Capítulo 14 Introdução à Modelagem de Dados
usar ou não usar caret?
14.1 Introdução
No processo de investigação científica de qualquer fenômeno, a modelagem constitui ferramenta fundamental que permite ao pesquisador estruturar o conhecimento disponível e formular hipóteses testáveis. Independentemente da área de estudo, fenômenos naturais, sociais ou econômicos apresentam complexidade inerente que demanda abordagens sistemáticas para sua compreensão. A modelagem de dados emerge, neste contexto, como meio rigoroso de extrair informação relevante, compreender relações entre variáveis, quantificar efeitos e realizar inferências sobre o fenômeno investigado.
Modelos constituem representações simplificadas da realidade, construídos a partir de pressupostos teóricos e evidências empíricas. Estas representações não buscam capturar toda a complexidade do fenômeno estudado, mas sim seus aspectos essenciais, permitindo identificar padrões subjacentes nos dados observados. A utilidade de um modelo reside precisamente em seu equilíbrio entre simplicidade e capacidade explicativa, condensando informação complexa em estrutura matematicamente tratável e cientificamente interpretável.
Ao estudar um fenômeno, o pesquisador inicialmente coleta dados e, subsequentemente, depara-se com diversas decisões metodológicas que influenciarão diretamente a qualidade e interpretabilidade dos resultados. Entre essas decisões, destacam-se a escolha do tipo de modelo adequado à natureza do problema, a seleção de variáveis relevantes e a verificação de pressupostos necessários. Embora existam numerosas técnicas disponíveis para modelagem de dados, tanto estatísticas quanto de aprendizado de máquina, o foco deste trabalho recai sobre modelos de regressão linear múltipla. A compreensão clara dos fundamentos teóricos e das limitações de cada abordagem constitui requisito essencial para a condução apropriada da análise.
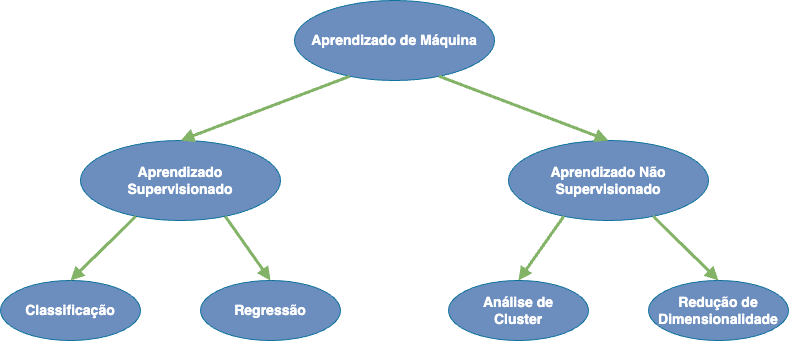
14.2 Tipos de Aprendizado
A modelagem de dados pode ser categorizada em duas grandes classes:
- supervisionada
- não supervisionada.
Esta distinção fundamental baseia-se na disponibilidade ou ausência de uma variável resposta conhecida durante o processo de análise.
Na modelagem supervisionada, o pesquisador dispõe de observações tanto das variáveis preditoras (\(X_1, X_2, \ldots, X_p\)) quanto da variável resposta (\(Y\)). O objetivo consiste em estimar uma função \(f\) tal que \(Y \approx f(X)\), permitindo compreender como as variáveis preditoras influenciam a resposta e, potencialmente, predizer valores de \(Y\) para novas observações de \(X\). Este paradigma abrange problemas de regressão, quando \(Y\) é quantitativa, e problemas de classificação, quando \(Y\) é qualitativa. A disponibilidade da variável resposta permite avaliar a qualidade do modelo através da comparação entre valores preditos e observados.
A modelagem não supervisionada, por sua vez, caracteriza-se pela ausência de uma variável resposta pré-definida. Neste contexto, o pesquisador busca identificar padrões ( patterns ), estruturas ou agrupamentos ( clusters ) naturais nos dados sem orientação de um resultado específico a ser predito. Técnicas como análise de componentes principais e análise de agrupamentos exemplificam esta abordagem. Embora não constitua o foco principal desta análise, a modelagem não supervisionada frequentemente complementa estudos exploratórios que precedem a modelagem supervisionada.
A escolha entre estas abordagens depende fundamentalmente do problema de pesquisa. Quando existe interesse em compreender ou predizer um fenômeno específico mensurável, a modelagem supervisionada mostra-se apropriada. Por outro lado, quando o objetivo consiste em explorar estruturas latentes ou reduzir a complexidade dos dados sem um alvo pré-definido, a modelagem não supervisionada oferece ferramentas adequadas.
Em muitos contextos, ambas as abordagens complementam-se, com técnicas não supervisionadas informando a especificação de modelos supervisionados subsequentes.
14.3 Classificação e Regressão
Problemas de classificação envolvem a predição de uma variável resposta categórica. Formalmente, dado um conjunto de preditores \(X = (X_1, X_2, \ldots, X_p)\), busca-se estimar a probabilidade de pertencimento a cada classe \(k\): \(P(Y = k | X)\). Exemplos incluem diagnosticar se um paciente apresenta ou não determinada condição (classificação binária) ou categorizar imagens em múltiplas classes (classificação multinomial). Embora técnicas de classificação sejam amplamente empregadas em diversos campos científicos, sua discussão detalhada extrapola o escopo desta análise.
Problemas de regressão caracterizam-se pela presença de uma variável resposta quantitativa contínua. O objetivo consiste em modelar a relação entre \(Y\) e as variáveis preditoras \(X_1, X_2, \ldots, X_p\). No modelo de regressão linear múltipla, assume-se que esta relação pode ser aproximada por uma função linear: \(Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \epsilon\), onde \(\beta_0, \beta_1, \ldots, \beta_p\) representam os parâmetros a serem estimados e \(\epsilon\) denota o erro aleatório.
A distinção entre classificação e regressão baseia-se fundamentalmente na natureza da variável resposta. Enquanto classificação lida com categorias discretas, regressão opera com valores contínuos em uma escala numérica. Esta diferença implica em métodos distintos de estimação, avaliação e interpretação dos modelos. Cabe ressaltar que alguns problemas admitem formulação tanto como classificação quanto como regressão, dependendo de como a variável resposta é definida.
Neste trabalho, concentra-se na modelagem via regressão linear múltipla, técnica que permite quantificar o efeito de cada preditor sobre a resposta, controlar por variáveis confundidoras e realizar inferências estatísticas sobre os parâmetros estimados. A escolha por esta abordagem justifica-se pela natureza contínua da variável resposta em análise e pela necessidade de interpretação direta dos coeficientes estimados.
14.4 Dados
A qualidade de qualquer análise depende fundamentalmente da qualidade dos dados utilizados. Dados bem coletados, estruturados e documentados constituem alicerce essencial para modelagem confiável e inferências válidas. Problemas nos dados, como erros de mensuração, valores faltantes ou violações de pressupostos, propagam-se através de toda análise e podem comprometer seriamente as conclusões obtidas.
