da probabilidade:
1- \(f(x) \geq 0\), para todo \(x \in (-\infty, \infty)\);
2- A integral da função sobre todo o domínio é igual a 1:
\[ \underset{-\infty }{\overset{\infty }{\int }}f\left(x\right)dx = 1 \].
Sendo \(f(x)\) a função densidade de probabilidade da variável aleatória contínua \(X\), a probabilidade de \(X\) assumir valores em um intervalo de valores: \(a\) e \(b\) (\(b>a\)) será dada por:
\[ P(a < X < b) = \int_{a}^{b} f(x) \, dx. \]
Graficamente, a interpretação de uma função densidade de probabilidade contínua é representada pela área sob a curva da função \(f(x)\), delimitada pelos valores de interesse da variável aletatória \(X\)r.
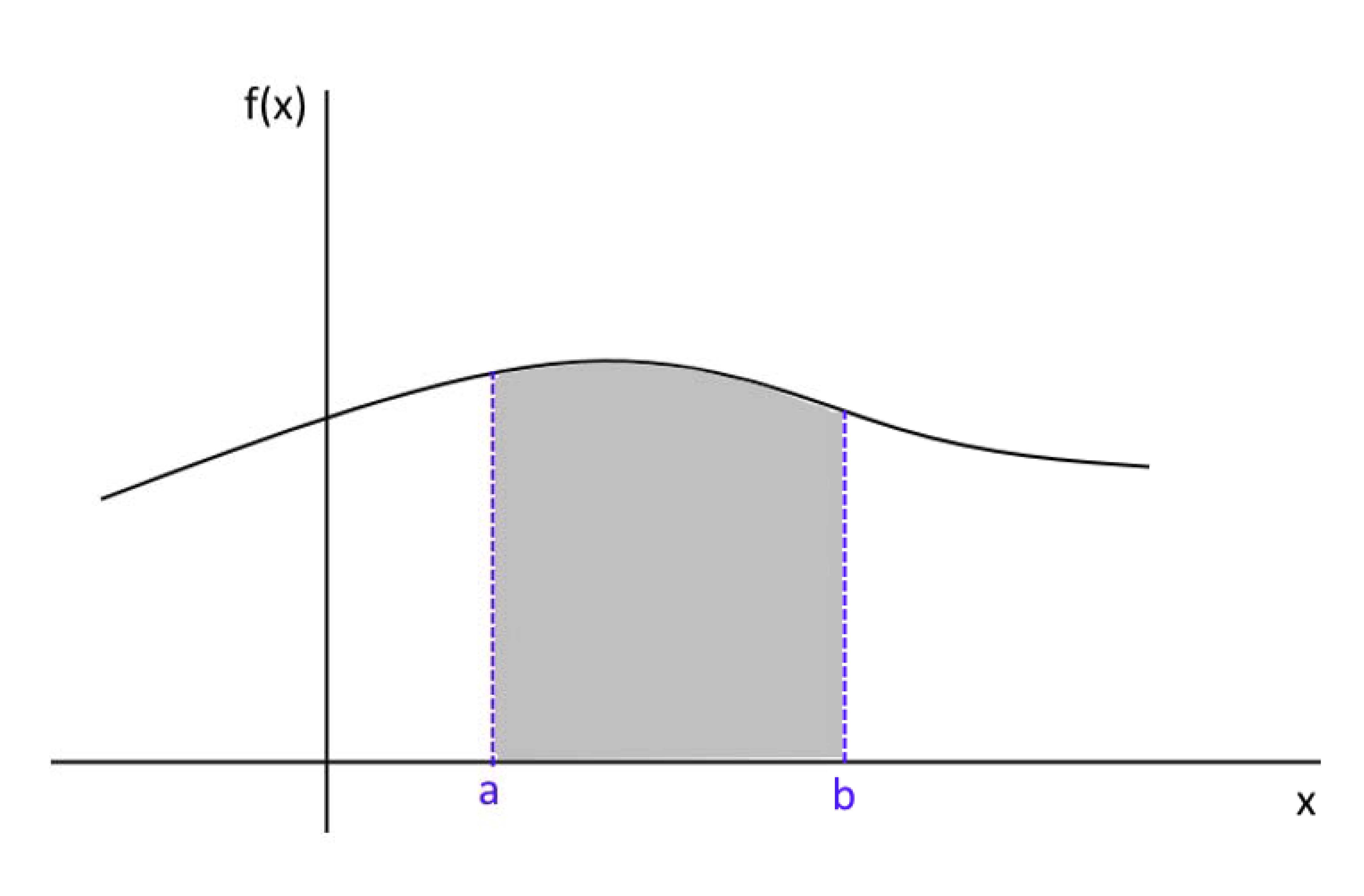
Figure 5.3: A área sob a curva de uma função de probabilidade de uma variável contínua entre dois valores quaisquer é a probabilidade de se observar valores entre esses dois pontos
Se admitirmos \((a \leq X \leq b)\) temos que a área será igual a um (1) posto estarmos calculando a probabilidade do espaço amostral de \(X\), o intervalo \((a, b)\).
De modo geral,
\[ \underset{-\infty }{\overset{\infty }{\int }}f\left(x\right)dx = 1. \]
Para estes uma função densidade de probabilidade é definida de modo a retornar a probabilidade de ocorrência associada a um intervalo de valores, posto a probabilidade exata de ocorrência de um valor aleatório contínuo específico \(x\) tender a zero \(P(X=x) \to 0\).
