Capítulo 8 Introdução às estatísticas epidemiológicas
8.1 Tipos de estudos epidemiológicos
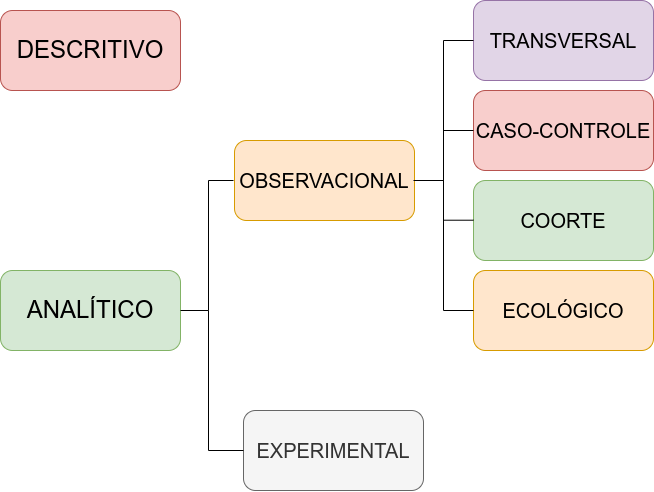
Figure 8.1: Estudos epidemiológicos
Quanto ao objetivo
- Exploratórias (descritivas)
- Explicativas (analíticas)
Quanto ao tempo
- Transversais
- Longitudinais
Quanto à natureza
- Observacional
- Experimental
Estudos descritivos têm como foco principal a caracterização de uma população ou fenômeno em um momento específico, sem tentar estabelecer relações de causa e efeito. Esses estudos fornecem uma visão geral de uma situação ou contexto, frequentemente sendo usados para medir a prevalência de doenças ou comportamentos.
Um estudo descritivo que relata a prevalência de diabetes em uma determinada região, baseado em dados coletados em um hospital.
Estudos analíticos observacionais buscam investigar possíveis associações entre variáveis, sem que o pesquisador manipule as condições em estudo. Estes estudos podem ser transversais, quando os dados são coletados em um único momento, ou longitudinais, quando há um acompanhamento ao longo do tempo.
Um estudo observacional que investiga a relação entre o consumo de alimentos ricos em gordura e doenças cardíacas, acompanhando os participantes ao longo do tempo, sem alterar seus comportamentos.
Estudos analíticos experimentais envolvem a manipulação ativa de variáveis pelo pesquisador, em um ambiente controlado, para avaliar seus efeitos sobre outras variáveis. Esses estudos, geralmente longitudinais, são considerados a melhor abordagem para investigar causalidade, pois permitem o controle de fatores de confusão e a comparação direta entre grupos. U
Um ensaio clínico em que um grupo de pacientes recebe um novo medicamento e outro grupo recebe um placebo para avaliar a eficácia do medicamento.
8.2 Estudos transversais
Um estudo transversal é um tipo de investigação observacional em que os dados são coletados em um único ponto no tempo ou durante um período curto. Esse tipo de estudo fornece uma “fotografia” instantânea das condições, comportamentos, ou características de uma população ou grupo em um determinado momento.
Embora útil para fornecer uma visão geral da saúde da população, esse tipo de estudo não permite inferir relações causais entre fatores de risco e desfechos, sendo mais adequado para levantar hipóteses.
Um estudo transversal pode ser usado para determinar a prevalência de hipertensão em uma população: um grupo de pessoas é examinado em um momento específico e o número de pessoas com hipertensão é registrado. Esse estudo dá uma visão geral da saúde da população naquele momento, mas não pode determinar se a hipertensão é causada por fatores observados no estudo.
8.3 Estudos longitudinais
Um estudo longitudinal é um tipo de investigação observacional em que os dados são coletados ao longo de um período prolongado, envolvendo múltiplas observações em diferentes momentos no tempo. Esse tipo de estudo permite acompanhar mudanças, tendências e a evolução de condições, comportamentos ou características ao longo do tempo, oferecendo uma perspectiva dinâmica dos fenômenos estudados.
Diferentemente dos estudos transversais, os estudos longitudinais são mais adequados para identificar relações temporais entre fatores de risco e desfechos, permitindo melhor compreensão sobre possíveis relações causais.
Um estudo longitudinal sobre hipertensão acompanharia o mesmo grupo de pessoas por vários anos, medindo regularmente sua pressão arterial e sua exposição a fatores de risco, permitindo assim observar como a pressão arterial se desenvolve ao longo do tempo e identificar quais fatores podem estar associados ao seu aparecimento ou progressão.
8.3.1 Estudos de casos e controles
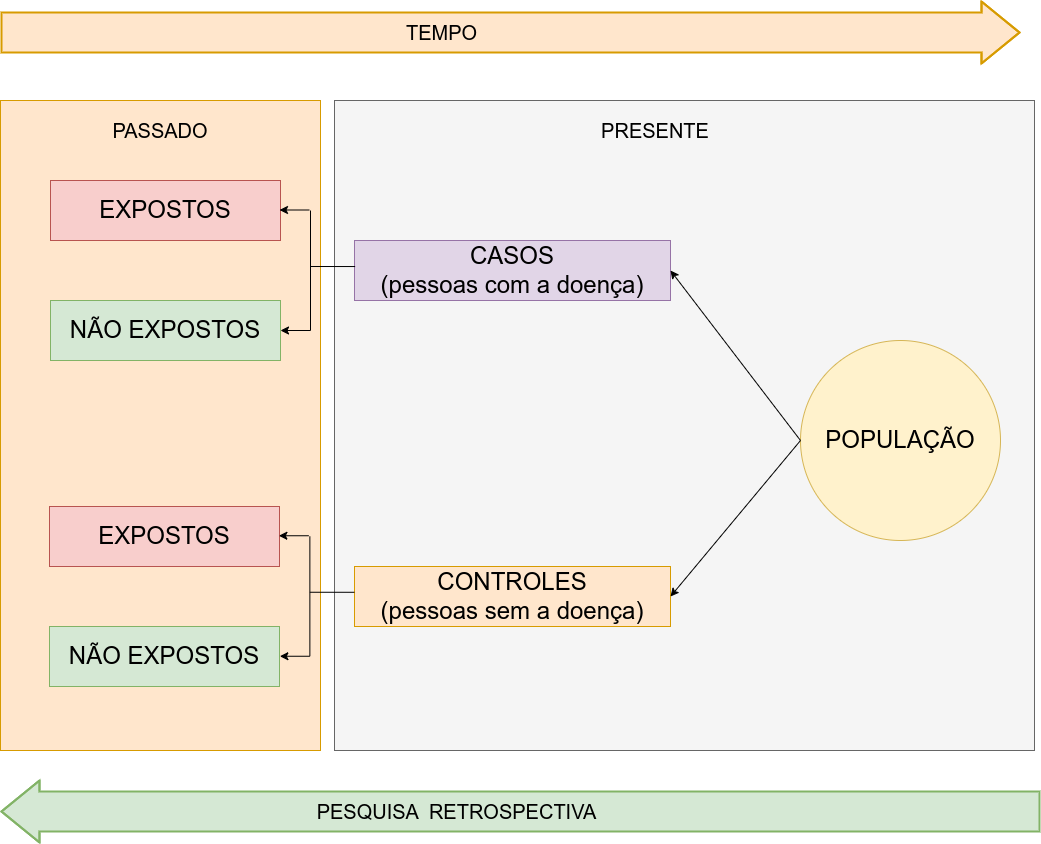
Figure 8.2: Estudo de casos e controles (retrospectivo)
Um estudo de caso-controle, geralmente retrospectivo, começa com a identificação de um grupo de casos (indivíduos com uma doença) e um grupo de controles (indivíduos sem a doença).