A estrutura dos dados influencia diretamente as decisões de modelagem. Aspectos como tamanho amostral, número e tipo de variáveis disponíveis, presença de estruturas hierárquicas ou dependências temporais, e balanceamento entre grupos determinam quais técnicas são apropriadas e quais questões de pesquisa podem ser adequadamente respondidas. Dados insuficientes ou inadequados limitam o poder analítico e a generalização dos resultados.
Considerações éticas e de reprodutibilidade exigem documentação cuidadosa sobre origem dos dados, critérios de inclusão e exclusão de observações, transformações aplicadas e decisões metodológicas tomadas durante o pré-processamento. Esta transparência permite que outros pesquisadores avaliem criticamente a análise, reproduzam os resultados e construam sobre o conhecimento gerado. A análise rigorosa inicia-se, portanto, com dados de qualidade e documentação adequada.
14.4.1 Importação
Neste capítulo exploraremos o conjunto de dados RealEstate_California. Para carregar o arquivo utilizaremos a função read.csv() do R base indicando o camiho, especificando o separador de campos e confirmando que a primeira linha contém os nomes das variáveis.
14.4.2 Estrutura
Após a importação, podemos verificar a quantidade de observações (dados) e de features (características) desse conjunto de dados.
cat("========================================\n")
cat("RELATÓRIO DE VERIFICAÇÃO DA ESTRUTURA DO DATASET\n")
cat("========================================\n\n")
cat("DIMENSÕES DO DATASET\n")
cat("--------------------\n")
cat("Número de observações (linhas):", nrow(dados), "\n")
cat("Número de variáveis (colunas):", ncol(dados), "\n\n")
cat("\n")-> ========================================
-> RELATÓRIO DE VERIFICAÇÃO DA ESTRUTURA DO DATASET
-> ========================================
->
-> DIMENSÕES DO DATASET
-> --------------------
-> Número de observações (linhas): 35389
-> Número de variáveis (colunas): 39O conjunto de dados contém 35.389 observações distribuídas em 39 variáveis.
14.4.3 Tipo das Variáveis
A função str() fornece uma visão compacta da organização interna do dataframe, incluindo o número de observações, o número de variáveis e a natureza de cada feature.
-> 'data.frame': 35389 obs. of 39 variables:
-> $ X : int 0 1 2 3 4 5 6 7 8 9 ...
-> $ id : chr "95717-2087851113" "94564-18496265" "94564-18484475" "94564-18494835" ...
-> $ stateId : int 9 9 9 9 9 9 9 9 9 9 ...
-> $ countyId : int 77 189 190 191 192 193 194 195 196 197 ...
-> $ cityId : int 24895 36958 36958 36958 36958 36958 36958 36958 36958 36958 ...
-> $ country : chr "USA" "USA" "USA" "USA" ...
-> $ datePostedString : chr "2021-01-13" "2021-07-12" "2021-07-08" "2021-07-07" ...
-> $ is_bankOwned : int 0 0 0 0 0 0 0 0 0 0 ...
-> $ is_forAuction : int 0 0 0 0 0 0 0 0 0 0 ...
-> $ event : chr "Listed for sale" "Listed for sale" "Listed for sale" "Listed for sale" ...
-> $ time : num 1.61e+12 1.63e+12 1.63e+12 1.63e+12 1.63e+12 ...
-> $ price : num 145000 675000 649000 599000 299000 575000 888000 315000 399000 998000 ...
-> $ pricePerSquareFoot: num 0 404 459 448 0 407 390 381 401 394 ...
-> $ city : chr "Gold Run" "Pinole" "Pinole" "Pinole" ...
-> $ state : chr "CA" "CA" "CA" "CA" ...
-> $ yearBuilt : int 0 1958 1959 1908 0 1958 2000 1988 1991 1972 ...
-> $ streetAddress : chr "0 Moody Ridge Rd" "1476 Belden Ct" "3540 Savage Ave" "2391 Plum St" ...
-> $ zipcode : num 95717 94564 94564 94564 94564 ...
-> $ longitude : num -121 -122 -122 -122 -122 ...
-> $ latitude : num 39.2 38 38 38 38 ...
-> $ hasBadGeocode : int 0 0 0 0 0 0 0 0 0 0 ...
-> $ description : chr "Amazing opportunity to build your dream home On almost 10 acres. Grading has been completed for your buildWell"| __truncated__ "\"Great house in a wonderful neighborhood! Walking into this house you will feel the comfort and open concept "| __truncated__ "\"Light-filled mid-century 3 BR 2 BA home in the heart of Pinole Valley. Beautiful refinished hardwood floors t"| __truncated__ "The cutest house in the historic district of Pinole is finally for sale! This exquisite gem from 1908 has been "| __truncated__ ...
-> $ currency : chr "USD" "USD" "USD" "USD" ...
-> $ livingArea : num 0 1671 1414 1336 0 ...
-> $ livingAreaValue : num 0 1671 1414 1336 0 ...
-> $ lotAreaUnits : chr "Acres" "sqft" "Acres" "sqft" ...
-> $ bathrooms : num 0 2 2 2 0 2 3 1 2 3 ...
-> $ bedrooms : num 0 3 3 3 0 3 5 1 2 5 ...
-> $ buildingArea : num 0 1671 1414 1336 0 ...
-> $ parking : int 0 1 1 1 0 1 1 1 1 1 ...
-> $ garageSpaces : num 0 2 2 1 0 2 2 1 1 2 ...
-> $ hasGarage : int 0 1 1 1 0 1 1 1 1 1 ...
-> $ levels : chr "0" "One Story" "One Story" "Two Story" ...
-> $ pool : int 0 0 0 0 0 0 0 0 0 0 ...
-> $ spa : int 0 0 0 1 0 0 0 0 1 0 ...
-> $ isNewConstruction : int 0 0 0 0 0 0 0 0 0 0 ...
-> $ hasPetsAllowed : int 0 0 0 0 0 0 0 0 0 1 ...
-> $ homeType : chr "LOT" "SINGLE_FAMILY" "SINGLE_FAMILY" "SINGLE_FAMILY" ...
-> $ county : chr "Placer County" "Contra Costa County" "Contra Costa County" "Contra Costa County" ...Observa-se:
- Variáveis inteiras (
int): Representam valores numéricos inteiros. No contexto deste dataset, incluem:- identificadores numéricos como um numerador de linhas (
X) e os dos estados, cidades e condados (stateId,countyId,cityId) e o ano de construção do imóvel (yearBuilt) - indicadores binários indicam a presença ou ausência de alguma feature (
is_bankOwned,is_forAuction,hasBadGeocode,parking,hasGarage,pool,spa,isNewConstruction,hasPetsAllowed)
- identificadores numéricos como um numerador de linhas (
- Variáveis numéricas (
num): Representam valores numéricos contínuos ou discretos.- contínuos como o timestamp (
time), as variáveis monetárias e de área (price,pricePerSquareFoot,livingArea,livingAreaValue,buildingArea) e as coordenadas geográficas e código postal (longitude,latitude,zipcode) - os discretos representam contagens de características físicas dos imóveis (
bathrooms,bedrooms,garageSpaces).