A função \(f(x)\) é uma função densidade de probabilidade para a variável aleatória contínua \(X\) se atende às seguintes condições relacionadas aos axiomas da probabilidade:
Para tornar o conceito de densidade mais compreensível admita a função densidade de probabilidade (fdp) a seguir e sua representação gráfica na Figura 5.4
\[ f(X=x)= \begin{cases} 2 . x \hspace{0.6cm} \text{para } 0 \le x \le 1 \\ 0, \hspace{0.9cm} \text{para qualquer outro x}\\ \end{cases} \]
![A área definida por (ODA) equivale à probabilidade de $f(X=x)$ no intervalo $0 \le x \le 0,50$ é notadamente menor que a área definida por (ABCD) equivalente à probabilidade de $f(X=x)$ no intervalo $0,5 \le x \le 1$. Tendo os intervalos [0;0,50] e [0,50; 1,00] igual amplitude, depreende-se que uma fdp é uma função indicadora da concentração massa (probabilidade) nos possíveis valores de $X$](images5/massa.jpg)
Figure 5.4: A área definida por (ODA) equivale à probabilidade de \(f(X=x)\) no intervalo \(0 \le x \le 0,50\) é notadamente menor que a área definida por (ABCD) equivalente à probabilidade de \(f(X=x)\) no intervalo \(0,5 \le x \le 1\). Tendo os intervalos [0;0,50] e [0,50; 1,00] igual amplitude, depreende-se que uma fdp é uma função indicadora da concentração massa (probabilidade) nos possíveis valores de \(X\)
A função de distribuição cumulativa, definida como \(F(x) = P(X \leq x)\), também terá a forma de uma curva, crescente, que aumenta continuamente de \(0\) para \(1\). Essa característica reflete o fato de que, ao longo do eixo \(x\), a probabilidade cumulativa acumula todos os valores de \(f(x)\) até \(x\), de modo que:
- \(F(x)\) é não decrescente (\(F(x_1) \leq F(x_2)\) para \(x_{1} \leq x_{2}\));
- \(F(x)\) atinge valores-limite:
\[ \lim_{x \to -\infty} F(x) = 0 \quad \text{e} \quad \lim_{x \to \infty} F(x) = 1. \]
Assim, \(F(x)\) descreve graficamente a probabilidade acumulada até qualquer valor \(x\), reforçando a relação entre a densidade de probabilidade e a probabilidade cumulativa.
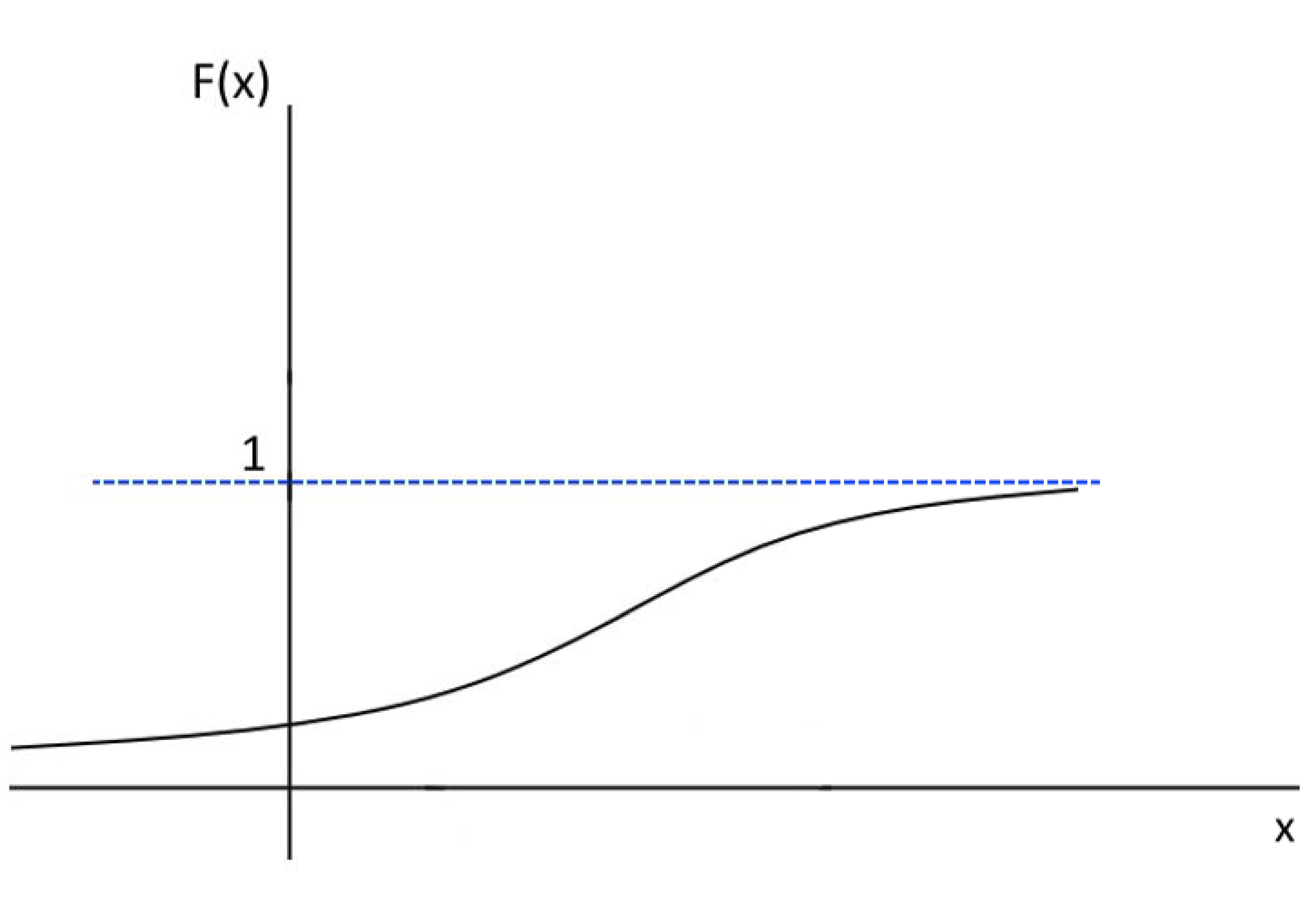
Figure 5.5: Função de probabilidade cumulativa
Exemplo: Seja a seguinte função e verifique se a função \(f(x)\) pode ser a função de densidade de probabilidade da variável aleatória contínua \(X\) e determine qual a probabilidade associada a valores compreendidos no intervalo \(0 \leq X \leq \frac{1}{2}\).
A resolução deste exemplo será feita de um modo geométrico.