Por meio da anamnese o profissional de saúde ajuda o paciente a se recordar (pesquisa retrospectiva) de situações no passado que possam, de algum modo, configurar a exposição ao fator de risco pesquisado. As prevalências de exposição a um determinado fator são então medidas nos dois grupos e comparadas.
Se a prevalência da exposição for maior nos casos do que nos controles, esta exposição pode então ser um fator de risco para a doença. Se a prevalência for menor entre os casos, então esta exposição pode ser um fator de proteção para a doença.
Este método é particularmente útil para investigar doenças raras ou condições com longos períodos de incubação.
Algumas vantagens:
- são estudos relativamente baratos
- podem investigar vários possíveis fatores de risco e são úteis para doenças raras
Algumas desvantagens:
- são muito vulneráveis a vícios de seleção e observação
- não são adequados para investigar exposições raras
- não podem obter estimativas da incidência de doença
8.3.2 Estudos de coorte
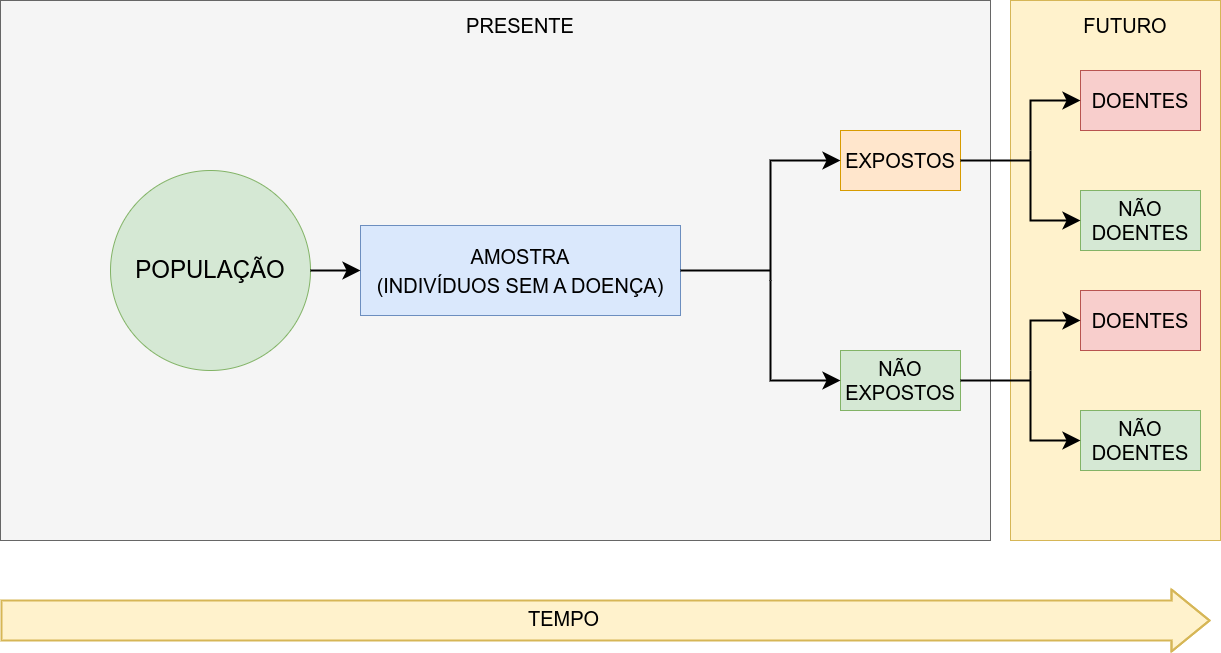
Figure 8.3: Estudos de coorte (prospectivos)
Estudos de coorte são prospectivos. Assim, um grupo de indivíduos expostos e outro grupo de não expostos a uma causa potencial de doença são acompanhados ao longo do tempo.
A incidência da doença é então comparada entre os dois grupos.
Para conduzir este tipo de estudo, é fundamental que uma hipótese clara seja formulada previamente ao início da investigação.
Considerando que esses estudos tendem a ser muito caros, eles geralmente são implementados somente depois que a hipótese foi explorada com outros desenhos de estudo mais econômicos.
Algumas vantagens:
- a exposição é medida antes do início da doença;
- as exposições raras podem ser estudadas selecionando grupos de indivíduos apropriados;
- a incidência da doença pode ser medida nos grupos de expostos e não expostos.
Algumas desvantagens:
- o estudo pode ser extenso e caro, especialmente se o período necessário para observar o efeito for prolongado;
- mudanças na condição de exposição e nos critérios diagnósticos podem ocorrer durante o período do estudo e isto pode afetar a classificação dos indivíduos em expostos e não expostos e em doentes e não doentes;
- a perda de indivíduos durante o seguimento pode introduzir sérios vieses no estudo.