- contínuos como o timestamp (
- Variáveis de texto (
chr): Armazenam texto e podem representar tanto categorias quanto descrições. Incluem identificadores textuais (id), informações geográficas (country,city,state,streetAddress,county), classificações (event,lotAreaUnits,levels,homeType), a data de publicação (datePostedString), a moeda (currency) e a descrição detalhada do imóvel (description).
Nota-se que algumas variáveis numéricas apresentam valores zero, possivelmente indicando dados ausentes ou não aplicáveis (por exemplo, yearBuilt = 0, livingArea = 0). As variáveis binárias codificadas como inteiros assumem valores 0 ou 1, representando ausência ou presença de determinada característica.
14.5 Engenharia de features
14.5.1 Depuração de Dados (Data Cleaning)
A limpeza de dados constitui uma etapa fundamental que antecede qualquer análise estatística. Neste processo, detectam-se e corrigem-se dados corrompidos, imprecisos, irrelevantes ou incompletos, garantindo que o conjunto de dados seja preciso, consistente e adequado para análise, modelagem estatística e tomada de decisão fundamentada.
Este procedimento envolve a correção de erros tipográficos, o tratamento de valores ausentes, a remoção de registros duplicados e a padronização de formatos. O objetivo é transformar dados brutos em informações confiáveis e estruturadas, viabilizando análises robustas e conclusões válidas.
Nesta etapa, identificam-se e removem-se observações que apresentam valores ausentes, inconsistências ou características que possam comprometer a qualidade da análise. A exclusão criteriosa de registros problemáticos contribui para a integridade do conjunto de dados e para a confiabilidade dos resultados subsequentes.
Os principais critérios para remoção de observações incluem:
- Presença de valores ausentes (
NA) em variáveis essenciais para a análise:
# Armazenar número original de observações
n_original <- nrow(dados)
cat("VALORES AUSENTES (NA)\n")
cat("---------------------\n")
cat("Total de observações (linhas) sem valores no dataset:", sum(is.na(dados)), "\n")
cat("Número de variáveis (colunas) com observações (linhas) sem valores:", sum(colSums(is.na(dados)) > 0), "\n\n")
cat("Variáveis (colunas) com valores ausentes:\n")
na_counts <- colSums(is.na(dados))
na_vars <- na_counts[na_counts > 0]
if(length(na_vars) > 0) {
for(i in 1:length(na_vars)) {
cat(" -", names(na_vars)[i], ":", na_vars[i],
"(", round(na_vars[i]/nrow(dados)*100, 2), "%)\n")
}
} else {
cat(" Nenhuma variável apresenta valores ausentes.\n")
}
cat("\n")
# Remoção de observações com valores ausentes
cat("REMOÇÃO DE OBSERVAÇÕES COM VALORES AUSENTES\n")
cat("--------------------------------------------\n")
# Remover linhas com qualquer valor NA
dados_clean <- na.omit(dados)
# Relatório de remoção
n_removidas <- n_original - nrow(dados_clean)
prop_removidas <- (n_removidas / n_original) * 100
cat("Observações originais:", n_original, "\n")
cat("Observações removidas:", n_removidas, "\n")
cat("Observações mantidas:", nrow(dados_clean), "\n")
cat("Proporção removida:", round(prop_removidas, 2), "%\n")-> VALORES AUSENTES (NA)
-> ---------------------
-> Total de observações (linhas) sem valores no dataset: 314
-> Número de variáveis (colunas) com observações (linhas) sem valores: 2
->
-> Variáveis (colunas) com valores ausentes:
-> - time : 289 ( 0.82 %)
-> - zipcode : 25 ( 0.07 %)
->
-> REMOÇÃO DE OBSERVAÇÕES COM VALORES AUSENTES
-> --------------------------------------------
-> Observações originais: 35389
-> Observações removidas: 314
-> Observações mantidas: 35075
-> Proporção removida: 0.89 %- Inconsistências lógicas entre variáveis (por exemplo,
livingArea = 0para imóveis residenciais)
# Armazenar número original de observações
n_original <- nrow(dados_clean)
cat("INCONSISTÊNCIAS DETECTADAS\n")
cat("--------------------------\n")
cat("Imóveis com área habitável igual a zero:",
sum(dados_clean$livingArea == 0, na.rm = TRUE), "\n")
cat("Imóveis com ano de construção igual a zero:",
sum(dados_clean$yearBuilt == 0, na.rm = TRUE), "\n")
cat("Imóveis com preço igual a zero:",
sum(dados_clean$price == 0, na.rm = TRUE), "\n")
cat("Imóveis com número de quartos igual a zero (exceto lotes):",
sum(dados_clean$bedrooms == 0 & dados_clean$homeType != "LOT", na.rm = TRUE), "\n\n")
cat("VALORES NEGATIVOS\n")
cat("-----------------\n")
cat("Preços negativos:", sum(dados_clean$price < 0, na.rm = TRUE), "\n")
cat("Áreas habitáveis negativas:", sum(dados_clean$livingArea < 0, na.rm = TRUE), "\n")
cat("Número de quartos negativos:", sum(dados_clean$bedrooms < 0, na.rm = TRUE), "\n")
cat("Número de banheiros negativos:", sum(dados_clean$bathrooms < 0, na.rm = TRUE), "\n\n")
# Remoção de observações com inconsistências
cat("REMOÇÃO DE OBSERVAÇÕES COM INCONSISTÊNCIAS\n")
cat("-------------------------------------------\n")
# Criar filtros para remover inconsistências
filtro <- dados_clean$livingArea > 0 &
dados_clean$yearBuilt > 0 &
dados_clean$price > 0 &
!(dados_clean$bedrooms == 0 & dados_clean$homeType != "LOT") &
dados_clean$price >= 0 &
dados_clean$livingArea >= 0 &
dados_clean$bedrooms >= 0 &
dados_clean$bathrooms >= 0
# Aplicar filtro
dados_clean <- dados_clean[filtro, ]
# Relatório de remoção
n_removidas <- n_original - nrow(dados_clean)
prop_removidas <- (n_removidas / n_original) * 100
cat("Observações originais:", n_original, "\n")
cat("Observações removidas:", n_removidas, "\n")
cat("Observações mantidas:", nrow(dados_clean), "\n")
cat("Proporção removida:", round(prop_removidas, 2), "%\n")-> INCONSISTÊNCIAS DETECTADAS
-> --------------------------
-> Imóveis com área habitável igual a zero: 6726
-> Imóveis com ano de construção igual a zero: 5978
-> Imóveis com preço igual a zero: 30
-> Imóveis com número de quartos igual a zero (exceto lotes): 1868
->
-> VALORES NEGATIVOS
-> -----------------
-> Preços negativos: 0
-> Áreas habitáveis negativas: 0
-> Número de quartos negativos: 0
-> Número de banheiros negativos: 0
->
-> REMOÇÃO DE OBSERVAÇÕES COM INCONSISTÊNCIAS
-> -------------------------------------------
-> Observações originais: 35075
-> Observações removidas: 8088
-> Observações mantidas: 26987
-> Proporção removida: 23.06 %- Registros duplicados que distorcem as estatísticas descritivas:
# Armazenar número original de observações
n_original <- nrow(dados_clean)
cat("IDENTIFICADOR ÚNICO\n")
cat("-------------------\n")
cat("Número de IDs únicos:", length(unique(dados_clean$id)), "\n")
cat("Número total de observações:", nrow(dados_clean), "\n")
cat("IDs duplicados:", sum(duplicated(dados_clean$id)), "\n")
if(sum(duplicated(dados_clean$id)) > 0) {
cat("\nALERTA: Existem IDs duplicados no dataset!\n")
cat("IDs que aparecem mais de uma vez:\n")
id_counts <- table(dados_clean$id)
dup_ids <- names(id_counts[id_counts > 1])
for(i in 1:min(5, length(dup_ids))) {
cat(" - ID:", dup_ids[i], "aparece", id_counts[dup_ids[i]], "vezes\n")
}
if(length(dup_ids) > 5) {
cat(" ... e mais", length(dup_ids) - 5, "IDs duplicados\n")
}
}
cat("\n")
cat("OBSERVAÇÕES DUPLICADAS (linhas inteiramente idênticas)\n")
cat("------------------------------------------------------\n")
cat("Número de observações duplicadas:", sum(duplicated(dados_clean)), "\n\n")
# Remoção de observações duplicadas
cat("REMOÇÃO DE OBSERVAÇÕES DUPLICADAS\n")
cat("----------------------------------\n")
# Remover duplicatas (mantém a primeira ocorrência)
dados_clean <- dados_clean[!duplicated(dados_clean), ]
# Relatório de remoção
n_removidas <- n_original - nrow(dados_clean)
prop_removidas <- (n_removidas / n_original) * 100
cat("Observações originais:", n_original, "\n")
cat("Observações removidas:", n_removidas, "\n")
cat("Observações mantidas:", nrow(dados_clean), "\n")
cat("Proporção removida:", round(prop_removidas, 2), "%\n")-> IDENTIFICADOR ÚNICO
-> -------------------
-> Número de IDs únicos: 23318
-> Número total de observações: 26987
-> IDs duplicados: 3669
->
-> ALERTA: Existem IDs duplicados no dataset!