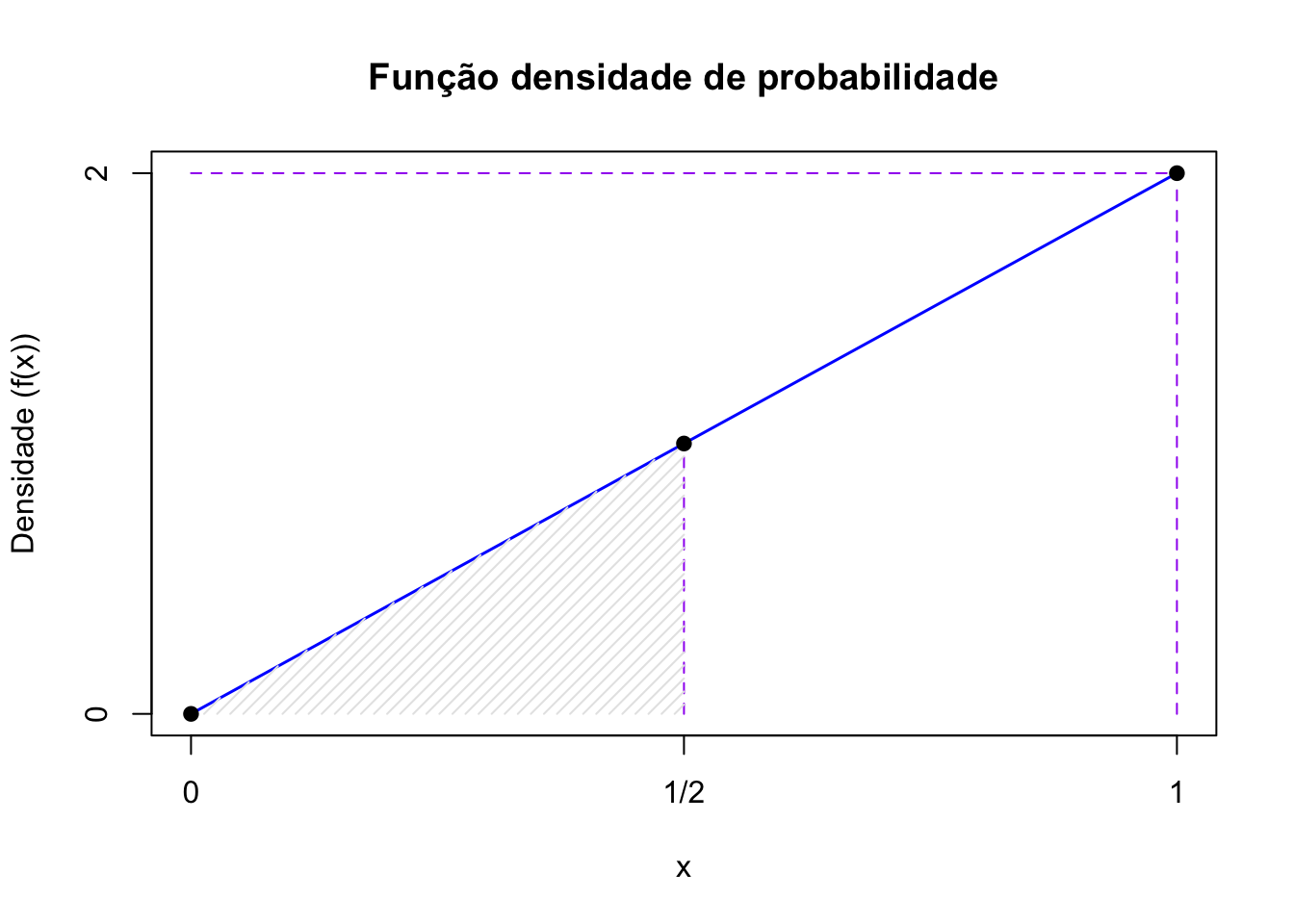
Figure 5.6: A probabilidade de se observar valores entre 0 e 1/2 é igual à area sob a função densidade de probabilidade entre esses dois valores
- Verificações para se aceitar a função como uma função de densidade de probabilidade para a variável aleatória \(X\):
\[ f(x) \geq 0 \]
e,
\[ \underset{-\infty }{\overset{\infty }{\int }}f\left(x\right)dx = 1 \]
Resp.: Atende às duas condições (não assume valores menores que zero e a área sob a reta dessa função é unitária)
- Cálculo da probabilidade para o intervalo \(0 \leq X \leq \frac{1}{2}\) a partir da área do triângulo hachurado (\(\frac{base \times altura}{2}\)):