8.3.3 Estudos clínicos aleatorizados
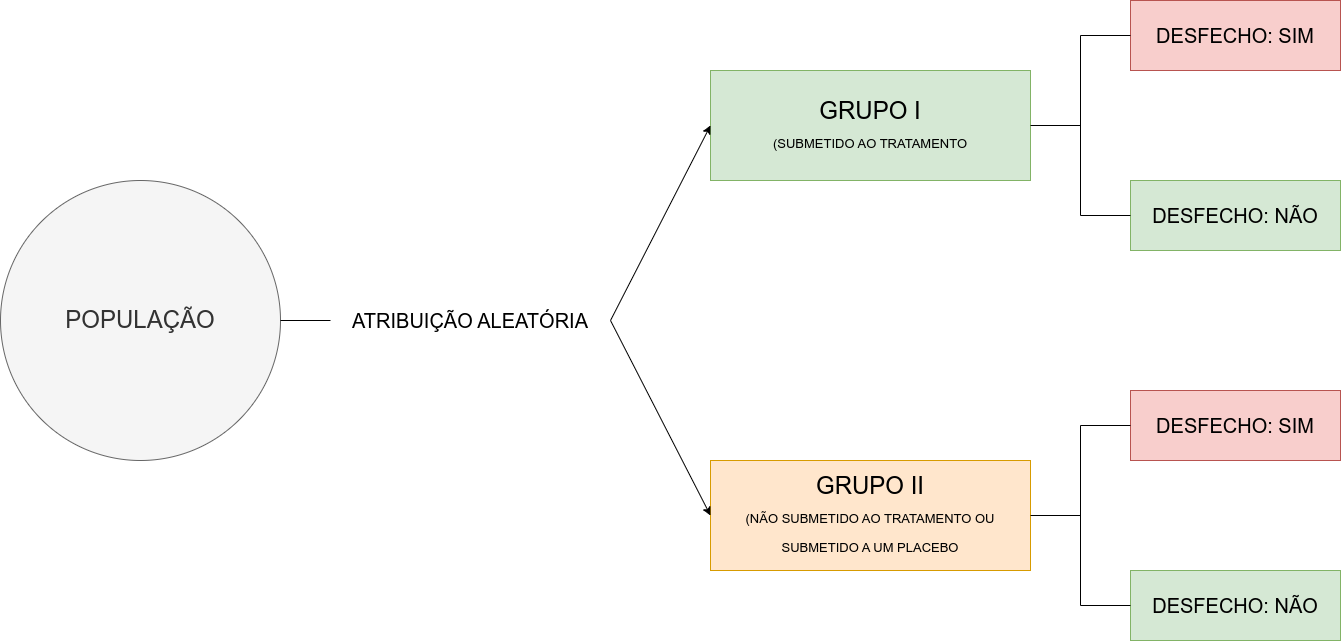
Figure 8.4: Estudos clínicos aleatorizados
Em estudos epidemiológicos experimentais, também conhecidos como estudos de intervenção ou ensaios clínicos, os indivíduos participantes são alocados a diferentes grupos de acordo com a presença ou não de exposição. No entanto, nesses estudos é o pesquisador quem define quais os indivíduos que receberão a exposição e esta exposição é uma medida preventiva ou terapêutica.
Este tipo de estudo tem como principal vantagem a possibilidade de garantir a validade dos resultados.
Os estudos experimentais são classificados em dois grandes grupos: as intervenções terapêuticas e as intervenções preventivas.
As intervenções terapêuticas incluem pacientes que apresentam uma condição de saúde específica e o objetivo é avaliar a capacidade de determinada intervenção produzir a recuperação, reduzir sintomas, prevenir recrudescimento ou diminuir o risco de uma evolução desfavorável. Para este tipo de estudo, a unidade de amostragem e análise é o indivíduo.
As intervenções preventivas envolvem pessoas sadias e o objetivo é avaliar a capacidade de uma intervenção em prevenir a ocorrência de um evento indesejado. As unidades de amostragem nesses casos podem ser tanto os indivíduos como comunidades.
Considerando que os participantes são deliberadamente selecionados pelo pesquisador para receber ou não uma intervenção, os estudos epidemiológicos experimentais envolvem questões éticas importantes e estão sujeitos a regulação legal.
8.4 Terminologia
- Epidemiologia
A epidemiologia é uma ciência médica que se concentra na distribuição e nos determinantes (fatores de risco) da frequência das doenças na população (desfechos) , examinando seus padrões em busca de determinar por que alguns grupos ou certos indivíduos desenvolvem uma doença ao passo que outros não.
- Estudos epidemiológicos
Estudos epidemiológicos são experimentos científicos realizados com o propósito mais comum de se desejar saber se determinadas características pessoais, hábitos ou aspectos do ambiente onde uma pessoa vive estão associados com certa doença, manifestações de uma doença ou outro evento de interesse do pesquisador.
- Desfecho (“sucesso”)
Desfecho é o termo usado para designar a ocorrência do evento de interesse em uma pesquisa. O desfecho pode ser o surgimento de uma doença, de um determinado sintoma, o óbito ou qualquer outro evento relacionado ao processo de saúde-doença. Uma dificuldade inerente está em quantificar a intensidade do desfecho.
- Fator de risco (fator sob estudo)
Fator de risco é a denominação usada em Epidemiologia para designar uma variável que se supõe estar associada ao desfecho. Refere-se portanto a um aspecto de hábitos pessoais ou a uma exposição ambiental, que pode estar associada a uma maior probabilidade de ocorrência de uma doença. Uma dificuldade inerente reside em como quantificar a exposição.
- Risco
Por risco entende-se a “a probabilidade de um membro de uma população definida desenvolver uma dada doença (ou condição) em um período de tempo”. Perceba que nesta definição é possível observar três elementos: base populacional, doença (ou condição) e tempo.
- População em risco
Um fator importante no cálculo das medidas da frequência de uma doença é a estimativa correta do número de pessoas em estudo. Idealmente, esses números devem incluir apenas pessoas potencialmente suscetíveis às doenças (ou condições) em estudo. Por exemplo: homens não devem ser incluídos no cálculo da frequência de câncer do colo do útero e, vice-e-versa para câncer de próstata. Uma vez que os fatores de risco geralmente podem ser modificados, intervir para alterá-los em uma direção favorável pode reduzir probabilidade de ocorrência da doença. O resultado dessas intervenções pode ser estatisticamente verificado em variados tipos de ensaios ou medidas repetidas usando-se os mesmos métodos e definições.