-> IDs que aparecem mais de uma vez:
-> - ID: 90001-20930852 aparece 2 vezes
-> - ID: 90001-20932657 aparece 2 vezes
-> - ID: 90001-20941911 aparece 2 vezes
-> - ID: 90001-20943412 aparece 2 vezes
-> - ID: 90001-20944696 aparece 2 vezes
-> ... e mais 3664 IDs duplicados
->
-> OBSERVAÇÕES DUPLICADAS (linhas inteiramente idênticas)
-> ------------------------------------------------------
-> Número de observações duplicadas: 0
->
-> REMOÇÃO DE OBSERVAÇÕES DUPLICADAS
-> ----------------------------------
-> Observações originais: 26987
-> Observações removidas: 0
-> Observações mantidas: 26987
-> Proporção removida: 0 %- Valores atípicos extremos que não representam a população de interesse
# Armazenar número original de observações
n_original <- nrow(dados_clean)
# Definir variáveis contínuas para análise de outliers
vars_continuas <- c("price", "pricePerSquareFoot", "livingArea",
"buildingArea", "bedrooms", "bathrooms")
cat("REMOÇÃO DE VALORES ATÍPICOS EXTREMOS\n")
cat("====================================\n\n")
# Calcular quantis para cada variável
cat("Limites dos quantis (0.01 e 0.99) por variável:\n")
cat("------------------------------------------------\n")
for(var in vars_continuas) {
q01 <- quantile(dados_clean[[var]], 0.01, na.rm = TRUE)
q99 <- quantile(dados_clean[[var]], 0.99, na.rm = TRUE)
cat(sprintf("%-20s: Q0.01 = %10.2f | Q0.99 = %10.2f\n", var, q01, q99))
}
cat("\n")
# Criar filtro para manter observações dentro dos limites
filtro <- rep(TRUE, nrow(dados_clean))
for(var in vars_continuas) {
q01 <- quantile(dados_clean[[var]], 0.01, na.rm = TRUE)
q99 <- quantile(dados_clean[[var]], 0.99, na.rm = TRUE)
filtro <- filtro & (dados_clean[[var]] >= q01 & dados_clean[[var]] <= q99 | is.na(dados_clean[[var]]))
}
# Aplicar filtro
dados_clean <- dados_clean[filtro, ]
# Relatório de remoção
n_removidas <- n_original - nrow(dados_clean)
prop_removidas <- (n_removidas / n_original) * 100
cat("RESUMO DA REMOÇÃO\n")
cat("-----------------\n")
cat("Observações originais:", n_original, "\n")
cat("Observações removidas:", n_removidas, "\n")
cat("Observações mantidas:", nrow(dados_clean), "\n")
cat("Proporção removida:", round(prop_removidas, 2), "%\n")-> REMOÇÃO DE VALORES ATÍPICOS EXTREMOS
-> ====================================
->
-> Limites dos quantis (0.01 e 0.99) por variável:
-> ------------------------------------------------
-> price : Q0.01 = 100000.00 | Q0.99 = 8800000.00
-> pricePerSquareFoot : Q0.01 = 74.00 | Q0.99 = 2050.14
-> livingArea : Q0.01 = 625.00 | Q0.99 = 7606.34
-> buildingArea : Q0.01 = 0.00 | Q0.99 = 4300.54
-> bedrooms : Q0.01 = 1.00 | Q0.99 = 7.00
-> bathrooms : Q0.01 = 0.00 | Q0.99 = 8.00
->
-> RESUMO DA REMOÇÃO
-> -----------------
-> Observações originais: 26987
-> Observações removidas: 1482
-> Observações mantidas: 25505
-> Proporção removida: 5.49 %Comparando-se o dataset original e o processado:
cat("RESUMO GERAL: ANTES E DEPOIS DA LIMPEZA\n")
cat("========================================\n\n")
cat("DIMENSÕES DO DATASET\n")
cat("--------------------\n")
cat("Antes da limpeza:\n")
cat(" Observações:", nrow(dados), "\n")
cat(" Variáveis:", ncol(dados), "\n\n")
cat("Depois da limpeza:\n")
cat(" Observações:", nrow(dados_clean), "\n")
cat(" Variáveis:", ncol(dados_clean), "\n\n")
# Cálculo das remoções totais
n_removidas_total <- nrow(dados) - nrow(dados_clean)
prop_removidas_total <- (n_removidas_total / nrow(dados)) * 100
cat("TOTAL DE OBSERVAÇÕES REMOVIDAS\n")
cat("-------------------------------\n")
cat("Observações removidas:", n_removidas_total, "\n")
cat("Proporção removida:", round(prop_removidas_total, 2), "%\n")
cat("Taxa de retenção:", round(100 - prop_removidas_total, 2), "%\n")-> RESUMO GERAL: ANTES E DEPOIS DA LIMPEZA
-> ========================================
->
-> DIMENSÕES DO DATASET
-> --------------------
-> Antes da limpeza:
-> Observações: 35389
-> Variáveis: 39
->
-> Depois da limpeza:
-> Observações: 25505
-> Variáveis: 39
->
-> TOTAL DE OBSERVAÇÕES REMOVIDAS
-> -------------------------------
-> Observações removidas: 9884
-> Proporção removida: 27.93 %
-> Taxa de retenção: 72.07 %14.5.2 Atribuição de Valores (Imputation)
A imputação de valores constitui uma alternativa à remoção de observações com dados faltantes. Este procedimento consiste em substituir valores ausentes por estimativas derivadas da distribuição dos dados observados. A escolha entre remoção e imputação depende fundamentalmente do volume de dados disponíveis e do padrão de ausência dos valores.