\[ P ( 0 \leq X \leq \frac{1}{2}) = \frac{1}{2} \times (\frac{1}{2} \times 1 ) = \frac{1}{4} \]
Exemplo: Verifique se as funções a seguir atendem os pressupostos necessários para ser uma função densidade de probabilidade (assuma que toda \(f(x)=0\) para valores fora dos intervalos especificados):
1- \(f(x)=3x\) para \(0 \le x \le 1\);
2- \(f(x)=\frac{x^{2}}{2}\) para \(x \ge 0\);
3- \(f(x) = \frac{(x-3)}{2}\) para \(3 \le x \le 5\);
4- \(f(x)=2\) para \(0 \le x \le 2\);
5-
\[ f(X=x)= \begin{cases} \frac{(2+x)}{4}, \hspace{0.6cm} \text{para } -2 \le x \le 0 \\ \frac{(2-x)}{4}, \hspace{0.6cm} \text{para } 0 \le x \le 2\\ \end{cases} \] 6- \(f(x)=- \pi\) para \(-\pi < x < 0\)
Os gráficos das funções densidade de probabilidade são:
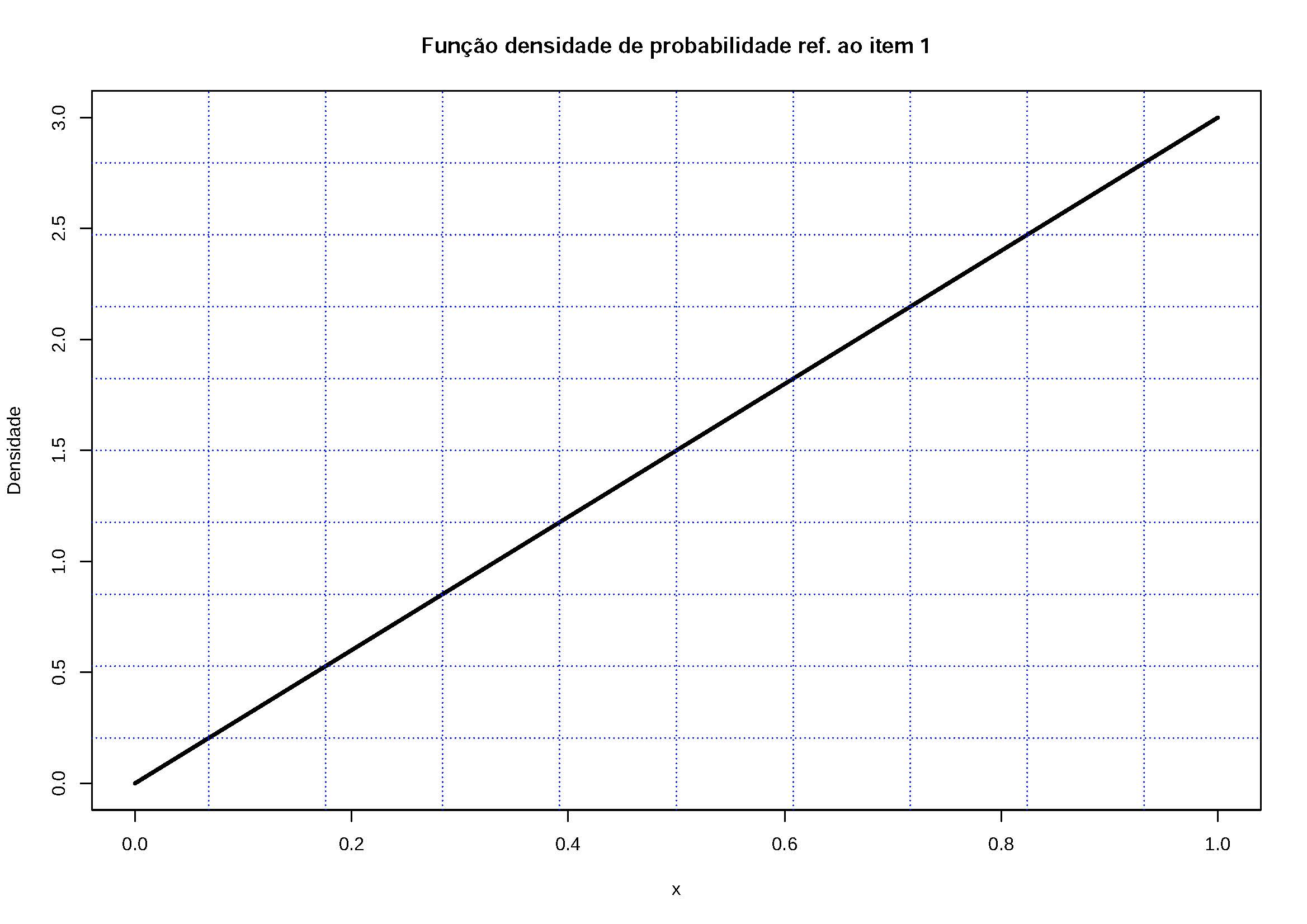
Figure 5.7: A área definida por \(f(x)\) no intervalo \(0 \le x \le 1\) é maior que 1. Por essa razão não pode ser uma fdp

Figure 5.8: A área definida por \(f(x)\) no intervalo \(x \ge 0\) é maior que 1. Por essa razão não pode ser uma fdp
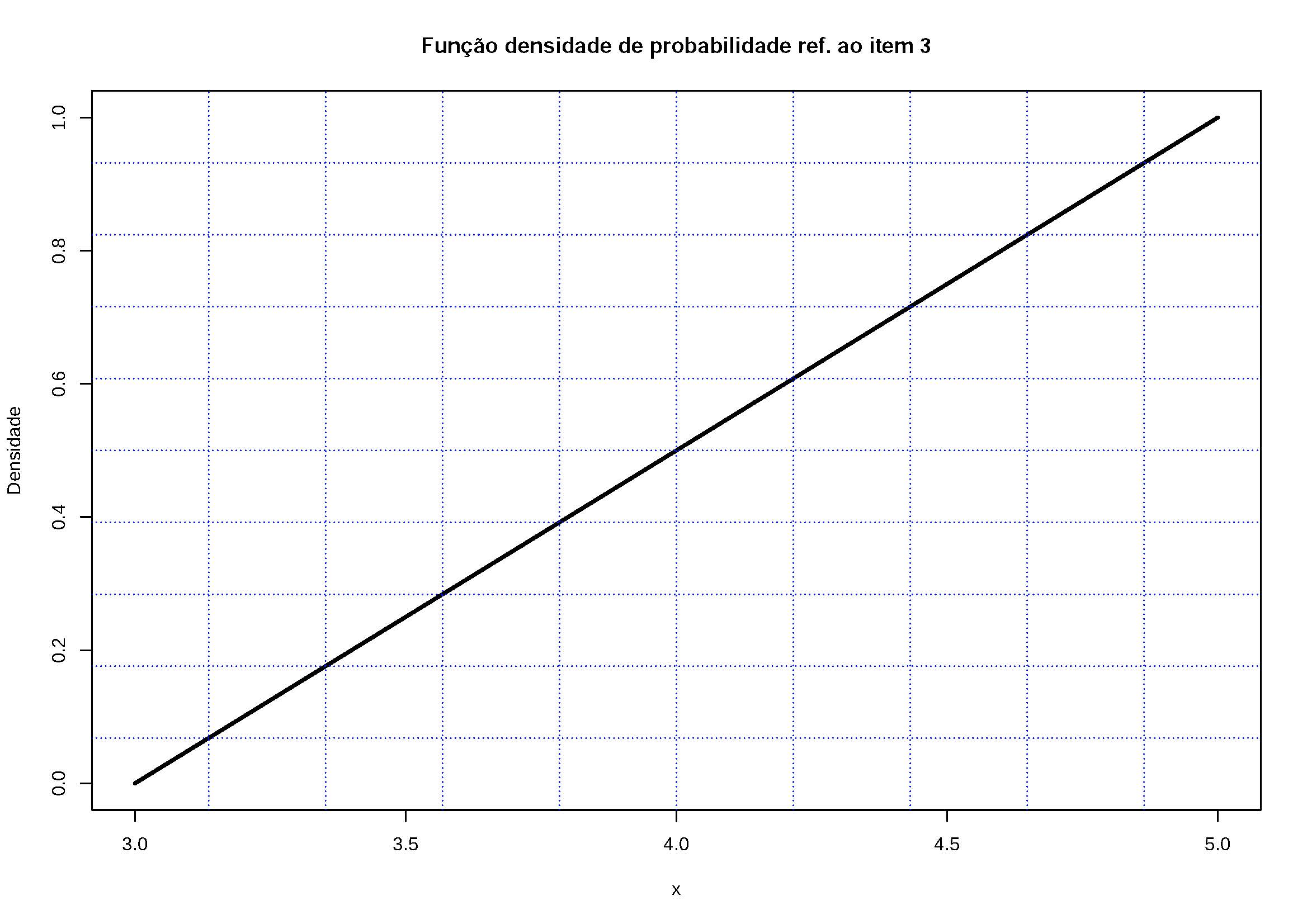