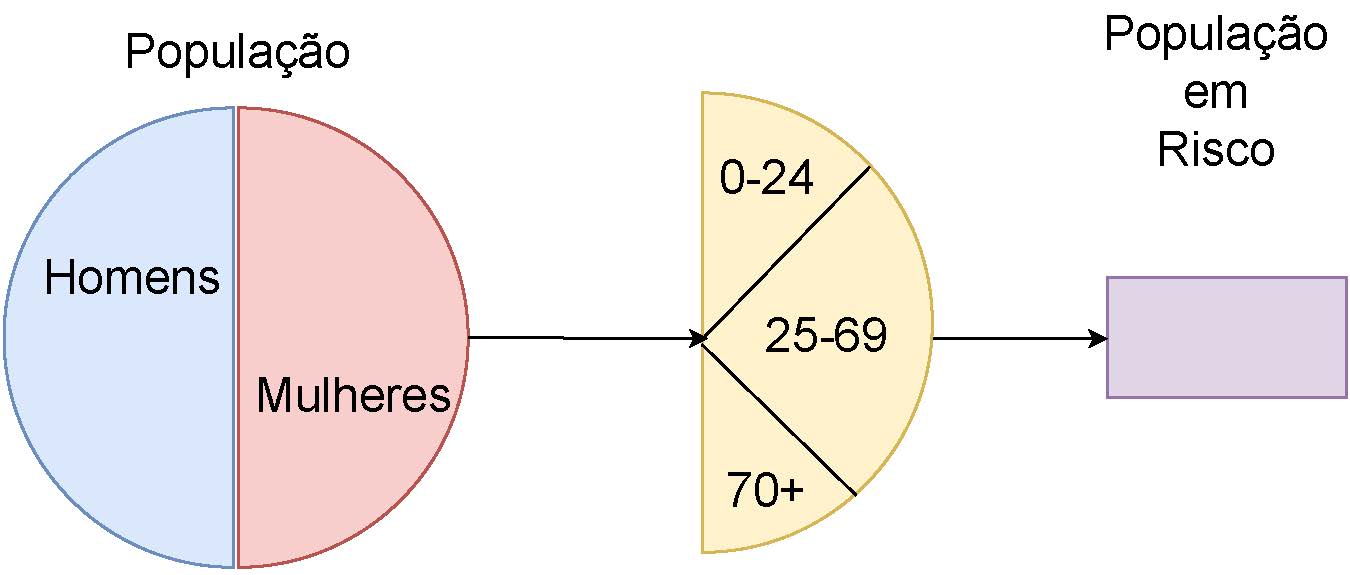
Figure 8.5: Adaptação: Basic Epidemiology: R. Bonita, R. Beaglehole, T Kjelltröm, 2006 (p. 17)
- Confundimento
A palavra “confundir” vem do latim confundere e significa misturar (fundir junto). O confundimento é outra importante questão em estudos epidemiológicos. Em um estudo da associação entre a exposição a uma causa (fator de risco) e a ocorrência de uma doença, o confundimento pode ocorrer quando existe outra exposição na população e está associada tanto à doença quanto ao fator de risco em estudo. O confundimento pode ter uma influência muito importante, podendo até alterar a direção aparente de uma associação. Uma variável que aparece como fator de proteção pode, após o controle de confundimento, ser considerada um fator de risco. Ou então o confundimento pode criar a aparência de uma relação causa-efeito que, na verdade, não existe. O confundimento ocorre quando os efeitos de duas exposições (fatores de risco) e a análise conclui que o efeito é devido a um fator e não a outro. O confundimento surge porque a distribuição não aleatória de fatores de risco na fonte também ocorre na população de estudo, fornecendo estimativas enganosas de efeito. Nesse sentido, pode parecer um viés, mas na verdade não resulta de um erro sistemático no projeto de pesquisa.
Um exemplo de confundimento pode ser a explicação para a relação demonstrada entre beber café e o risco de doenças cardíaca coronariana, pois sabe-se que o consumo de café está associado com o uso de tabaco: as pessoas que bebem café são mais propensos a fumar do que as pessoas que não bebem café.
Também é sabido que o tabagismo é uma causa de doença cardíaca coronariana. É, portanto, possível que a relação entre o consumo de café e doenças cardíacas doença meramente reflete a associação causal conhecida do uso de tabaco e doenças cardíacas. Nesta situação, fumar causa confundimento na aparente relação entre o consumo de café e doença cardíaca coronariana porque o tabagismo está correlacionado com beber café e é um fator de risco mesmo para quem não bebe café.
Para se contornar esse tipo de problema deve-se, na etapa de delineamento do experimento, estabelecer os fatores envolvidos e, na realização da pesquisa observar a:
- casualização: as amostras devem ser de tal modo constituídas que variáveis e confundimento nelas existam, potencialmente, em igual proporção (como, por exemplo, fumantes e não fumantes;
- restrição: se estamos estudando a relação do café com doenças coronarianas, admitir apenas não fumantes.
- Vícios de seleção e de observação
Vícios de seleção ocorrem quando os casos e controles são escolhidos de maneira que não representem corretamente a população. Vícios de observação ocorrem quando há erros na forma como a exposição ou os desfechos são medidos.
8.5 Medidas de risco, morte, associação e correlação
- Incidência (I);
- Prevalência (P);
- Incidência cumulativa (risco - IC);
- Fatalidade dos casos (FC);
- Taxa de mortalidade (TM);
- Diferença de risco (risco atribuível - RA);
- Razão de risco (risco relativo - RR);
- Risco atribuível proporcional (fração etiológica - FE);
- Odds ratio (razão de chances - OR); e,
- Correlação linear de Pearson.
A morbidade é um dos importantes indicadores de saúde. É um termo genérico usado para designar o conjunto de casos de uma dada doença ou a soma de agravos à saúde que atingem um grupo de indivíduos.
Medir morbidade nem sempre é uma tarefa fácil, pois são muitas as limitações que contribuem para essa dificuldade, como a subnotificação.
Para fazer essas mensurações, utilizam-se principalmente as medidas de incidência e prevalência.
8.5.1 Incidência
Incidência representa a proporção de número de novos casos de uma determinada doença em um intervalo de tempo em uma população exposta ao risco. É, por conseguinte, uma medida dinâmica pois pode sofrer alteração em razão do tempo no qual o estudo foi realizado.
Para um indivíduo pertencente à população exposta, indica a probabilidade de desenvolver a doença (risco).
Observe como calcular a incidência:
\[ I=\frac{\text{Número de novos casos de uma doença durante um determinado período de tempo}}{\text{Tamanho da população exposta ao risco nesse determinado período de tempo}} \\ \text{apresentação usualmente na forma: }I(\times 10^{n}) \]
Exemplo: para se determinar a incidência de meningite no Maranhão no ano de 2014, será necessário saber o número de casos de meningite que ocorreram naquele período de tempo entre os residentes do Maranhão e o número de habitantes do estado no mesmo período de tempo (todos os possíveis expostos à doença):
\[ I=\frac{\text{177 novos casos notificados de meningite no Maranhão em 2014}}{\text{2.648.532 (população do Maranhão em 2014)}} (\times 10^{5}) \\ I = \frac{6,68}{100.000 } \]
Os dados sobre prevalência e incidência tornam-se muito mais úteis se convertidos em taxas!