Do ponto de vista estatístico, a remoção de observações é defensável quando o conjunto de dados é suficientemente grande e a proporção de valores ausentes é reduzida. Neste cenário, a exclusão de registros incompletos não compromete significativamente o poder estatístico nem introduz viés substancial nas estimativas. Entretanto, quando o volume de dados é limitado ou a proporção de valores ausentes é elevada, a remoção sistemática pode resultar em:
- Perda de poder estatístico: redução excessiva do tamanho amostral compromete a precisão das estimativas e a capacidade de detectar efeitos significativos
- Introdução de viés de seleção: se os dados ausentes não ocorrem de forma completamente aleatória (Missing Completely At Random - MCAR), a remoção pode distorcer a distribuição das variáveis e comprometer a validade das inferências
- Desperdício de informação: observações parcialmente completas contêm informação útil que é descartada na remoção
A imputação preserva o tamanho amostral e, quando executada adequadamente, pode manter propriedades estatísticas importantes do conjunto de dados. Métodos comuns incluem:
- Imputação por medidas de tendência central: substituição por média, mediana ou moda (para dados qualitativos)
- Imputação baseada em similaridade: métodos como k-Nearest Neighbors (KNN) que utilizam observações similares
Contudo, a imputação não é isenta de limitações. Métodos simples como a substituição pela mediana reduzem artificialmente a variabilidade dos dados e podem atenuar correlações entre variáveis. Métodos mais sofisticados, embora preservem melhor a estrutura dos dados, introduzem complexidade computacional e requerem pressupostos sobre os mecanismos de ausência.
Para conjuntos de dados volumosos (> 10.000 observações) com baixa proporção de valores ausentes (< 5%), a remoção é geralmente preferível pela simplicidade e ausência de viés induzido pela imputação. Para conjuntos menores ou com proporções mais elevadas de ausência, métodos de imputação devem ser considerados, priorizando-se técnicas que preservem a distribuição e as relações entre variáveis.
14.5.3 Recodificação de Variáveis Quantitativas
Nesse dataset há uma variável chamada time que se refere a um momento no tempo no formato Unix em milissegundos (Unix epoch time ou POSIX time).
Esse momento representa o número de milissegundos transcorridos desde 1º de janeiro de 1970 às 00:00:00 UTC (conhecida como ``época Unix’’), amplamente utilizado em sistemas computacionais para armazenar datas e horários de forma numérica. Essa feature representa o momento em que o imóvel foi listado para venda (listing date)
# Converter timestamp Unix (em milissegundos) para data no formato dd/mm/aaaa
# Dividir por 1000 para converter milissegundos para segundos
dados_clean$time_date <- as.Date(as.POSIXct(dados_clean$time/1000, origin="1970-01-01"))
# Formatar como dd/mm/aaaa
dados_clean$time_formatted <- format(dados_clean$time_date, "%d/%m/%Y")
# Verificar resultado
head(dados_clean[, c("time", "time_formatted", "datePostedString")])-> time time_formatted datePostedString
-> 2 1.626e+12 12/07/2021 2021-07-12
-> 3 1.626e+12 08/07/2021 2021-07-08
-> 4 1.626e+12 07/07/2021 2021-07-07
-> 6 1.626e+12 06/07/2021 2021-07-06
-> 7 1.625e+12 05/07/2021 2021-07-05
-> 8 1.625e+12 05/07/2021 2021-07-05Vê-se que essa codificação resulta nos mesmos valores da variável datePostedString.
14.5.4 Codificação de Variáveis Qualitativas
A codificação de variáveis qualitativas constitui um procedimento essencial na preparação de dados para análise estatística e modelagem. Variáveis qualitativas, por sua natureza não numérica, requerem transformação em representações numéricas para serem incorporadas em modelos matemáticos. A escolha do método de codificação depende da natureza da variável (nominal ou ordinal), do número de categorias e do tipo de análise a ser realizada. As variáveis qualitativas classificam-se em:
- Nominais: sem ordem natural (por exemplo: cor, tipo de imóvel, cidade)
- Ordinais: com ordem natural (por exemplo: nível de escolaridade, classificação de risco)
14.5.4.1 Codificação por Rótulos (Label Encoding)
A codificação por rótulos atribui um número inteiro único a cada categoria. Para uma variável com categorias \(\{A, B, C\}\), pode-se atribuir \(\{1, 2, 3\}\) respectivamente.
- Vantagens: simplicidade computacional; não aumenta a dimensionalidade; adequado para variáveis ordinais onde a ordem das categorias é significativa (para variáveis nominais introduz ordenação artificial)
Vejamos as frequências de cada rótulo
->
-> Listed for sale Listing removed Price change Sold
-> 19130 1849 3531 995Codificamos os rótulos
E observamos um ordenamento artificial
-> rotulo numero
-> 1 Listed for sale 1
-> 2 Listing removed 2
-> 3 Price change 3
-> 4 Sold 4->
-> APARTMENT CONDO LOT MULTI_FAMILY
-> 0 1 946 88 386
-> 1 0 0 1 0
-> 2 0 0 1 3
-> 3 0 0 0 0
-> 4+ 0 0 0 0
-> Four 0 0 0 3
-> Multi-Level 0 0 0 0
-> Multi/Split 0 59 0 3
-> Multi/Split-One 0 0 0 0
-> Multi/Split-Three Or More 0 0 0 0
-> Multi/Split-Tri-Level 0 0 0 0
-> Multi/Split-Two 0 2 0 0
-> One 0 1023 0 37
-> One Story 0 57 0 0
-> One Story-One 0 94 0 0
-> One Story-Three Or More 0 3 0 0
-> One Story-Two 0 4 0 0
-> One-Multi/Split 0 0 0 0
-> One-Three Or More 0 4 0 0
-> One-Two 0 5 0 7
-> One-Two-Multi/Split 0 0 0 0
-> One-Two-Three Or More 0 0 0 0
-> Other 0 3 0 0
-> Other-One 0 6 0 0
-> Split Level 0 0 0 0
-> Three 0 0 0 0
-> Three Or More 0 191 0 14
-> Three or More Stories 0 24 0 0
-> Three or More Stories-One 0 7 0 0
-> Three or More Stories-Three Or More 0 9 0 0
-> Three or More Stories-Two 0 4 0 0
-> Three Or More-Multi/Split 0 1 0 0
-> Three Or More-Split Level 0 0 0 0
-> Tri-Level 0 5 0 0
-> Tri-Level-Three Or More 0 1 0 0
-> Tri-Level-Two 0 0 0 0
-> Two 0 679 0 30
-> Two Story 0 25 0 0
-> Two Story-One 0 9 0 0