Figure 5.9: Os valores assumidos por \(f(x)\) são \(\ge 0\) e a área definida por f(x) o intervalo \(3 \le x \le 5\) é igual a 1. Por essa razão pode ser uma fdp
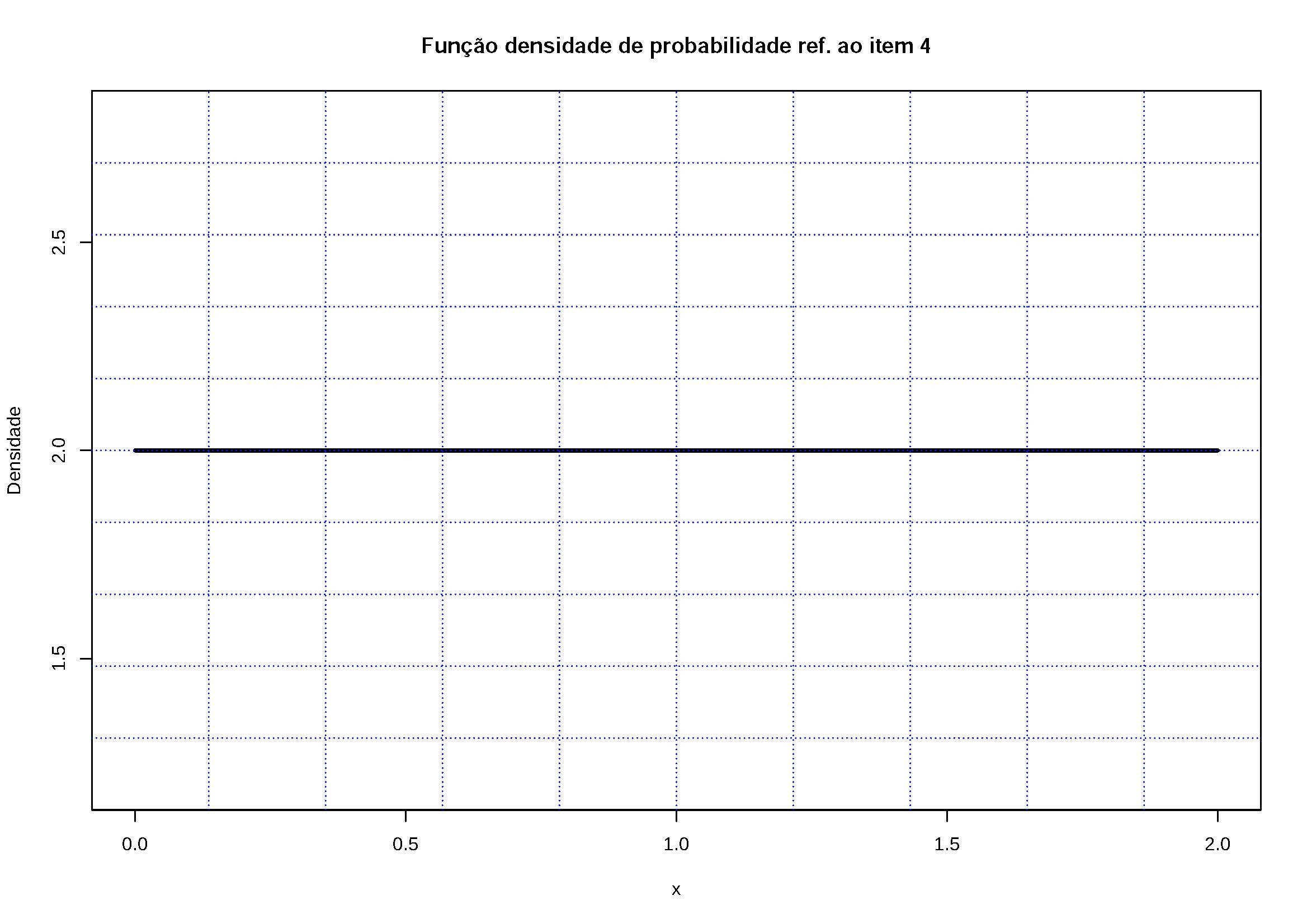
Figure 5.10: A área definida por \(f(x)\) no intervalo \(0 \le x \le 2\) é maior que 1. Por essa razão não pode ser uma fdp
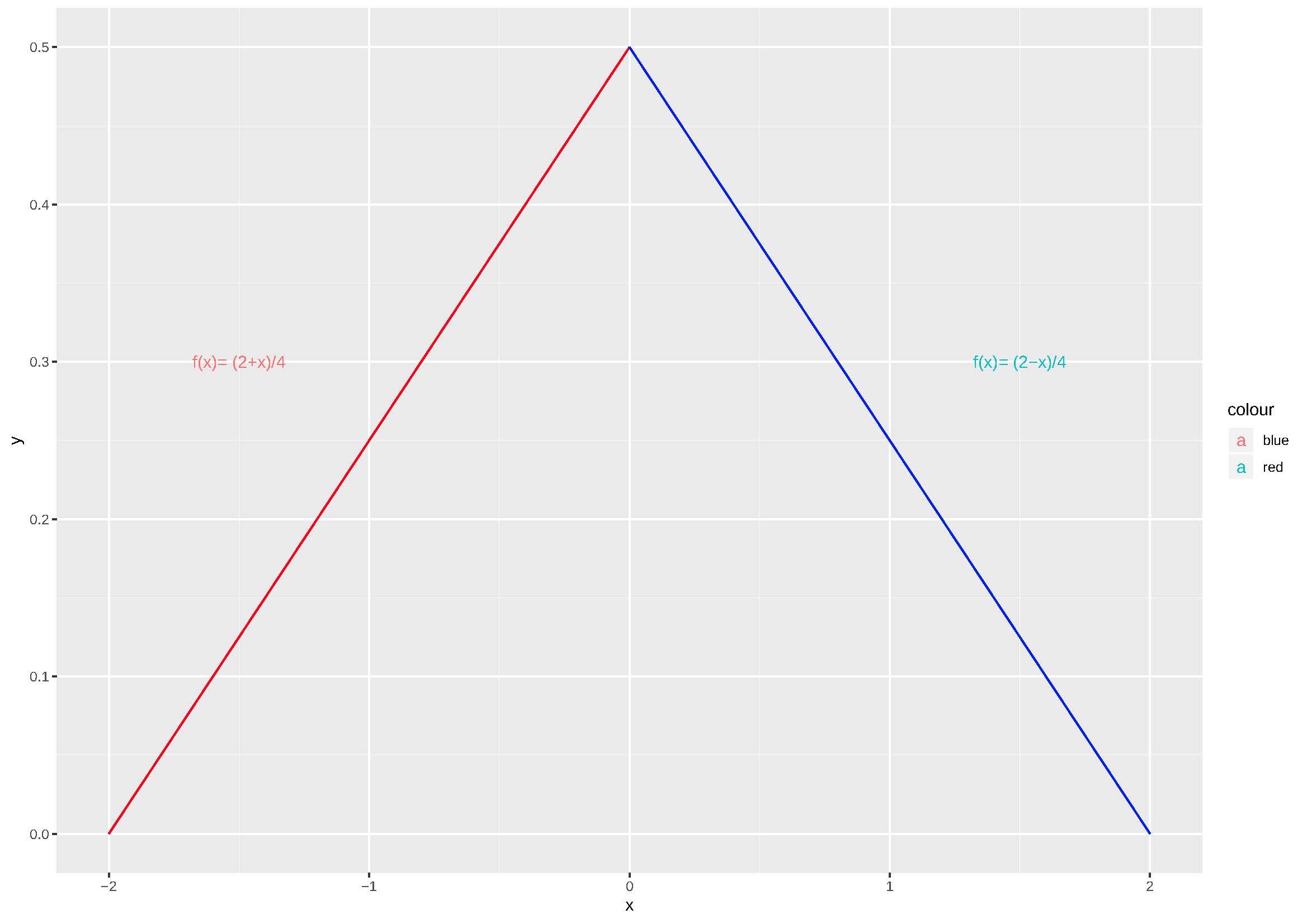
Figure 5.11: Os valores assumidos por \(f(x)\) são \(\ge 0\) e a área definida por \(f(x)\) nos intervalos \(-2 \le x \le 0\) e \(0 \le x \le 2\) é igual a 1. Pode ser uma fdp
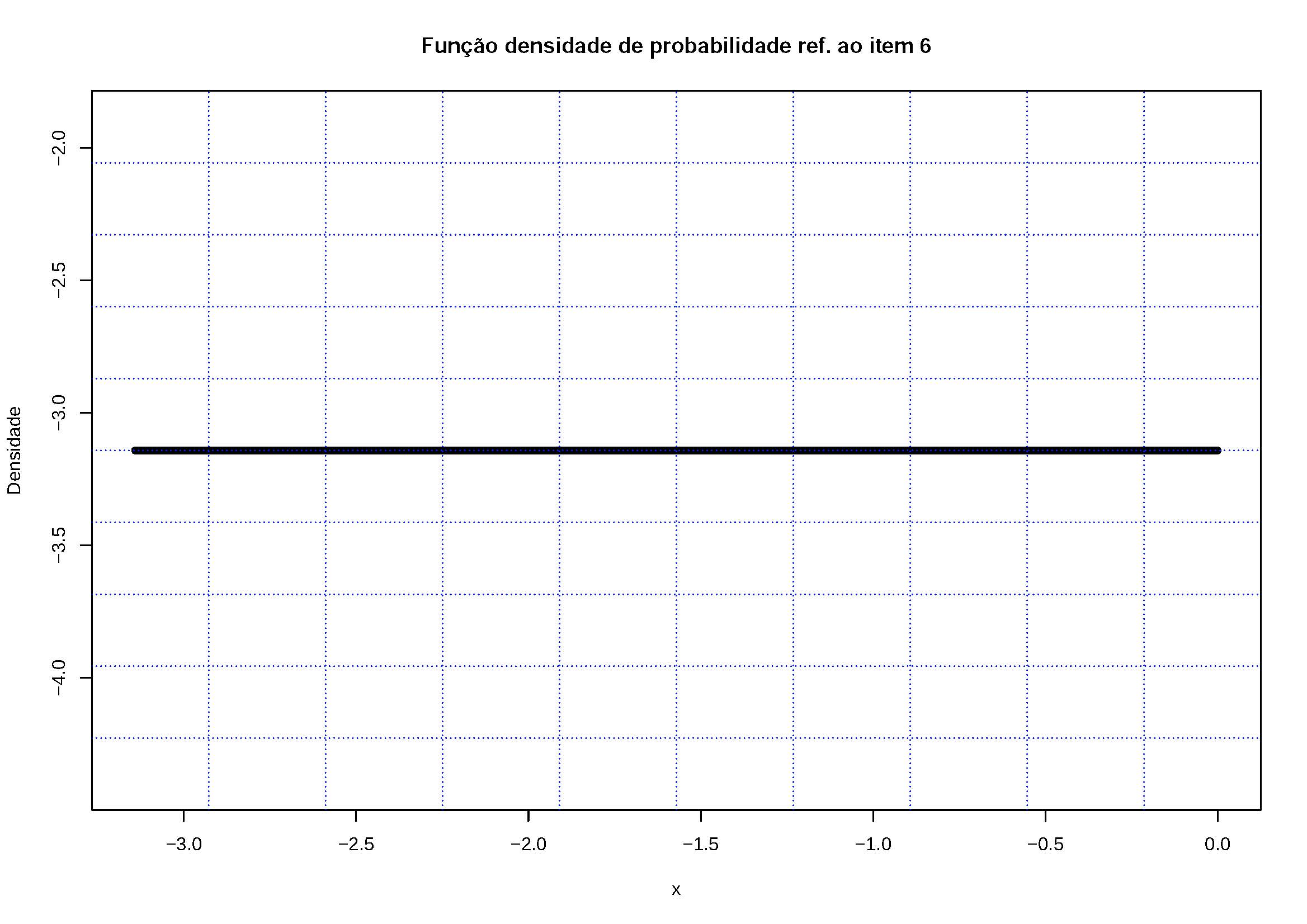
Figure 5.12: Os valores assumidos por f(x) são \(<0\). Por esa razão não pode ser uma fdp.