Como você pode notar, os casos novos, ou incidentes, são aqueles que não existiam no início do período de observação (tempo analisado), mas que vieram a ocorrer no decorrer desse período.
As taxas de incidência tendem a variar conforme o número de episódios da doença analisada, o número de pessoas que tiveram um episódio de uma doença, tempo para diagnosticá-la e a duração da investigação.
8.5.2 Prevalência
Prevalência representa a proporção de indivíduos de uma população que é acometida por uma determinada doença (ou agravo) em um determinado momento. É considerada uma medida estática.
Ela engloba tanto os casos casos preexistentes, quanto os novos que ocorreram no período.
Indica a probabilidade de ter a doença.
Observe como calcular a prevalência:
\[ P=\frac{\text{Número de casos existentes de doença em um determinado momento no tempo}}{\text{Tamanho da população em risco nesse mesmo momento no tempo}}\\ \text{apresentação usualmente na forma: }P(\times 10^{n}) \]
Exemplo: se em uma determinada comunidade mensurou-se 89 casos de indivíduos portadores de hipertensão em um determinado momento. Sabendo-se que a população (todos estão potencialmente expostos) dessa comunidade é de 3.500 a prevalência será:
\[ P=\frac{\text{89 casos de hipertensão na comunidade no dia 01/01/2014}}{\text{3.500 indivíduos como população em risco na comunidade em 01/01/2014}} (\times 10^{2})\\ P= \frac{2,54}{100 } \]
Os dados sobre prevalência e incidência tornam-se muito mais úteis se convertidos em taxas!
8.5.2.1 Relação entre prevalência e incidência
A prevalência depende tanto da incidência quanto da duração da doença. Se os casos de incidentes não forem resolvidos e continuarem ao longo do tempo eles se tornarão casos prevalentes. Nesse sentido:
\[ P=\text{Incidência} \times \text{Duração média da doença} \]
8.5.2.2 Quadro comparativo entre medidas de incidência e de prevalência
| Incidência | Prevalência | |
|---|---|---|
| Numerador | Número de novos casos de doença durante um determinado período de tempo | Número de casos existentes de doença em um determinado momento no tempo |
| Denominador | Tamanho da população em risco | Tamanho da população em risco |
| Foco |
Se o evento é um caso novo Tempo de início da doença |
Presença ou ausência de uma doença O período de tempo é arbitrário Um “instantâneo” no tempo |
| Uso |
Expressa o risco de adoecer A principal medida de doenças ou condições agudas, mas também usado para doenças crônicas Mais útil para estudos de causalidade |
Estima a probabilidade da população estar
doente no período de tempo estudado Útil no estudo da carga de doenças crônicas e implicações para os serviços de saúde |
8.5.3 Incidência cumulativa - IC (Risco)
Incidência Cumulativa (ou risco) é uma medida da ocorrência de uma doença.
Ao contrário da Incidência, no denominador temos agora o número de pessoas na população exposta sem a doença no começo do período do estudo:
\[ IC=\frac{\text{Núm. de novos casos de uma doença durante um determ. período de tempo}}{\text{Tam. da pop. em risco (exposta) livre (sem) da doença no começo de um determ. período de tempo}}\\ \text{apresentação usualmente na forma: }IC(\times 10^{n}) \]
8.5.3.1 Quadro comparativo entre medidas de risco e prevalência
| Característica | Risco | Prevalência |
|---|---|---|
| O que é medido | Probabilidade da doença | Percentagem da população com a doença |
| Unidade | adimensional | adimensional |
| Momento do diagnóstico da doença: | Casos novos (recém diagnosticados) | Existentes |
| Sinônimos | Incidência cumulativa | - |
8.5.4 Fatalidade dos Casos (FC)
Fatalidade dos casos é uma medida da severidade da doença, definida como a proporção de casos com desfecho em óbito pelo total de acometidos (portadores da condição) em um determinado período de tempo.
\[ FC(\%)=\frac{\text{Número de mortes de casos diagnosticados da doença durante um determinado período de tempo}}{\text{Número de casos diagnosticados nesse período de tempo}} \\ \text{apresentação usualmente na forma: }FC(\%)(\times 100) \]
8.5.5 Taxas de mortalidade (TM)
A principal desvantagem da Taxa bruta de mortalidade é que ela não leva em conta o fato de que a chance de morrer varia de acordo com idade, sexo, etnia e incontáveis outros fatores (sociais, econômicos, ).
Geralmente não é apropriado usá-la para comparar diferentes períodos de tempo ou áreas geográficas. Por exemplo, padrões de morte em núcleos urbanos recentemente constituídos e formados predominantemente por famílias jovens provavelmente serão muito diferentes das estâncias balneares escolhidas frequentemente por aposentados.
A Taxa bruta de mortalidade para todas as mortes ou uma causa específica de morte é calculado da seguinte forma:
\[ TM(\%)=\frac{\text{Número de mortes durante um determinado período de tempo}}{\text{Número de pessoas sob risco de morte nesse período de tempo}}\\ \text{apresentação usualmente na forma: }TM (\times 10^{n}) \]
8.6 Medidas de associação em estudos de coorte
Uma tabela é uma forma de representação retangular que permite mostrar clara e resumidamente os dados correspondentes a uma ou mais variáveis, visualizar o comportamento dos dados e facilitar o entendimento das informações. Uma tabela de dupla entrada permite extrair facilmente as proporções individuais, marginais e associadas relativas a duas variáveis (tabelas com mais variáveis são possíveis de serem construídas).
Especificamente para estudos epidemiológicos, admita que as variáveis envolvidas se refiram a contagens relacionadas à ocorrência de uma doença em dois grupos de pessoas sob diferentes exposições. O grupo não exposto ao fator de risco é frequentemente usado como referência.