-> Two Story-Three Or More 0 4 0 0
-> Two Story-Two 0 30 0 0
-> Two-Multi/Split 0 3 0 0
-> Two-Three Or More 0 1 0 0
-> Two-Three Or More-Multi/Split 0 1 0 0
->
-> SINGLE_FAMILY TOWNHOUSE
-> 0 7421 359
-> 1 40 0
-> 2 42 1
-> 3 15 0
-> 4+ 2 0
-> Four 0 0
-> Multi-Level 1 0
-> Multi/Split 294 38
-> Multi/Split-One 2 0
-> Multi/Split-Three Or More 3 1
-> Multi/Split-Tri-Level 2 0
-> Multi/Split-Two 4 0
-> One 6836 39
-> One Story 608 11
-> One Story-One 7 6
-> One Story-Three Or More 0 0
-> One Story-Two 0 0
-> One-Multi/Split 12 0
-> One-Three Or More 2 0
-> One-Two 47 2
-> One-Two-Multi/Split 2 0
-> One-Two-Three Or More 1 0
-> Other 9 1
-> Other-One 0 0
-> Split Level 2 0
-> Three 11 2
-> Three Or More 359 161
-> Three or More Stories 46 17
-> Three or More Stories-One 0 0
-> Three or More Stories-Three Or More 4 16
-> Three or More Stories-Two 0 2
-> Three Or More-Multi/Split 7 3
-> Three Or More-Split Level 0 2
-> Tri-Level 32 3
-> Tri-Level-Three Or More 0 3
-> Tri-Level-Two 1 0
-> Two 4224 423
-> Two Story 491 31
-> Two Story-One 2 0
-> Two Story-Three Or More 0 1
-> Two Story-Two 15 27
-> Two-Multi/Split 25 2
-> Two-Three Or More 9 2
-> Two-Three Or More-Multi/Split 0 014.5.4.2 Codificação Dummy
As variáveis fictícias podem ser utilizadas com modelos de regressão simples ou múltiplos em situações em que uma ou mais variáveis nominais (categóricas) devam ser incorporadas no modelo. Para alguma variável categórica ser introduzida no modelo, deve-se criar uma ou mais variáveis assumindo valores numéricos, representando as categorias da variável nominal, onde essas variáveis criadas são as variáveis fictícias.
Uma variável fictícia pode ser representada por uma variável nominal \((A)\) com \(k\) categorias \((A_1, A_2, \ldots, A_k)\) – definindo \((k-1)\) variáveis, \(Z_1, Z_2, \ldots, Z_{k-1}\), assumindo dois valores (0 e 1) de forma que para \(i = 1, 2, 3, \ldots, k-1\), tem-se:
- \(Z_i = 1\) se a unidade amostral pertence à categoria \(A_i\)
- \(Z_i = 0\) se a unidade amostral pertence à categoria \(A_j\), com \(j \neq i\)
Dessa forma a variável \(Z_i\) foi definida, se tivermos a sequência \((1,0,0,0,\ldots,0)\) a unidade amostral em questão estará classificada na categoria \(A_1\), analogamente outras sequências:
- \((0,1,0,0,\ldots,0)\) para categoria \(A_2\)
- \((0,0,0,\ldots,1)\) para categoria \(A_{k-1}\)
- \((0,0,0,\ldots,0)\) para categoria \(A_k\)
A categoria \(A_k\) é denominada categoria de referência ou categoria base. Este esquema evita multicolinearidade perfeita em modelos de regressão, pois a informação da categoria de referência está implícita nas demais variáveis. Os coeficientes estimados para cada variável dummy representam o efeito diferencial daquela categoria em relação à categoria de referência.
- Vantagens: evita multicolinearidade perfeita em modelos de regressão; interpretação direta dos coeficientes em relação à categoria de referência.
Vejamos as frequências de cada rótulo
->
-> Listed for sale Listing removed Price change Sold
-> 19130 1849 3531 995Criamos agora 3 variáveis dummy e removemos a variável event. Se as três variáveis dummy criadas assumem os seguintes valores binários:
event_Listing removed=0event_Price change=0event_Sold=0
estamos diante de uma observação do nivel de referência Listed for sale.
library(fastDummies)
dados_clean=dummy_cols(
dados_clean,
select_columns = "event",
remove_first_dummy = TRUE,
remove_selected_columns = TRUE
)Vejamos como ficou o dataset
-> [1] "bathrooms" "bedrooms" "buildingArea"
-> [4] "city" "cityId" "country"
-> [7] "county" "countyId" "currency"
-> [10] "datePostedString" "description" "event_Listing removed"
-> [13] "event_Price change" "event_Sold" "garageSpaces"
-> [16] "hasBadGeocode" "hasGarage" "hasPetsAllowed"
-> [19] "homeType" "id" "is_bankOwned"
-> [22] "is_forAuction" "isNewConstruction" "latitude"
-> [25] "levels" "livingArea" "livingAreaValue"
-> [28] "longitude" "lotAreaUnits" "parking"
-> [31] "pool" "price" "pricePerSquareFoot"
-> [34] "spa" "state" "stateId"
-> [37] "streetAddress" "time" "time_date"
-> [40] "time_formatted" "X" "yearBuilt"
-> [43] "zipcode"14.5.4.3 One-Hot Encoding
O one-hot encoding é uma variante da codificação dummy que cria \(k\) variáveis binárias para \(k\) categorias, sem definir uma categoria de referência. Para uma variável nominal \((A)\) com \(k\) categorias \((A_1, A_2, \ldots, A_k)\), definem-se \(k\) variáveis, \(Z_1, Z_2, \ldots, Z_k\), assumindo dois valores (0 e 1) de forma que para \(i = 1, 2, 3, \ldots, k\), tem-se:
- \(Z_i = 1\) se a unidade amostral pertence à categoria \(A_i\)
- \(Z_i = 0\) se a unidade amostral pertence à categoria \(A_j\), com \(j \neq i\)
Dessa forma, cada observação é representada por um vetor onde exatamente uma posição assume valor 1 e todas as demais assumem 0:
- \((1,0,0,\ldots,0)\) para categoria \(A_1\)
- \((0,1,0,\ldots,0)\) para categoria \(A_2\)
- \((0,0,1,\ldots,0)\) para categoria \(A_3\)
- \((0,0,0,\ldots,1)\) para categoria \(A_k\)
Diferentemente da codificação dummy, todas as categorias são representadas explicitamente, sem categoria de referência implícita. Esta propriedade torna o one-hot encoding simétrico em relação a todas as categorias.
-Vantagens: representação simétrica de todas as categorias; adequado para algoritmos baseados em distâncias e redes neurais. Todavia, introduz multicolinearidade perfeita em modelos lineares; maior dimensionalidade que a codificação dummy.
14.6 Repartições em Treino e Validação
A divisão dos dados em conjuntos de treino e validação é fundamental para avaliação imparcial do desempenho preditivo.
Duas abordagens principais são:
- a repartição aleatória, que seleciona observações independentemente de suas características
- e a repartição estratificada, que mantém a proporção de classes ou grupos presentes nos dados originais em ambos os conjuntos.