Exemplo: A dureza \(X\) de uma peça de aço pode ser entendida como sendo uma variável aleatória contínua uniforme no intervalo \((50,70)\) da escala Rockwel. Calcule a esperança e a variâcia dessa variável aleatória e a probabilidade de que uma peça tenha dureza entre 55 e 60?
Definindo a variável aleatória contínua \(X:X \sim U(50,70)\):
\[ f(X=x)= \begin{cases} \frac{1}{70-50}=\frac{1}{20}, \hspace{0.6cm} \text{para } 50 \le x \le 70 \\ 0, \hspace{1cm} \text{para qualquer outro x}\\ \end{cases} \]
Sua esperança e a variância são:
- Esperança: \(E(X) = \mu = \frac{(70+50)}{2}=60\); e,
- Variância: \(Var(X) = \frac{(70-50)^{2} }{12}=33,33\).
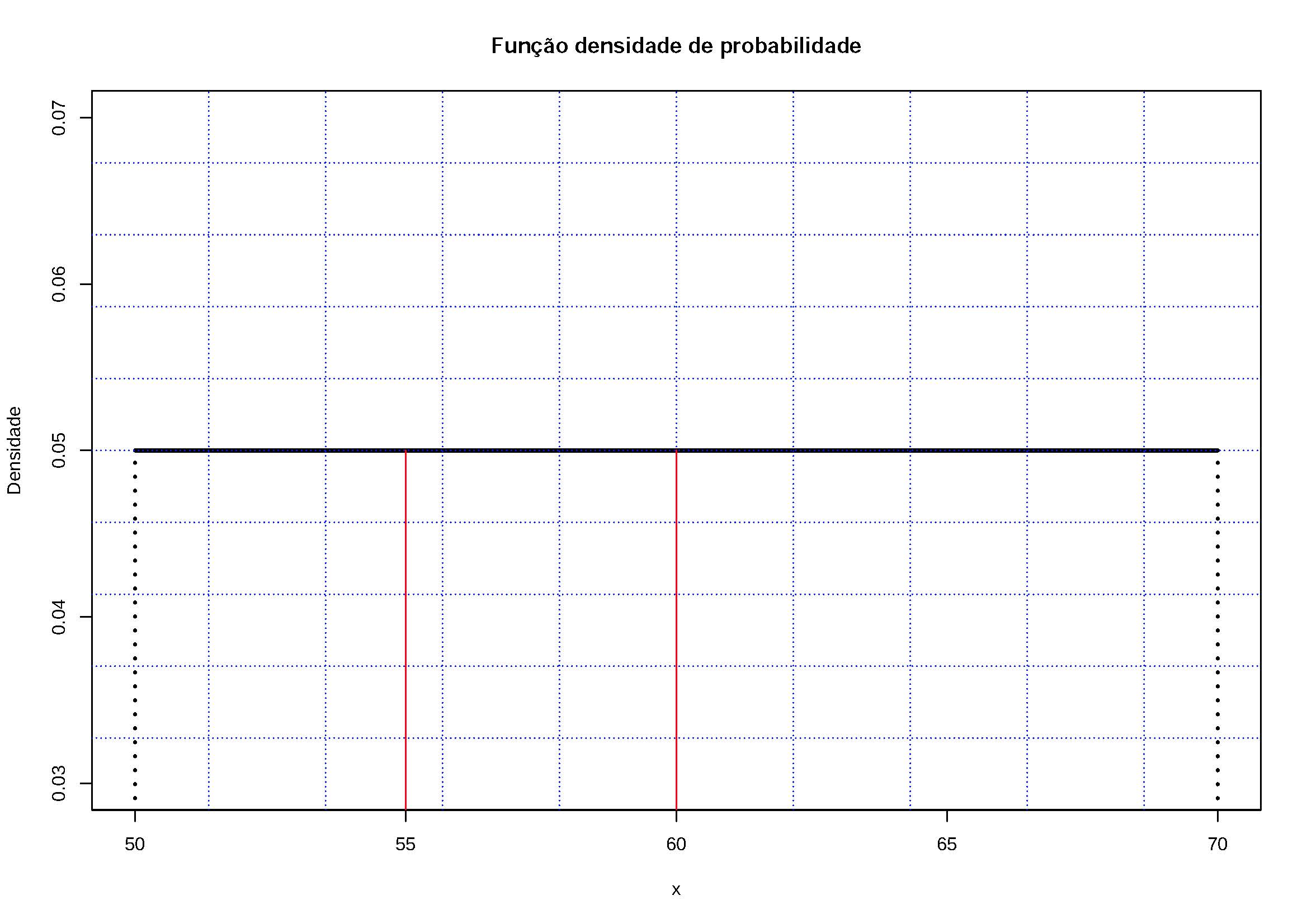
Figure 5.13: Os valores assumidos por \(f(x)\) são \(\ge 0\) e a área definida por \(f(x)\) no intervalo \(50 \le x \le 70\) é igual a 1. Por essa razão pode ser uma fdp. A probabilidade pedida equivale à área \(P(60 \le x \le 55) = (60-55) . 0,05=0,25\).
5.5 Esperança e variância de uma variável aleatória discreta
Coletando-se dados podemos analisá-los, por exemplo, em termos de sua distribuição, pelas estatísticas da média e variância.
De maneira análoga procedemos com variáveis aleatórias (discretas ou contínuas) onde dispomos das probabilidades de ocorrência associadas a cada um dos valores (discretos ou infinitos numeráveis) que ela pode assumir.
A esperança matemática (valor esperado ou expectância) de uma variável aleatória discreta é dada pela somatória do produto de cada um dos valores que ela pode assumir pela probabilidade associada a cada um desses valores.
Seja \(X\) uma variável aleatória discreta que pode assumir os valores \(x_{1},x_{2}, \dots x_{n}\); e sejam \(P_{1},P_{2}, \dots, P_{n}\) as respectivas probabilidades associadas às suas ocorrências.
A esperança da variável \(X\), denotada por \(E(X)\) será:
\[ E\left(X\right)=\sum _{i=1}^{n}{x}_{i}.{P}_{i} \]
Com n sendo o número de possíveis resultados que a variável \(X\) pode assumir.
A expressão anterior é semelhante àquela usada para se calcular a média para frequências de dados sendo que agora, no lugar de se utilizar a frequência relativa a cada dado observado, temos as probabilidades dadas por um modelo teórico pressuposto.
Algumas propriedades envolvendo a esperança:
1- Se \(c\) é uma constante qualquer, então: \(E(c) = c\) (\(c \in \mathbb{R}\));
2- Se \(c\) é uma constante qualquer, então: \(E(c X) = c . E(X)\) (\(c \in \mathbb{R}\));
3- Se \(c\) é uma constante qualquer, então: \(E(X \pm c) = E(X) \pm c\) (\(c \in \mathbb{R}\));
4- Se \(X\) e \(Y\) são duas variáveis aleatórias quaisquer, então: \(E(X \pm Y) = E(X) \pm E(Y)\);
5- Se \(X\) e \(Y\) são duas variáveis aleatórias independentes quaisquer, então: \(E(X.Y) = E(X).E(Y)\).
A variância de uma variável aleatória qualquer \(X\), denotada por \(Var(X)\), será dada por:
\[\begin{align*} Var\left(X\right) & = \sum_{i=1}^{n} [{x}_{i} - E(X)]^{2}.{P}_{i} \end{align*}\]
Algumas propriedades envolvendo a variância:
1- Se \(c\) é uma constante qualquer, então: \(Var(c)=0\) (\(c\in\mathbb{R}\));
2- Se \(c\) é uma constante qualquer, então: \(Var(cX)=c^{2}.Var(X)\) (\(c\in\mathbb{R}\));
3- Se \(X\) e \(Y\) são duas variáveis aleatórias independentes quaisquer, então: \(Var(X \pm Y)=Var(X)+Var(Y)\);
4- Se \(X\) e \(Y\) são duas variáveis aleatórias quaisquer, então: \(Var(X \pm Y)=Var(X)+Var(Y) \pm 2Cov(X,Y)\). A covariância (\(Cov(X,Y)\)) entre duas variáveis aleatórias quaisquer \(X\) e \(Y\) é dada por:
\[ Cov \left(X,Y\right)= E(XY) - E(X)E(Y) \]
Exemplo: Seja \(X\) uma variável aleatória discreta que indica o número de pontos observados na face superior de um dado quando ele é lançado. Calcule a esperança e a variância dessa variável aleatória.
| xi | P(X = xi) |
|---|---|
| 1 | 1/6 |
| 2 | 1/6 |
| 3 | 1/6 |
| 4 | 1/6 |
| 5 | 1/6 |
| 6 | 1/6 |
| Total | 1 |
\(E(X) = \frac{1}{6} . (1+2+3+4+5+6) = 3,50\)
\[\begin{align*} Var(X) & = (1-3,50)^{2}.(\frac{1}{6}) + (2-3,50)^{2}.(\frac{1}{6}) +\\ & (3-3,50)^{2}.(\frac{1}{6}) + (4-3,50)^{2}.(\frac{1}{6}) + (5-3,50)^{2}.(\frac{1}{6}) + \\ & (6-3,50)^{2}.(\frac{1}{6}) \\ & = 2,90 \end{align*}\]
Exemplo: Uma empresa de caminhões de aluguel possui uma frota composta de 4 veículos. O aluguel é cobrado por diária de uso de um caminhão e a função de distribuição de probabilidade de locações diárias está a seguir especificada. Calcule a esperança e a variância de locação diária dessa empresa.
| xi | P(X = xi) |
|---|---|
| 0 | 0,10 |
| 1 | 0,20 |
| 2 | 0,30 |
| 3 | 0,30 |
| 4 | 0,10 |
\(E(X) = (0 . 0,10) + (1 . 0,20) + 2 . 0,30) + (3 . 0,30) + (4 . 0,10) = 2,10\) (caminhões por dia)
\[\begin{align*} Var(X) & = (0-2,10)^{2}.0,10 + (1-2,10)^{2}.0,20 + (2-2,10)^{2}.0,30 + \\ & (3-2,10)^{2}.0,30 + (4-2,10)^{2}.0,10 \\ & = 1,29^{1} \end{align*}\]
\(^{1}\): (caminhões por dia)\(^{2}\)
5.6 Esperança e variância de uma variável aleatória contínua
A esperança e a variância de uma variável aleatória contínua são dadas, respectivamente, por:
\[ E(X) = \underset{-\infty }{\overset{\infty }{\int }}x.f\left(x\right)dx \]
\[ Var(X) = E\left[ (X - E(X))^{2} \right] = \underset{-\infty }{\overset{\infty }{\int }} (x-E(X))^{2}.f\left(x\right)dx \]