- o grupo de pessoas expostas a um determinado fator de risco;
- o grupo de pessoas não expostas.
| Fator de risco | Desfecho observado (doença) | Total | |
| Presente | Ausente | ||
| Exposto | (a) | (b) | (e) |
| Não exposto | (c) | (d) | (f) |
| Total | (a + c) | (b + d) | (e + f) |
Exemplo: Incidência de baixo peso ao nascer em recém-nascidos de Pelotas (RS) segundo o hábito tabágico da mãe durante a gravidez (1982)
| Classificação da mãe | Baixo peso ao nascer | Total | |
| Sim | Não | ||
| Fumante | 275 (a) | 2.144 (b) | 2.419 (e) |
| Não fumante | 311 (c) | 4.496 (d) | 4.807 (f) |
| Total | 586 | 6.640 | 7.226 |
8.6.1 Incidência observada de nascimentos com baixo peso entre mães expostas ao risco (não fumantes): \(I_{e}\)
\[
I_{e}=\frac{(a)}{(e)} \times 100 = \frac{275}{2.419} \times 100 = 11,37 \%
\]
Interpretação: 11,37% das crianças analisadas e que têm mães tabagistas nasceram com baixo peso.
8.6.2 Incidência observada de nascimentos com baixo peso entre mães não expostas ao risco (não fumantes): \(I_{0}\)
\[ I_{0}: \frac{(c)}{(f)} \times 100 = \frac{311}{4.807} \times 100 = 6,47 \% \]
Interpretação: 6.47% das crianças analisadas e que têm mães não tabagistas nasceram com baixo peso.
8.6.3 Prevalência de nascimentos com baixo peso na população estudada
\[ \frac{(a) + (c)}{(e) + (f)} \times 100 = \frac{586}{7.226} \times 100 = 8,11\% \]
Interpretação: 8,11% das crianças avaliadas nasceram com baixo peso.
8.6.4 Diferença de risco (Risco atribuível - RA)
A diferença de risco (também chamada de excesso de risco ou risco atribuível) é a diferença nas taxas de ocorrência entre os grupos expostos e não expostos da população. Essa medida quantifica o excesso absoluto de risco associado a uma dada exposição. É uma medida útil do problema de saúde pública causado pela exposição ao fator de risco.
Analisando-se as incidências na Tabela vemos que a diferença de risco de nascimento de bebês com baixo peso entre mães fumantes e não fumantes é:
\[\begin{align*} RA & =\frac{(a)}{(e)} - \frac{(c)}{(f)} \\ & = \frac{275}{2.419} - \frac{311}{4.807} \\ & = 0,11368334 - 0,064697316 \\ & = 4,9 \% \end{align*}\]
Interpretação: 4,9% do risco de nascer com baixo peso pode ser atribuído ao fato de terem mães tabagistas.
8.6.5 Razão de risco (Risco relativo - RR)
A razão de risco (também chamada de risco relativo) é o quociente entre as taxas de ocorrência entre os grupos expostos e não expostos da população. Pode ser interpretado como a probabilidade de um indivíduo exposto apresentar o desfecho relativa à de um indivíduo não exposto também apresentar.
- razão de risco maior que 1: fator de risco;
- razão de risco menor que 1: fator protetor.
Analisando-se as incidências na Tabela vemos que a razão de risco de nascimento de bebês com baixo peso entre mães fumantes e não fumantes é de:
\[\begin{align*} RR & = \frac{\frac{(a)}{(e)}}{\frac{(c)}{(f)}} \\ & = \frac{\frac{275}{2.419}}{\frac{311}{4.807}} \\ & = \frac{0,11368334}{0,064697316} \\ & = 1,76 \end{align*}\]
Interpretação: As crianças de mães tabagistas têm aproximadamente 1,76 vezes mais risco de nascer com baixo peso em comparação com as de mães não tabagistas.
8.6.6 Risco atribuível proporcional (Fração etiológica - FE)
Quando se acredita que uma determinada exposição é um fator de risco de uma determinada doença, a fração atribuível é a proporção da doença na população específica que seria eliminada se a exposição fosse evitada. As frações etiológicas (frações relacionadas à origem da doença) são úteis para avaliar as prioridades da ação de saúde pública.
O Risco atribuível proporcional (fração etiológica) é, assim, a proporção de todos os casos que podem ser atribuídos diretamente a uma exposição específica. Pode ser determinado pelo quociente da diferença de riscos das incidências pela incidência entre a população exposta.
Esta medida é útil para determinar a importância relativa das exposições para toda a população. É a proporção pela qual a taxa de incidência do desfecho em toda a população seria reduzido se a exposição fosse eliminada.
Observe como calcular o Risco atribuível proporcional (Fração etiológica - FE):
\[ FE = \frac{I_{e}-I_{o}}{I_{e}} \times 100 \]
- \(I_{e}\): é a incidência da doença no grupo exposto;
- \(I_{o}\): é a incidência da doença no grupo não exposto.
Analisando-se as incidências na Tabela vemos que o risco atribuível proporcional de nascimento de bebês com baixo peso entre mães fumantes é de:
\[\begin{align*} FE = & \frac{\left(\frac{(a)}{(e)} - \frac{(c)}{(f)}\right)}{\frac{(a)}{(e)}} \\ = & \frac{\left(\frac{275}{2.419} - \frac{311}{4.807}\right)}{\frac{275}{2.419}} \\ = & \frac{\left(0,11368334 - 0,064697316\right)}{0,11368334} \\ = & 43,09 \% \end{align*}\]
Interpretação: 43,09% dos casos nascimentos de bebês com baixo peso podem ser atribuídos diretamente ao hábito tabagista das mães.
8.7 Odds ratio (Razão das chances) em studos de casos e controles
Em estudos de caso-controle os pacientes são incluídos de acordo com a presença ou não do desfecho.
Geralmente são definidos um grupo de casos (com o desfecho) e outro de controles (sem o desfecho) e avalia-se uma eventual exposição, no passado a potenciais fatores de risco nestes dois grupos.
Devido ao fato de que o delineamento deste tipo de estudo baseia-se no próprio desfecho, não se pode estimar diretamente a incidência do desfecho de acordo com a presença ou ausência da exposição, como é usual em estudos de coorte.
Isto se deve ao fato de que a proporção casos/controles) (ou desfecho/não-desfecho) é determinada pelo próprio pesquisador (a proporção não é a mesma observada na população toda com possibilidade de exposição). Assim, a ocorrência de desfechos no grupo total estudado não é regida pela história natural da doença e depende de quantos casos e controles o pesquisador selecionou.
Apesar de não se poder estimar diretamente as incidências da doença (desfecho) entre expostos e não-expostos em estudos de caso-controle, é possível, entretanto, obter-se uma aproximação da Razão de risco (risco relativo - RR).
Se se o desfecho for suficientemente raro na população (10% ou menos), a Razão de risco (risco relativo - RR) pode ser estimada aproximadamente em estudos de caso-controle através da Razão de chances (odds ratio - OR) de exposição entre casos e controle:
| Fator | Grupos | ||
| Casos (com o desfecho) | Controles (sem o desfecho) | ||
| Exposto | (a) | (b) | |
| Não exposto | (c) | (d) | |
8.7.1 Chance (odds) de observar um desfecho entre os casos:
Grupo dos casos: a partir das proporções dos elementos desse grupo que foram ou não expostos ao fator (\(P_{e},P_{0}\)):
\[ P_{e}=\frac{\text{casos expostos}}{\text{total de casos}}\\ P_{0}=\frac{\text{casos não expostos}}{\text{total de casos}}\\ \]
a chance (odds) de se observar o desfecho entre os casos é a divisão dessas proporções:
\[ Odds_{casos}=\frac{P_{e}}{P_{0}} \\ Odds_{casos}=\frac{\text{casos expostos}}{\text{casos não expostos}} \\ Odds_{casos}= \frac{a}{c} \]
8.7.2 Chance (odds) de observar um desfecho entre os controles:
Grupo dos controles: a partir das proporções dos elementos desse grupo que foram ou não expostos ao fator (\(P_{e},P_{0}\)):
\[ P_{e}=\frac{\text{controles expostos}}{\text{total de controles}}\\ P_{0}=\frac{\text{controles não expostos}}{\text{total de controless}}\\ \]
a chance (odds) de se observar o desfecho entre os controles é a divisão dessas proporções:
\[
Odds_{controles}=\frac{P_{e}}{P_{0}} \\
Odds_{controles}=\frac{\text{controles expostos}}{\text{controles não espostos}}\\
Odds_{controles}= \frac{b}{d}
\]
8.7.3 A razão das chances entre os casos e controle (odds ratio):
A razão das chances ( odds ratio - OR) de exposição entre casos e controles fica sendo
\[ OR = \frac{Odds_{casos}}{Odds_{controles}} \]
- OR ( odds ratio) maior que 1: fator de risco: a exposição ao fator aumenta a chance do desfecho
- OR ( odds ratio) menor que 1: fator protetor: a exposição ao fator reduza chance do desfecho.
A razão de chances ( odds ratio) exprime numericamente quantas vezes a exposição a um determinado fator de risco implica na possibilidade do desfecho estudado.
Exemplo: tanto o tabagismo quanto a poluição do ar são causas de câncer de pulmão, mas a fração devido ao fumo é geralmente muito maior do que a devido ao ar poluição. Apenas em comunidades com prevalência de tabagismo muito baixa e severos índices de poluição, esta seria a provável de ser a principal causa de câncer de pulmão. Assim, em muitos países, controle do tabagismo deve ter prioridade nos programas de prevenção do câncer de pulmão.
| Fator | Grupos | |
| Casos (com câncer) | Controles (sem câncer) | |
| Exposto ao tabaco | 200 (a) | 50 (b) |
| Não exposto ao tabaco | 100 (c) | 150 (d) |
A chance (odds) de se observar o desfecho entre os casos :
\[ Odds_{casos}=\frac{\text{casos expostos}}{\text{casos não expostos}} \\ Odds_{casos}= \frac{a}{c}\\ Odss_{casos}= \frac{200}{100}=2\\ \]
Interpretação: entre as pessoas com câncer (casos), a chance de terem sido espostos ao tabaco é 2 vezes maior do que a chance de não terem sido expostos. Ou seja, é muito provável que tenham sido expostas.
A chance (odds) de se observar o desfecho entre os controles:
\[ Odds_{controles}=\frac{\text{controles expostos}}{\text{controles não espostos}}\\ Odds_{controles}= \frac{b}{d}\\ Odds_{controles}= \frac{50}{150}=0,33 \]
Interpretação: entre as pessoas sem câncer (controles), a chance de terem sido expostos ao tabaco é 1/3 da chance de não terem sido expostas. Ou seja, é pouco provável que tenham sido expostas.
A razão das chances ( odds ratio - OR) de exposição entre casos e controle:
\[ OR = \frac{Odds_{casos}}{Odds_{controles}} \\ OR = \frac{2}{0,33}=6,06 \]
Interpretação: uma odds ratio (OR) de aproximadamente 6,06 significa que a chance de uma pessoa exposta ao tabagismo desenvolver câncer de pulmão é cerca de 6 vezes maior do que a de uma pessoa não exposta, o que indica uma forte associação entre tabagismo e câncer de pulmão.
8.8 Intervalos de confiança
As técnicas para obter intervalos de confiança para estimativas amostrais de riscos relativos e odds ratio que serão apresentadas estão descritas no livro Statistics with Confidence (Douglas Altman _et a_l) e, embora se constituam em aproximações para grandes amostras, são estimativas razoáveis para pequenos estudos.
Através de uma transformação logarítmica, obtém-se uma curva com forma aproximadamente Normal e assim esses intervalos podem ser delimitados a partir da função densidade de probabilidade da distribuição Normal padronizada.
Para o intervalo de confiança da estimativa amostral da diferença de risco (risco atribuível) a proposição se encontra no artigo Statistical algorithms in Review Manager 5 de Jonathan J. Deeks e Julian P. T. Higgins e está baseada na distribuição da diferença de proporções.
\[ \log(IC_{(medida)}) = \log(medida) \pm \left[ z_{(1-\frac{\alpha}{2})} \times EP(\log(medida))\right] \]
em que:
- \(EP(\log(medida))\) é o erro padrão do logaritmo da medida e os valores mínimo e máximo do intervalo de confiança serão dados por \(\exp{[\log((IC_{(medida)})]}\);
- \(\alpha\) é o nível de significânica tolerado e, por conseguinte, \((1-\alpha)\) o nível de confiança pretendido; e,
- e os valores de \(|z_{(1-\frac{\alpha}{2})}|\) poderão ser obtidos em uma tabela da distribuição Normal padronizada, sendo os mais usuais:
| Níveis de significância (α) | 0,10 | 0,05 | 0,01 | 0,005 | 0,002 |
|---|---|---|---|---|---|
| Valores críticos de zc | -1,28 | -1,645 | -2,33 | -2,58 | -2,88 |
| para testes unilaterais | ou 1,28 | ou 1,645 | ou 2,33 | ou 2,58 | ou 2,88 |
| Valores críticos de zc | -1,645 | -1,96 | -2,58 | -2,81 | -3,08 |
| para testes bilaterais | e 1,645 | e 1,96 | e 2,58 | e 2,81 | e 3,08 |
8.8.1 Razão de risco (Risco relativo - RR)
Considere a estrutura dos dados presentes na Tabela para a estimação dos erros padrão a seguir.
\[ EP(\log(RR)) = \sqrt{ \left[ \frac{1}{(a)} - \frac{1}{(a) + (b)} \right] + \left[ \frac{1}{(c)} - \frac{1}{(c)+(d)} \right]} \]
O erro padrão do Risco Relativo - RR para os dados da Tabela poderá ser assim estimado:
\[\begin{align*} EP(\log(RR)) = & \sqrt{ \left[ \frac{1}{(a)} - \frac{1}{(a) + (b)} \right] + \left[ \frac{1}{(c)} - \frac{1}{(c)+(d)} \right] }\\ EP(\log(RR)) = & \sqrt{ \left[ \frac{1}{(275)} - \frac{1}{2.419} \right] + \left[ \frac{1}{311} - \frac{1}{4.807} \right] }\\ EP(\log(RR)) = & \sqrt{0,006230374} \\ EP(\log(RR)) = & 0,078932718 \end{align*}\]
Para um nível de confiança de 95% (nível de significância de 0,05%) extraímos o valor crítico de \(z_{(1-\frac{\alpha}{2})}\) da Tabela (\(z_{c}=|1,96|\)).
A partir do Risco relativo previamente calculado (1,76), um intervalo com nível de confiança de (\(1-\alpha=95\%\)) fica assim delimitado:
\[\begin{align*} \log(IC_{(RR)}) = & \log(RR) \pm \left[ z_{(1-\frac{\alpha}{2})} \times EP(\log(RR))\right] \\ \log(IC_{(RR)}) = & \log(1,76) \pm \left(1,96 \times 0, 078932718 \right) \\ \log(IC_{(RR)}) = & 0,565313809 \pm 0,154708127 \\ \text{Limite superior } IC_{(RR)} = & \exp{(0.7147081)} \\ = & 2,04359 \\ \text{Limite inferior } IC_{(RR)} = & \exp{(0.4052919)}\\ = & 1,49974 \end{align*}\]
Assim, o intervalo com nível de confiança (\(1-\alpha\)) estabelecido em 95% para a estimativa amostra do Risco relativo (RR) calculada em 1,76 é:
\[ IC_{RR (1-\alpha=0,95)} = [1,49974 ; 2,04359] \]
8.8.2 Razão de chances ( odds ratio - OR)
Considere a estrutura dos dados presentes na Tabela para a estimação dos erros padrão a seguir.
\[ EP(\log(OR)) = \sqrt{ \frac{1}{(a)} + \frac{1}{(b)} + \frac{1}{(c)} +\frac{1}{(d)} } \]
O erro padrão da Razão das chances ( odds ratio - OR) para os dados da Tabela poderá ser assim estimado:
\[\begin{align*} EP(\log(OR)) = & \sqrt{ \frac{1}{(a)} + \frac{1}{(b)} + \frac{1}{(c)} +\frac{1}{(d)} } \\ EP(\log(OR)) = & \sqrt{ \frac{1}{275} + \frac{1}{2.144} + \frac{1}{311} +\frac{1}{4.496} }\\ EP(\log(OR)) = & \sqrt{ 0,007540636}\\ EP(\log(OR)) = & 0,08683683 \end{align*}\]
Para um nível de confiança de 95% (nível de significância de 0,05%) extraímos o valor de \(z_{(1-\frac{\alpha}{2})}\) da Tabela (\(z_{c}=|1,96|\)).
A partir da Razão das chances previamente calculada (1,85), um intervalo com nível de confiança de (\(1-\alpha=95\%\)) fica assim delimitado:
\[\begin{align*} \log(IC_{(OR)}) = & \log(OR) \pm \left[ z_{(1-\frac{\alpha}{2})} \times EP(\log(OR))\right] \\ \log(IC_{(OR)}) = & \log(1,85) \pm \left(1,96 \times 0,08683683 \right) \\ \log(IC_{(OR)}) = & 0,6151856 \pm 0,1702002 \\ \text{Limite superior } IC_{(OR)} = & \exp{( 0.7853858)}\\ = & 2,193253 \\ \text{Limite inferior } IC_{(OR)} = & \exp{(0.4449854)} \\ = & 1,560467 \\ \end{align*}\]
Assim, o intervalo com nível de confiança (\(1-\alpha\)) estabelecido em 95% para a estimativa amostra da Razão de chances (OR) calculada em 1,85 é:
\[ IC_{OR (1-\alpha=0,95)} = [1, 560467 ; 2, 193253] \]
8.8.3 Diferença de risco (Risco atribuível - RA)
Considere a estrutura dos dados presentes na Tabela para a estimação dos erros padrão a seguir.
\[ EP(RA) = \sqrt{ \left [ \frac{a \times b}{(a+b)^3} \right ] + \left [ \frac{c \times d}{(c+d)^3} \right ] } \]
\[
IC_{(RA)} = RA \pm \left[ z_{(1-\frac{\alpha}{2})} \times EP(RA))\right]
\]
O erro padrão da Diferença de Risco - RA para os dados da Tabela poderá ser assim estimado:
\[\begin{align*} EP(RA) = & \sqrt{ \left [ \frac{a \times b}{(a+b)^3} \right ] + \left [ \frac{c \times d}{(c+d)^3} \right ] }\\ EP(RA) = & \sqrt{ \left [ \frac{275 \times 2144}{(275+2.144)^3} \right ] + \left [ \frac{311 \times 4.496}{(311+4.496)^3} \right ] }\\ EP(RA) = & 0,007364887 \end{align*}\]
Para um nível de confiança de 95% (nível de significância de 0,05%) extraímos o valor de \(z_{(1-\frac{\alpha}{2})}\) da Tabela (\(z_{c}=|1,96|\)).
A partir da Diferença de risco previamente calculada (0,049), um intervalo com nível de confiança de (\(1-\alpha=95\%\)) fica assim delimitado:
\[\begin{align*} IC_{(RA)} = & RA \pm \left[ z_{(1-\frac{\alpha}{2})} \times EP(RA))\right] \\ IC_{(RA)} = & 0,049 \pm \left[ 1,96 \times 0,007364887 \right] \\ \text{Limite superior} = & 0,06343518 \\ \text{Limite inferior} = & 0,03456482 \end{align*}\]
Assim, o intervalo com nível de confiança (\(1-\alpha\)) estabelecido em 95% para a estimativa amostras da Diferença de risco (RA) calculada em 4,9% é:
\[ IC_{RA (1-\alpha=0,95)} = [3,46\% ; 6,34\%] \]