A escolha da variável para estratificação deve considerar: (1) variáveis altamente desbalanceadas ou com distribuição heterogênea; (2) variáveis que representam o desfecho de interesse ou grupos importantes para a análise; (3) variáveis preditoras críticas cuja representação proporcional é essencial para validade dos resultados.
A estratificação por múltiplas variáveis é adequada quando há interdependências relevantes entre as variáveis ou quando múltiplos fatores determinam padrões importantes nos dados.
# Definir proporção treino/validação
prop_treino <- 0.8
# Repartição ALEATÓRIA
set.seed(123)
indice_aleatorio <- sample(1:nrow(dados_clean),
size = nrow(dados_clean) * prop_treino)
treino_aleatorio <- dados_clean[indice_aleatorio, ]
validacao_aleatorio <- dados_clean[-indice_aleatorio, ]
# Repartição ESTRATIFICADA por UMA VARIÁVEL (event_factor)
# Verificar se dados_clean tem dados suficientes e se event_factor existe
if(nrow(dados_clean) >= 2 && "event_factor" %in% names(dados_clean)) {
library(caret)
set.seed(123)
indice_estratificado <- createDataPartition(dados_clean$event_factor,
p = prop_treino,
list = FALSE)
treino_estratificado <- dados_clean[indice_estratificado, ]
validacao_estratificado <- dados_clean[-indice_estratificado, ]
} else {
message("Dados insuficientes ou variável event_factor não encontrada")
}
# Repartição ESTRATIFICADA por MÚLTIPLAS VARIÁVEIS
if(nrow(dados_clean) >= 2 && all(c("event_factor", "outra_variavel") %in% names(dados_clean))) {
library(sampling)
set.seed(123)
dados_clean$estrato <- paste(dados_clean$event_factor,
dados_clean$outra_variavel,
sep = "_")
tamanho_treino <- round(nrow(dados_clean) * prop_treino)
indice_multi <- strata(dados_clean,
stratanames = "estrato",
size = proportional(dados_clean$estrato, tamanho_treino),
method = "srswor")$ID_unit
treino_multi <- dados_clean[indice_multi, ]
validacao_multi <- dados_clean[-indice_multi, ]
dados_clean$estrato <- NULL # Remover coluna auxiliar
} else {
message("Dados insuficientes ou variáveis necessárias não encontradas")
}14.8 Análise Exploratória
A análise exploratória de dados ( EDA: Exploratory Data Analisys , originalmente desenvolvida pelo matemático e estatístico norte-americano John Tukey na década de 1970) é usada para se investigar conjuntos de dados e resumir suas principais características, muitas vezes usando métodos de visualização de dados por gráficos e apresentação de tabelas.

Figure 14.1: John Tukey (1915-2000)
Habitualmente uma EDA envolve:
- verificar quais são os tipos de variáveis presentes nos dados;
- verificar os padrões de cada variável e eventuais associações entre duas ou mais delas; e,
- apresentar os valores assumidos por cada uma das variáveis em formas resumidas como:
- resumos (sínteses) numéricos
- tabulares e
- gráficos.
14.9 Seleção de Variáveis Regressoras
stepAIC bestGLM
Nesta abordagem o problema específico é a escolha das variáveis regressoras para serem incluídas no modelo de regressão múltipla, ou seja, devem-se incluir todas as variáveis regressoras disponíveis ou incluir apenas um subconjunto destas variáveis. Após a decisão das variáveis regressoras selecionadas, verificar a significância e a adequação do novo modelo ajustado e realizar a análise de resíduo.
Seguem os seguintes procedimentos:
- Todas regressões possíveis
- Método “passo a frente” (forward)
- Método “passo atrás” (backward)
- Método “passo a passo” (stepwise)
14.9.1 Todas as Regressões Possíveis
Essa abordagem requer o ajuste de todas as equações de regressão envolvendo uma variável candidata, todas equações de regressão envolvendo duas variáveis candidatas e assim por diante. As equações serão avaliadas de acordo com alguns critérios:
- Coeficiente de determinação múltipla \((R^2)\)
- Coeficiente de determinação múltipla ajustado \((R_a^2)\)
- Quadrado médio do resíduo \((QMRes_{(p)})\)
- Estatística \(C_p\) de Mallows
onde \(C_p\) é uma medida da média quadrática total do erro para o modelo de regressão. As equações de regressão que tenham tendenciosidade negligenciável terão valores de \(C_p\) próximos de \(p\), e aquele com tendenciosidade significativa terão valores maiores que \(p\). Baseando-se nessa estatística a “melhor” equação de regressão terá o modelo com valor mínimo de \(C_p\).
14.9.2 Método “Passo Atrás” (Backward)
O procedimento caracteriza-se por incorporar, inicialmente, todas as variáveis auxiliares em um modelo de regressão múltiplo (completo) e percorre etapas, nas quais uma variável por vez pode ser eliminada, conforme a menor correlação parcial com \(Y\); menor coeficiente de determinação ou menor diminuição no teste F parcial. Se numa dada etapa não houver eliminação de alguma variável, o processo é então interrompido e as variáveis restantes definem o modelo final.
Etapas:
Passo 1: Ajustar o modelo completo de \((k)\) variáveis e obter \(SQReg^c\), \(\hat{\sigma}^2\) e \(glres = (n-p)\)
Passo 2: Para cada uma das \(k\) variáveis do modelo completo do passo 1, considerar o modelo reduzido – retirando esta variável – e calcular \(SQReg^r\) e obter a estatística teste F parcial:
\[F = \frac{SQReg^c - SQReg^r}{QMRes^c}\]
Passo 3: Achar \(F_{min}\)
Passo 4: Seja \(F_{sai}\) o quantil especificado da distribuição \(F\) com 1 e \((n-p\) ou \(n-k-1)\) graus de liberdade:
- Se \(F_{min} > F_{sai}\): interromper o processo e optar pelo modelo completo desta etapa
- Se \(F_{min} < F_{sai}\): voltar ao passo 1, iniciando nova etapa em que o modelo completo tenha \((k-1)\) variáveis – dada a eliminação da variável cujo modelo seja igual a \(F_{min}\)
14.9.3 Método “Passo a Frente” (Forward)
O procedimento se caracteriza, pois inicialmente, toma-se a variável auxiliar ou a variável de maior coeficiente de correlação amostral observada com a variável resposta, \(Y\). Sucessivamente, uma variável por vez é incorporada, conforme a maior correlação parcial com \(Y\); maior coeficiente de determinação ou maior aumento significativo no teste F parcial. O procedimento está baseado no princípio de que os regressores devem ser adicionados ao modelo, um de cada vez, até que não haja mais candidatos a regressor que produzam um aumento na soma de quadrado de regressão.
Se numa etapa não houver uma inclusão, o processo é interrompido e as variáveis selecionadas até o momento definem o modelo final.
Etapas:
Passo 1: Ajustar o modelo reduzido de \(k=1\) variável e obter \(SQReg^r\)
Passo 2: Para cada variável que não pertence ao modelo passo 1, considerar o modelo completo com a adição desta variável extra e calcular \(SQReg^c\), \(\hat{\sigma}^2\) e obter o valor da estatística teste:
\[F = \frac{SQReg^c - SQReg^r}{QMRes^c}\]
Passo 3: Achar \(F_{max}\)
Passo 4: Seja o \(F_{entra}\) o quantil especificado da distribuição \(F\) com \([1\) e \((n-p)]\) graus de liberdade:
- Se \(F_{max} > F_{entra}\): retornar ao passo 1, iniciando nova etapa onde o modelo reduzido tem \(k = (k+1)\) variáveis – dada a inclusão da variável cuja estatística teste é igual a \(F_{max}\)
- Se \(F_{max} < F_{entra}\): interromper o processo e optar pelo modelo reduzido desta etapa
14.9.4 Método “Passo a Passo” (Stepwise)
O procedimento é uma generalização do procedimento “passo a frente”, quando após cada etapa de incorporação de uma variável, tem-se uma etapa em que uma das variáveis selecionadas pode ser descartada. O processo é finalizado quando nenhuma variável é incluída ou descartada.
Etapas:
Passo 1: Ajustar o modelo reduzido de \(k\) variáveis e obter \(SQReg^r\)
Passo 2: Para cada variável que não pertence ao modelo do passo 1, considerar o modelo completo – com adição desta variável extra – e calcular \(SQReg^c\), \(\hat{\sigma}^2\) e obter a estatística teste:
\[F = \frac{SQReg^c - SQReg^r}{QMRes^c}\]
Passo 3: Achar \(F_{max}\)
Passo 4: Seja \(F_{entra}\) o quantil especificado da distribuição \(F\) com \([1\) e \((n-p)]\) graus de liberdade:
- Se \(F_{max} > F_{entra}\): passar ao passo 5, com modelo completo composto por \((k+1)\) variáveis – as variáveis do modelo do passo 1 e a variável cuja estatística teste é igual a \(F_{max}\)
- Se \(F_{max} < F_{entra}\): passar ao passo 5, com modelo completo igual ao modelo do passo 1 ou encerrar o processo se no passo 8 da etapa anterior, nenhuma variável tiver sido eliminada
Passo 5: Ajustar o modelo completo de \(k\) variáveis – com \(k+1\) variáveis e obter \(SQReg^c\), \(\hat{\sigma}^2\) com \((n-p)\) g.l.
Passo 6: Para cada uma das \(k\) variáveis do modelo completo do passo 5, considerar o modelo reduzido – retirando esta variável – e calcular \(SQReg^r\) \((n-p)\) g.l. e obter a estatística teste:
\[F = \frac{SQReg^c - SQReg^r}{QMRes^c}\]
Passo 7: Achar \(F_{min}\)
Passo 8: Seja \(F_{sai}\) o quantil especificado da distribuição \(F\) com \([1\) e \((n-k-1)]\) graus de liberdade:
- Se \(F_{min} > F_{sai}\): não eliminar nenhuma variável e voltar ao passo 1, iniciando nova etapa com modelo reduzido com \(k=m\) variáveis ou encerrar o processo se no passo 4, nenhuma variável tiver sido anexada
- Se \(F_{min} < F_{sai}\): eliminar a variável cuja estatística teste for igual a \(F_{min}\) e voltar ao passo 1 iniciando nova etapa com modelo reduzido com \(k-1\) variáveis
Obs: Quanto aos graus de liberdade, sempre utilizar \(gl = n-p\), sendo \(p\) o número de parâmetros envolvidos no modelo que está sendo testado. Sempre observar o valor de \(p\) utilizado na estimativa da variância residual.
Seleção de variáveis no R:
require(Rcmdr)
# Método backward
stepwise(modelo, direction = "backward", criterion = "AIC")
# Método forward
stepwise(modelo, direction = "forward", criterion = "AIC")
# Método stepwise
stepwise(modelo, direction = "both", criterion = "AIC")O modelo de regressão linear múltiplo considerando duas categorias para variável fictícia:
\[Y = \beta_0 + \beta_1 x + \beta_2 z + \beta_3 xz + e\]
onde:
- \(Y\) é a variável resposta
- \(x\) é a variável regressora
- \(z\) é a variável categórica
Na forma matricial \(Y = X\boldsymbol{\beta} + e\):
\[X = \begin{bmatrix} 1 & x_1 & z_1 & x_1z_1 \\ 1 & x_2 & z_2 & x_2z_2 \\ \vdots & \vdots & \vdots & \vdots \\ 1 & x_n & z_n & x_nz_n \end{bmatrix} \quad e \quad \boldsymbol{\beta} = \begin{bmatrix} \beta_0 \\ \beta_1 \\ \beta_2 \\ \beta_3 \end{bmatrix}\]
Exemplo: Para verificar se existem diferenças quando são levados em conta os salários de homens e mulheres, separadamente dois modelos:
- Para \((Z=0)\) tem-se: \(Y_1 = \beta_0 + \beta_1 x\)
- Para \((Z=1)\) tem-se: \(Y_2 = (\beta_0 + \beta_2) + (\beta_1 + \beta_3)x\)
Estimar o vetor dos parâmetros temos: \(\hat{\boldsymbol{\beta}} = (X'X)^{-1}X'Y\).
Estimação de parâmetros com variável qualitativa no R:
14.9.4.1 Teste de Coincidência das Retas
O teste para verificar se um único modelo se ajusta para ambas as categorias é realizado nas seguintes hipóteses:
- \(H_0: \beta_2 = \beta_3 = 0\)
- \(H_1\): pelo menos um difere de zero
Usa-se a estatística F parcial:
\[F(Z,XZ|X) = \frac{(SQReg(X,Z,XZ) - SQReg(X))/2}{QMRes(X,Z,XZ)}\]
e tem distribuição \(F(r, glres)\), logo rejeita-se \(H_0\) em favor \(H_1\) se F-parcial \(> F(r, glres; \alpha)\).
Teste de coincidência das retas no R:
14.9.4.2 Teste de Paralelismo das Retas
O teste para verificar se os dois modelos são paralelos, basta testar as hipóteses:
- \(H_0: \beta_3 = 0\)
- \(H_1: \beta_3 \neq 0\)
e a estatística teste:
\[T_{\beta_3} = \frac{\hat{\beta}_3}{\sqrt{QMRes \cdot C_{33}}}\]
que sob a hipótese nula, tem distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade e para um teste de nível \(\alpha\), rejeitamos \(H_0\) se \(|T_{\beta_3}| > t_{\alpha/2;(glres)}\).
Teste de paralelismo das retas no R:
14.9.4.3 Teste da Igualdade dos Interceptos
O teste para verificar a igualdade dos interceptos, basta testar as seguintes hipóteses:
- \(H_0: \beta_2 = 0\)
- \(H_1: \beta_2 \neq 0\)
e a estatística teste:
\[T_{\beta_2} = \frac{\hat{\beta}_2}{\sqrt{QMRes \cdot C_{22}}}\]
que sob a hipótese nula, tem distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade, e para um teste de nível \(\alpha\), rejeitamos \(H_0\) se \(|T_{\beta_2}| > t_{\alpha/2;(glres)}\).
Teste da igualdade dos interceptos no R: