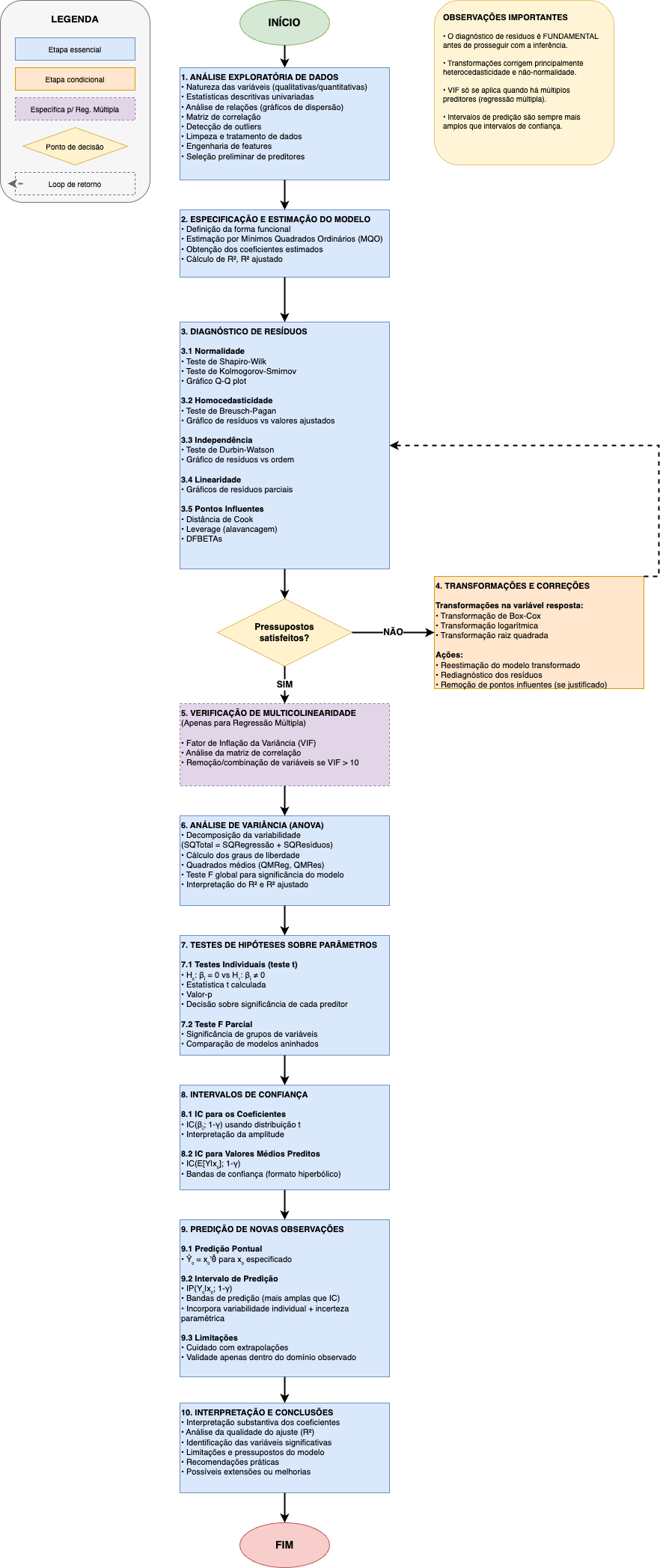
Capítulo 13 Introdução à Regressão Linear

“Essentially, all models are wrong, but some are useful […]” (George Edward Pelham Box, 1919 - 2013)
13.1 Contexto
Em Family Likeness in Stature, apresentado à Royal Society of London em janeiro de 1886, Francis Galton e J. D. Hamilton observaram que, embora houvesse uma tendência os filhos de pais mais altos tivessem uma maior estatura e, no sentido reverso, pais mais baixos tivessem filhos mais baixos, a estatura média de crianças nascidas de pais com dada altura tendia a regredir à altura média da população (paradoxo).
“Each peculiarity in a man is shared by his kinsman but, on the average, in a less degree[…] (Cada peculiaridade em um homem é compartilhada por seus parentes, mas, em média, em menor grau[…]-trad. livre)”
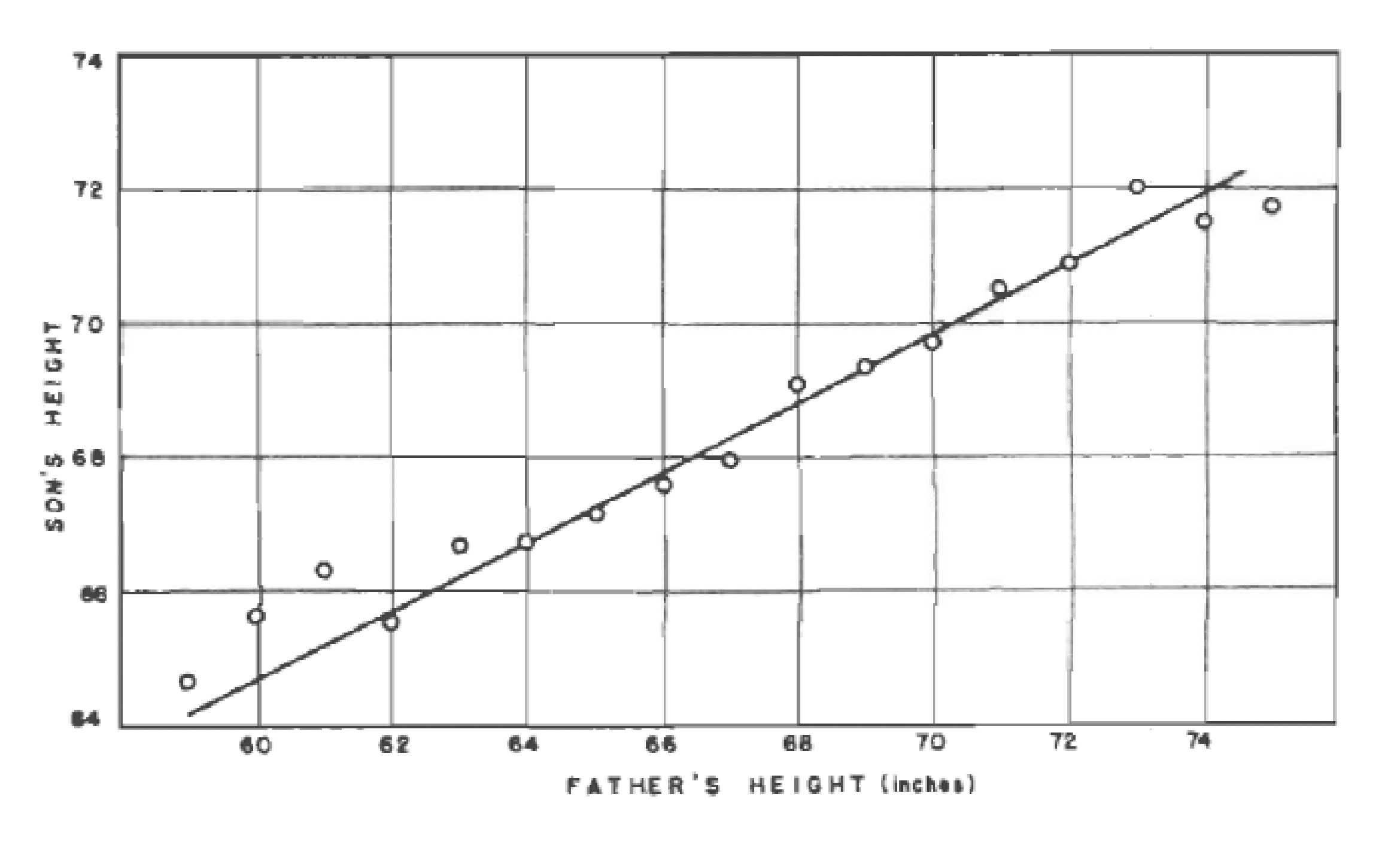
On the Laws of Inheritance (1903) Karl Pearson analisou os dados da estatura, tamanho do antebraço e da palma da mão de milhares de individuos, comprovando empiricamente a Lei da Regressão de Galton.
13.2 Conceitos iniciais
Ao estudar os mais variados fenômenos existentes no mundo natural, a ciência procura compreendê-los e descrevê-los por meio de relações entre as variáveis envolvidas. Essa relação pode ser representada por um modelo matemático, que associa uma variável explicada a uma ou mais variáveis explicativas.
Em epistemologia, um modelo é uma simplificação de um sistema (conjunto de elementos ou componentes inter-relacionados) utilizado para compreender a realidade.
Modelos funcionam como ferramentas epistêmicas para a investigação, diferentemente de teorias completas.
Modelos nos permitem focar em certos aspectos (variáveis analisadas) enquanto omite outros, permitindo um raciocínio substitutivo (aprender a partir dele) possibilitando obter insights sobre o sistema (fenômeno) real.
13.2.1 Relação das variáveis estudadas e o fenômeno estudado:
Variável dependente (explicada, prevista, regressando, resposta, endógena, saída, controlada, target)
Variável(is) independente(s) (explicativa, previsora, regressora, estímulo, exógena, entrada, controle, features)
Em geral estudamos a relação de uma única variável dependente \(Y\) com \(k\) variáveis independentes \(X_1, X_2, \ldots, X_k\).
13.2.2 Natureza das variáveis:
- Variáveis qualitativas (não métricas, labels): rotuláveis
- ordinais (nível de escolaridade, classe de rendimento, padrão construtivo)
- nominais (cor dos olhos, sexo, naturalidade)
- ordinais (nível de escolaridade, classe de rendimento, padrão construtivo)
- Variáveis Quantitativas (métricas): mensuráveis, contáveis
- discretas (anos completos de idade/escolaridade, degraus de uma escada, andares de um edifício).
- contínuas (pesos, velocidades, comprimentos, áreas, volumes, tempo?)
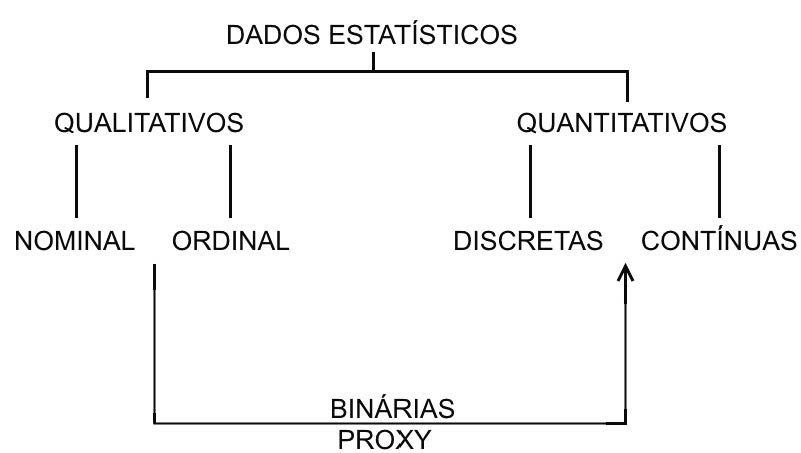
Quadro esquemático sobre a natureza das variáveis.
13.2.3 Modelos Estatísticos e de Machine Learning
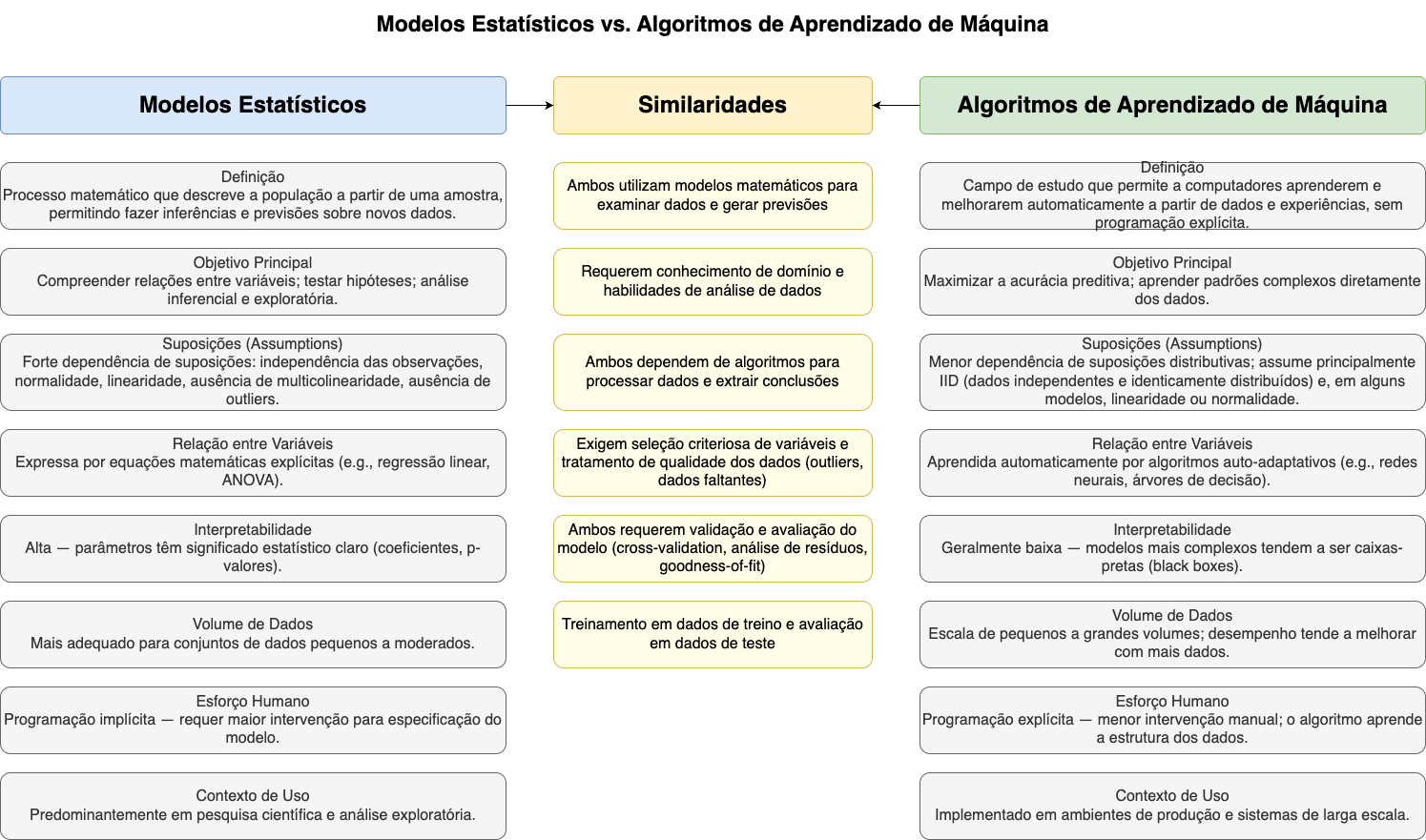
Modelos Estatísticos e Modelos de Machine Learning.
13.2.4 Modelos Estatísticos Clássicos
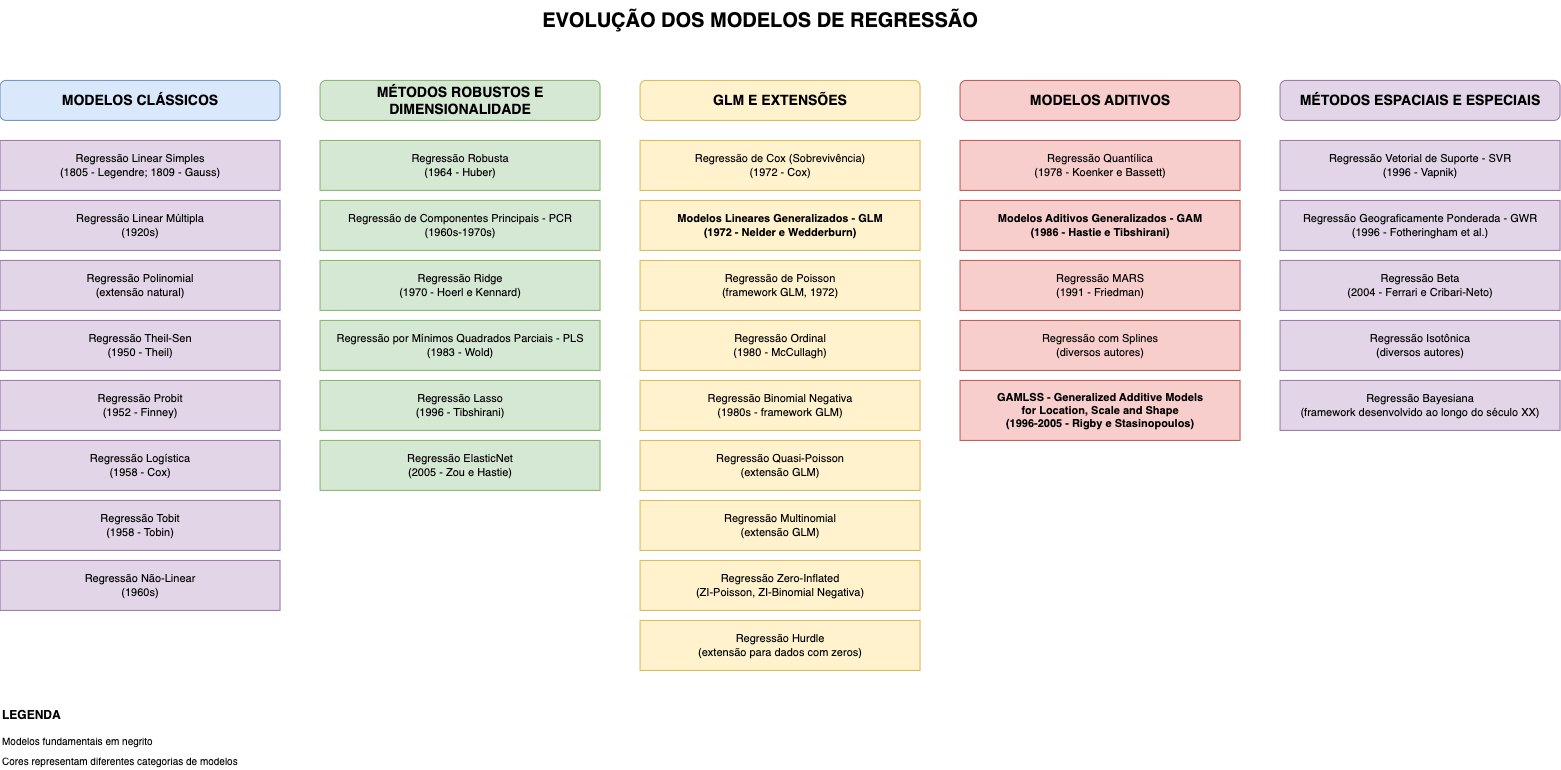
Alguns modelos de inferência (Leo Breiman, in “Statistical Modeling: The Two Cultures”, 2001)
13.2.5 Modelos de Regressão Linear
Um modelo de regressão pode ser linear nas variáveis ou nos parâmetros. A linearidade nos parâmetros é a relevante para a formulação da teoria da regressão.
Uma função é linear nos parâmetros se pode ser expressa como uma combinação linear dos parâmetros, onde nenhum parâmetro está elevado a uma potência ou multiplicado por outro parâmetro.
Exemplos de modelos lineares nos parâmetros:
- \(Y = \alpha + \beta X^2\) (linear nos parâmetros, não linear em \(X\))
- \(Y = \alpha + \beta \ln(X)\)
- \(Y = \alpha + \beta_1 X + \beta_2 X^2\)
Exemplos de modelos não lineares nos parâmetros:
- \(Y = \alpha e^{\beta X}\)
- \(Y = \alpha X^{\beta}\)
13.2.6 Regressão Linear Simples e Múltipla
Na regressão linear simples, objetiva-se determinar a relação entre uma única variável preditora \(X\) e uma variável resposta \(Y\) mediante a observação do fenômeno de interesse na população onde ele se manifesta.
Em experimentação, o pesquisador define os valores de \(X\) e observa os valores correspondentes de \(Y\) num experimento controlado.
Todavia, raramente fenômenos naturais decorrem de um único fator.
A regressão linear múltipla estende o conceito da regressão simples para incorporar \(p\) variáveis explicativas \((X_1, X_2, \ldots, X_p)\) ao modelo, permitindo analisar a relação de múltiplas variáveis independentes e a variável resposta \(Y\). Um modelo de regressão linear múltipla é expresso como:
\[ Y = \alpha + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_p X_p + \varepsilon \]
em que \(\alpha\) é o intercepto, \(\beta_j\) são os coeficientes angulares (ou coeficientes parciais de regressão), e \(\varepsilon\) é o erro aleatório.
Vantagens (poder) da Regressão Múltipla:
- Modela simultaneamente o efeito de múltiplas variáveis sobre a resposta.
- Permite controlar o efeito de variáveis confundidoras.
- Aumenta o poder explicativo do modelo.
- Possibilita análise da contribuição individual de cada preditor mantendo os demais fixos.
Interpretação dos Coeficientes:
Na regressão múltipla, um coeficiente \(\beta_j\) representa a variação esperada em \(Y\) quando a variável \(X_j\) aumenta em uma unidade, mantendo-se todas as demais variáveis constantes (coeficiente parcial).
13.3 Regressão Linear Simples
Considerem a proposição de John Maynard Keynes para a relação linear simplificada entre o consumo e a renda:
\[ Y = \alpha + \beta \cdot X, \]
em que \(Y\) representa o total das despesas de consumo e \(X\) a renda.
Esse modelo admite como linear a relação entre o total despendido em consumo e o total dos rendimentos. É um modelo teórico, pois pretende exprimir por uma relação exata (determinística) o consumo e a renda, quando se sabe que grande parte das relações entre duas variáveis num fenômeno natural não são lineares, muito menos exatas.
Ao se fixar um certo valor para a variável \(X\) observa-se na população existir flutuações nos valores da variável \(Y\) (os consumos das famílias com mesma renda não são os mesmos), o que evidencia que o fenômeno envolve um componente aleatório.
13.3.1 Amostragem
Sendo inviável e, algumas vezes impossível, observar todos os efeitos do fenômeno na população, invariavelmente focamos o estudo em uma parte observada (extraída) dessa população: uma amostra.

Universo (parâmetros) e amostras (estimativa/estatísticas)
Os coeficientes de um modelo ajustado com base em uma amostra são estimativas dos parâmetros desconhecidos dessa função de regressão populacional:
\[ Y = \alpha + \beta \cdot X \]
Por isso, adota-se uma notação diferente para a função de regressão amostral:
\[ \hat{Y} = a + b \cdot X \]
em que:
- \(\hat{Y}\) é um estimador de \(Y\)
- \(a\) é uma estimativa do parâmetro \(\alpha\).
- \(b\) é uma estimativa do parâmetro \(\beta\).
Para cada valor \(x_i\) presente na amostra extraída temos o valor observado \(y_i\).
A função de regressão amostral aplicada ao valor \(x_i\) nos retorna um valor \(\hat{y}_i = a + b \cdot x_i\) ao qual denominamos como valor estimado.
A diferença \((y_i - \hat{y}_i)\) é chamada de resíduo de ajuste para a \(i\text{-ésima}\) observação: \(e_i\) e representa o desvio entre o valor observado e o valor predito pelo modelo.
Se o modelo nos retorna um valor estimado diferente do valor observado somos frequentemente tentados a pensar por que então não formular esse modelo com o máximo de variáveis possíveis?
- Embasamento teórico vago: a teoria existente suporta com certeza apenas algumas variáveis.
- Princípio da parcimônia: um modelo mais simples que explique bem a relação é preferível.
- Forma funcional equivocada: em gráficos de dispersão, é mais fácil inferir a relação entre duas variáveis do que com muitas.
- Limitação na quantidade de observações: muitas variáveis exigem mais observações para garantir a precisão do modelo.
Assim, agregamos à nossa função populacional um termo aleatório denominado erro:
\[ Y_{i} = \alpha + \beta \cdot X_{i} + \varepsilon_i, \]
e à função amostral incorporamos a estimativa desse termo, denominada de resíduo:
\[ \hat{Y}_i = a + b \cdot X_i + e_i. \]
Erro é o termo \(\varepsilon_i\) no modelo populacional \(Y_{i} = \alpha + \beta \cdot X_{i} + \varepsilon_i\), inobservável por definição, pois \(\boldsymbol{\beta}\) é desconhecido.
Resíduo é \(e_{i} = \hat{Y}_i - (a + b \cdot X_i)\), sua contraparte amostral, observável após a estimação.
| Símbolo | Descrição / Estimativa de |
|---|---|
| \(a\) | Estimativa do parâmetro populacional \(\alpha\) |
| \(b\) | Estimativa do parâmetro populacional \(\beta\) |
| \(e\) | Contraparte observável do erro \(\varepsilon\), dada por \((Y-\hat{Y})\) |
Deduz-se assim que o melhor modelo será aquele cujos resíduos sejam, em algum sentido, os menores possíveis. Mas como determinar os valores de \(a\) e \(b\) que produzem esse melhor ajuste?
13.4 Método dos Mínimos Quadrados
Aos 18 anos Johann Carl Friedrich Gauss considerou sua descoberta do método dos mínimos quadrados (1795) tão evidente que chegou a classificá-la como trivial, imaginando não ter sido o primeiro a utilizá-la. Por essa razão, não tornou pública sua descoberta até anos mais tarde, na obra Theoria motus corporum coelestium in sectionibus conicis solem ambientium (1809).

Johann Carl Friedrich Gauss
Nesse intervalo, seu contemporâneo Adrien-Marie Legendre havia publicado o método em Nouvelles méthodes pour la détermination des orbites des comètes (1805).

Adrien-Marie Legendre
Quando Gauss reivindicou a precedência, instaurou-se uma das mais célebres disputas de prioridade na história da ciência. Ao final, Gauss recebeu a maior parte do crédito como fundador da regressão estatística — conquista que, contudo, não se deu sem controvérsia.
Na literatura estatística há vários métodos de estimação dos parâmetros de um modelo de regressão linear, dentre os quais:
- Método dos mínimos quadrados: desenvolvido por Carl Friedrich Gauss (1795), publicado por Adrien-Marie Legendre (1805), Friedrich Robert Helmert (1872).
- Método dos momentos: introduzido por Pafnuty Chebyshev (1887), desenvolvido por Karl Pearson (1894-1895), e posteriormente generalizado por Lars Peter Hansen (Método Generalizado dos Momentos - GMM, 1982).
- Método da máxima verossimilhança: formas rudimentares foram utilizadas por Carl Friedrich Gauss, Pierre-Simon Laplace, Thorvald N. Thiele e Francis Ysidro Edgeworth; a versão moderna foi criada e popularizada por Ronald Aylmer Fisher (1912-1922).
Para um valor \(x_i\) a função de regressão amostral nos retorna um valor estimado:
\[ \hat{y}_{i}= a + b.x_{i} \]
O resíduo \(e_i=y_i-\hat{y}_i\) dessa estimação pode ser expresso em função de \(a\), \(b\) e \(x_i\):
\[ e_i=y_i - (a + bx_i). \]
em que \((x_i,y_i)\) é o par de valores observados e \(\hat{y}_i\) o valor estimado pela função para \(x_i\).
O problema se resume a determinar as constantes \(a\) e \(b\) da equação de uma linha reta que melhor se ajusta a três ou mais pontos não colineares.
A solução então passa pela minimização a soma dos quadrados dos resíduos (SIMULADOR 3):
\[ \min\left(\sum _{i=1}^{n}{e}_{i}^{2}\right). \]
13.4.1 Dedução para uma Regressão Linear Simples
O método dos mínimos quadrados (MMQ) é puramente geométrico: não faz nenhuma suposição sobre a distribuição dos dados ou dos erros. Em outras palavras, ele é aplicado sem se preocupar com a natureza probabilística. O objetivo é apenas ajustar a melhor reta possível para um conjunto de pontos de dados. A partir da igualdade:
\[ \sum _{i=1}^{n} [ y_{i} - \hat{y}_i ]^{2} = \sum _{i=1}^{n}{\left[y_i-\left(a+b{x}_{i}\right)\right]}^{2} \]
a solução passa por derivar-se em relação a \(a\) e em relação a \(b\), igualando-se a zero:
\[ \frac{\partial }{\partial a}\sum _{i=1}^{n}{\left[y_i-\left(a + b \cdot x_{i}\right)\right]}^{2}= 2 \cdot \sum _{i=1}^{n}\left(y_{i} - a - b \cdot x_{i}\right)\left(-1\right)=0 \\ \frac{\partial }{\partial b}\sum _{i=1}^{n}{\left[y_i-\left(a + b \cdot x_{i}\right)\right]}^{2}= 2\cdot \sum _{i=1}^{n}\left(y_{i} - a - b \cdot x_{i}\right)\left(-x_i\right)=0 \]
Expandindo as derivadas e simplificando (dividindo por 2 e removendo os sinais negativos):
\[ \sum _{i=1}^{n}\left(y_{i}-a-b \cdot x_{i}\right) = 0 \\ \sum _{i=1}^{n}\left(y_{i}-a-b \cdot x_{i}\right) \cdot x_i = 0 \]
Desenvolvendo a primeira equação:
\[ \sum _{i=1}^{n}y_{i} - \sum _{i=1}^{n}a - \sum _{i=1}^{n}b \cdot x_{i} = 0 \\ \sum _{i=1}^{n}y_{i} - n \cdot a - b \cdot \sum _{i=1}^{n}x_{i} = 0 \]
Desenvolvendo a segunda equação:
\[ \sum _{i=1}^{n}y_{i} \cdot x_i - \sum _{i=1}^{n}a \cdot x_i - \sum _{i=1}^{n}b \cdot x_{i}^2 = 0 \\ \sum _{i=1}^{n}y_{i} \cdot x_i - a \cdot \sum _{i=1}^{n}x_i - b \cdot \sum _{i=1}^{n}x_{i}^2 = 0 \]
Rearranjando ambas as equações, obtemos o sistema de equações normais:
\[ \begin{cases} a \cdot n + \left(\sum_{i=1}^{n}x_{i}\right) \cdot b = \sum_{i=1}^{n}y_{i} \\ \left(\sum_{i=1}^{n}x_{i}\right) \cdot a + \left(\sum_{i=1}^{n}x_{i}^{2}\right) \cdot b = \sum_{i=1}^{n}x_{i} \cdot y_{i} \end{cases} \]
ou, equivalentemente:
\[ \begin{cases} a \cdot n + b \cdot \sum_{i=1}^{n}x_{i} = \sum_{i=1}^{n}y_{i} \\ a \cdot \sum_{i=1}^{n}x_{i} + b \cdot \sum_{i=1}^{n}x_{i}^{2} = \sum_{i=1}^{n}x_{i} \cdot y_{i} \end{cases} \]
Após algumas manipulações algébricas obtemos as seguintes expressões para as estimativas: \(a\) e \(b\):
\[ a\cdot n + b\cdot \sum _{i=1}^{n}{x}_{i}=\sum _{i=1}^{n}{y}_{i} \]
\[ a\cdot \sum _{i=1}^{n}{x}_{i}+b\cdot \sum _{i=1}^{n}{x}_{i}^{2}=\sum _{i=1}^{n}{x}_{i}\cdot {y}_{i} \]
chegando-se à estimativa \(b\) do parâmetro \(\beta\), dada pelo estimador de mínimos quadrados:
\[ b=\frac{n\cdot \left(\sum _{i=1}^{n}{x}_{i}{y}_{i}\right)-\left(\sum _{i=1}^{n}{x}_{i}\right)\left(\sum _{i=1}^{n}{y}_{i}\right)}{n\cdot \sum _{i=1}^{n}{x}_{i}^{2}-{\left(\sum _{i=1}^{n}{x}_{i}\right)}^{2}}\\ =\frac{ \sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{\sum_{i=1}^{n}(x_{i}-\bar{x})^{2}} \]
e à estimativa \(a\) do parâmetro \(\alpha\), dada pelo estimador de mínimos quadrados:
\[ a=\frac{\left(\sum _{i=1}^{n}{x}_{i}^{2}\right)\cdot \left(\sum _{i=1}^{n}{y}_{i}\right)-\left(\sum _{i=1}^{n}{x}_{i}{y}_{i}\right)\cdot \left(\sum _{i=1}^{n}{x}_{i}\right)}{n\cdot \left(\sum _{i=1}^{n}{x}_i^{2}\right)-{\left(\sum _{i=1}^{n}{x}_{i}\right)}^{2}} \]
Se definirmos soma de produtos de \(x\) por \(y\) como:
\[ S_{xy} = \sum _{i=1}^{n} x_{i}y_{i} - \frac{\sum _{i=1}^{n}x_{i}\cdot\sum _{i=1}^{n}y_{i}}{n} \]
e a soma de quadrados dos desvios de \(x\) como:
\[ S_{xx} = \sum _{i=1}^{n} x_{i}^{2} - \frac{(\sum _{i=1}^{n} x_{i})^{2}}{n} \]
então podemos escrever:
\[ b = \frac{S_{xy}}{S_ {xx}}\\ \text{e} \\ a = \stackrel{-}{y} - b\cdot\stackrel{-}{x}. \]
Uma vez que
\[ \stackrel{-}{y}=\frac{\sum _{i=1}^{n}{y}_{i}}{n}\\ \text{e}\\ \stackrel{-}{x}=\frac{\sum _{i=1}^{n}{x}_{i}}{n} \]
o estimador de mínimos quadrados para \(a\) pode ser escrito como:
\[ a = \frac{\sum _{i=1}^{n}{y}_{i} - b . \sum _{i=1}^{n}{x}_{i}}{n} \]
Portanto, os valores de \(a\) e \(b\) dados pela relações acima são as estimativas de mínimos quadrados do intercepto e inclinação, respectivamente. O modelo de regressão linear simples ajustado é dado por:
\[ \hat{y}_i = a + b x_i \]
13.4.2 Estatísticas amostrais:
As variâncias amostrais \(s_x^2\) e \(s_y^2\) são dadas por:
\[ s_x^2 = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2 \\ = \frac{S_{xx}}{n-1} \]
\[ s_y^2 = \frac{1}{n-1}\sum_{i=1}^{n}(y_i - \bar{y})^2 \\ =\frac{S_{yy}}{n-1} \]
A covariância amostral é dada por:
\[ s_{xy} = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y}) \\ =\frac{S_{xy}}{n-1} \]
Do ponto de vista puramente matemático, variância e covariância amostrais são estatísticas descritivas - funções dos dados observados ou amostra extraída - independentemente de qualquer interpretação probabilística:
As variância amostrais \(s_{x}^2\) e \(s_{y}^2\) medem a dispersão dos valores \(x_i\) e \(y_i\) em torno de suas médias \(\bar{x}\) e \(\bar{y}\).
A covariância amostral \(s_{xy}\) indica a direção da relação linear entre os valores \(x_i\) e \(y_i\):
- Positiva: quando \(x_i\) aumenta, \(y_i\) tende a aumentar.
- Negativa: quando \(x_i\) aumenta, \(y_i\) tende a diminuir.
- Próxima de zero: indica ausência de relação linear entre \(X\) e \(Y\).
O valor da covariância amostral \(s_{xy}\) depende das unidades de medida de \(X\) e \(Y\), o que impede a comparação direta da intensidade da associação linear entre diferentes pares de variáveis.
Essa limitação motivou a introdução do coeficiente de correlação de Pearson, obtido pela normalização da covariância pelo produto dos desvios padrão:
\[
r = \frac{s_{xy}}{s_x \, s_y} = \frac{S_{xy}}{\sqrt{S_{xx}\, S_{yy}}},
\]
resultando em uma medida adimensional restrita ao intervalo \([-1, 1]\).
Se \(\hat{y}\) a expressão do valor de \(y\) para um dado valor de \(x\) dada pela reta de gressão, então uma medida da dispersão em relação à reta de regressão é fornecida pela quantidade:
\[ s_{y,x} = \sqrt{\frac{\sum_{i=1}^{n}(y_i - \hat{y}_i)^2}{n-2}}, \]
denominada de erro padrão da estimativa (\(s_{y,x}\): \(s\) de \(y\) dado \(x\) ou, \(s_{e}\))
Embora introduzidas aqui como estatísticas descritivas, as quantidades \(s_{x}^2\), \(s_{y}^2\) e \(s_{y,x}\) desempenham papel central na inferência sobre os parâmetros e estimativas do modelo de regressão.
Em particular, \(s_{y,x}\) é utilizado no cálculo dos erros padrão das estimativas \(a\) e \(b\), que fundamentam os testes de hipóteses e os intervalos de confiança para \(\alpha\) e \(\beta\).
Além disso, a precisão com que \(\beta\) é estimado depende diretamente da dispersão de \(X\): quanto maior \(s_x\), mais precisa é a estimativa do coeficiente angular \(b\).
Exemplo 1: Um jornal deseja verificar a eficácia de seus anúncios na venda de carros usados e para isso realizou um levantamento de todos os seus anúncios e informações dos resultados obtidos pelas empresas que o contrataram e dele extraiu uma pequena amostra. A tabela abaixo mostra o número de anúncios e o correspondente número de veículos vendidos por 6 companhias que usaram apenas este jornal como veículo de propaganda. Obtenha a equação de regressão linear simples e estime o número de carros vendidos para um volume de 70 anúncios?
| Companhia | Anúncios feitos (X) | Carros vendidos (Y) |
|---|---|---|
| A | 74 | 139 |
| B | 45 | 108 |
| C | 48 | 98 |
| D | 36 | 76 |
| E | 27 | 62 |
| F | 16 | 57 |
| Companhia | Anúncios (x) | Carros vendidos (y) | xi.yi | xi2 | yi2 |
|---|---|---|---|---|---|
| A | 74 | 139 | 10286 | 5476 | 19321 |
| B | 45 | 108 | 4860 | 2025 | 11664 |
| C | 48 | 98 | 4704 | 2304 | 9604 |
| D | 36 | 76 | 2736 | 1296 | 5776 |
| E | 27 | 62 | 1674 | 729 | 3844 |
| F | 16 | 57 | 912 | 256 | 3249 |
| Totais | 246 | 540 | 25172 | 12086 | 53458 |
| Valor médio | 41 | 90 |
Sendo \(n= 6\), \(\stackrel{-}{y}= 90\) e \(\stackrel{-}{x} = 41\):
\[ S_{xy} = \sum _{i=1}^{n} x_{i}y_{i} - \frac{\sum _{i=1}^{n}x_{i}\cdot\sum _{i=1}^{n}y_{i}}{n} = 25172 - \frac{246 \cdot 540}{6} = 3032 \\ S_{xx} = \sum _{i=1}^{n} x_{i}^{2} - \frac{(\sum _{i=1}^{n} x_{i})^{2}}{n} = 12086 - \frac{246^2}{6} = 2000 \\ {S}_{yy} = \sum _{i=1}^{n}y_{i}^{2} - \frac{(\sum _{i=1}^{n} y_{i})^{2}}{n}= 53458 - \frac{540^2}{6} = 4858 \]
As estimativas \(a\) e \(b\) dos parâmetros \(\alpha\) e \(\beta\) do modelo serão:
\[ b = \frac{S_{xy}}{S_ {xx}} = \frac{3032}{2000} = 1,5160 \]
e
\[
a = \stackrel{-}{y} - b\cdot\stackrel{-}{x} = 90 - 1,5160 \cdot 41 = 27,844
\]
e o modelo toma a seguinte forma \(\hat{y} = 27,844 + 1,5160 \cdot x\). Para um volume de anúncios de 70 veiculações teremos, em média, 134 carros vendidos.
# Dados
anuncios <- c(74, 45, 48, 36, 27, 16)
carros_vendidos <- c(139, 108, 98, 76, 62, 57)
X <- as.matrix(cbind(1, anuncios)) # Matriz X
Y <- as.matrix(cbind(carros_vendidos)) # Matriz Y
XtX <- t(X) %*% X # (X'X)
XtY <- t(X) %*% Y # X'Y
INV <- solve(XtX) # Inversa da matriz (X'X)
Betas <- INV %*% XtY # Coeficientes
# Resultados
cat("Equação:", sprintf("Y = %.3f + %.4f * X\n",
Betas[1], Betas[2]))
cat("Predição para 70 anúncios:",
round(Betas[1]+ Betas[2]*70), "carros\n")-> Equação: Y = 27.844 + 1.5160 * X
-> Predição para 70 anúncios: 134 carros# Dados do exemplo 1
anuncios <- c(74, 45, 48, 36, 27, 16)
carros_vendidos <- c(139, 108, 98, 76, 62, 57)
# Modelo
modelo <- lm(carros_vendidos ~ anuncios)
# Resultados
cat("Equação:", sprintf("Y = %.3f + %.4f * X\n",
coef(modelo)[1], coef(modelo)[2]))
cat("Predição para 70 anúncios:",
round(predict(modelo, data.frame(anuncios = 70))), "carros\n")-> Equação: Y = 27.844 + 1.5160 * X
-> Predição para 70 anúncios: 134 carros13.5 O Teorema de Gauss-Markov
O MMQ fornece estimativas para os parâmetros populacionais a partir de uma amostra específica. Contudo, diferentes amostras extraídas da mesma população onde se observa o fenômeno produzirão estimativas distintas.
Como quantificar a variabilidade dessas estimativas de modo a ser possível estabelecer intervalos para cada uma e associar uma medida de incerteza a eles?
Para responder a essa questão, pressuposições sobre a distribuição dos erros devem ser estabelecidas e constituem o arcabouço da inferência estatística em análise de regressão.
O Teorema de Gauss-Markov estabelece que, sob certos pressupostos, os estimadores de MQO são os BLUE (Best Linear Unbiased Estimators) ou seja, possuem a menor variância possível dentro da classe de todos os estimadores lineares e não-enviesados.
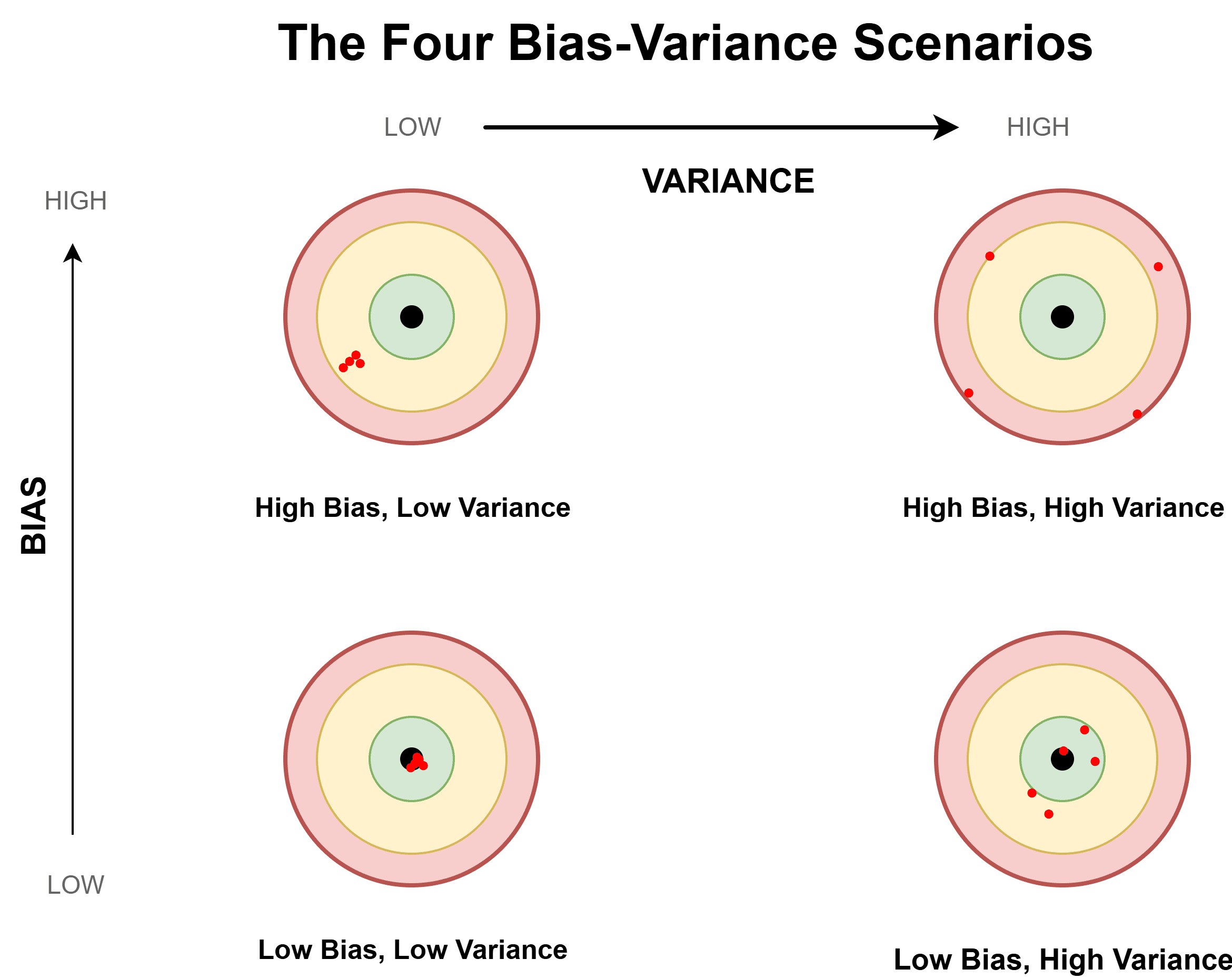
Precisão e enviesamento
13.5.1 Pressupostos
1.Linearidade nos parâmetros: O modelo deve ser linear em relação aos parâmetros \(\alpha\) e \(\beta\), ou seja, a variável dependente \(Y\) pode ser expressa como uma combinação linear desses parâmetros: \(Y_i = \alpha + \beta X_i + \varepsilon_i\).
Importante: A linearidade se refere aos parâmetros e não necessariamente à variável \(X\).
Por exemplo, os modelos \(Y = \alpha + \beta X^2 + \varepsilon\) ou \(Y = \alpha + \beta \ln(X) + \varepsilon\) ainda são lineares nos parâmetros \(\alpha\) e \(\beta\), mesmo que a relação com \(X\) seja não-linear.
Por outro lado, modelos como \(Y = \alpha \cdot e^{\beta X} \cdot \varepsilon\) ou \(Y = \alpha \cdot X^{\beta} \cdot \varepsilon\) não são lineares nos parâmetros (embora possam ser linearizados por transformações logarítmicas).
2.Exogeneidade (ou independência média): A média condicional dos erros é zero dado qualquer valor de \(X\): \(E[\varepsilon_i | X_i] = 0\). Isto implica que não há correlação sistemática entre a variável explicativa \(X\) e o termo de erro \(\varepsilon\).
Importante: Este pressuposto garante que \(X\) não carrega informação sobre o erro médio; ou seja, conhecer o valor de \(X_i\) não nos ajuda a prever \(\varepsilon_i\).
Violações deste pressuposto ocorrem quando há variáveis omitidas relevantes (que estão em \(\varepsilon\) mas correlacionadas com \(X\)), erros de medida em \(X\), ou simultaneidade (quando \(Y\) também influencia \(X\)).
Quando este pressuposto é violado, os estimadores de MQO são enviesados.
3.Homocedasticidade (Variância Constante): A variância do erro é constante para todas as observações, independentemente do valor de \(X\): \(Var(\varepsilon_i | X_i) = \sigma^2\) para todo \(i\).
Importante: Este pressuposto estabelece que a dispersão dos erros ao redor da linha de regressão é a mesma para todos os níveis de \(X\).
A violação deste pressuposto (heterocedasticidade) ocorre quando \(Var(\varepsilon_i | X_i) = \sigma_i^2\) varia com \(X_i\). Por exemplo, em dados de renda familiar versus gastos com alimentação, a variabilidade dos gastos tende a aumentar com a renda.
Sob heterocedasticidade, os estimadores de MQO permanecem não-enviesados, mas perdem eficiência (não são mais BLUE) e os erros padrão usuais ficam incorretos, comprometendo testes de hipóteses e intervalos de confiança.
4.Ausência de Autocorrelação: Os erros de observações diferentes não estão correlacionados entre si: \(Cov(\varepsilon_i, \varepsilon_j) = 0\) para todo \(i \neq j\), ou equivalentemente, \(E[\varepsilon_i \cdot \varepsilon_j] = 0\) para \(i \neq j\).
Importante: Este pressuposto é especialmente relevante para dados de séries temporais ou dados com estrutura espacial.
Em séries temporais, a autocorrelação ocorre quando o erro no período \(t\) está correlacionado com o erro no período \(t-1, t-2\), etc. Por exemplo, em dados mensais de vendas, choques positivos tendem a persistir por vários meses. Em dados espaciais, propriedades vizinhas tendem a ter erros correlacionados.
Sob autocorrelação, os estimadores de MQO permanecem não-enviesados, mas perdem eficiência e os erros padrão usuais tornam-se enviesados (sendo frequentemente subestimados em casos de autocorrelação positiva, comum em séries temporais).
O Teorema de Gauss-Markov não exige normalidade dos erros: sob esses quatro pressupostos, os estimadores de MQO já são os melhores estimadores lineares não-enviesados, mesmo que os erros não sejam normalmente distribuídos.
Todavia, mesmo sendo os BLUE, ele não nos permite fazer as inferências estatísticas que antes estabelecemos, tais como:
- construir intervalos de confiança para as estimativas
- realizar testes de hipóteses sobre seus valores
Para realizar inferências estatísticas, devemos fazer uma suposição adicional: os erros (\(\varepsilon_i\)) do modelo de regressão linear são variáveis aleatórias Normalmente distribuídas com média zero e variância constante:
\[
\varepsilon_i \sim N(0, \sigma^2)
\]
Cabe destacar que, embora a suposição de normalidade recaia sobre os erros populacionais \(\varepsilon_i\), os resíduos \(e_i = y_i - \hat{y}_i\) herdam essa propriedade. Como \(\mathbf{e} = (\mathbf{I} - \mathbf{H})\boldsymbol{\varepsilon}\) é uma transformação linear de \(\boldsymbol{\varepsilon} \sim N(\mathbf{0}, \sigma^2\mathbf{I})\), e dado que \((\mathbf{I} - \mathbf{H})\) é simétrica e idempotente, as propriedades de média e variância dos erros se propagam aos resíduos, resultando em \(\mathbf{e} \sim N(\mathbf{0},\ \sigma^2(\mathbf{I} - \mathbf{H}))\).
13.6 Modelo de Regressão Linear com Erros Normais
Consolidando os pressupostos de Gauss-Markov com a normalidade, temos que as premissas do modelo de regressão linear podem ser classificadas em quatro categorias:
1.Linearidade: A relação entre a variável preditora \(X\) e a variável resposta \(Y\) é linear nos parâmetros; o valor esperado da variável resposta é uma combinação linear dos parâmetros
2.Normalidade: \(\varepsilon_i \sim N(0, \sigma^2)\) — os erros são normalmente distribuídos com média zero e variância constante.
Este pressuposto (adicional aos pressupostos de Gauss-Markov não sendo necessário para garantir que os estimadores de MQO sejam BLUE) é fundamental em amostras pequenas (\(n < 30\)) para: (i) garantir que os estimadores \(a\) e \(b\) sejam também normalmente distribuídos, permitindo o uso das distribuições \(t\) e \(F\) para inferências; (ii) construir intervalos de confiança válidos; (iii) realizar testes de hipóteses
Para amostras grandes, o Teorema Central do Limite garante que os estimadores sejam aproximadamente normais mesmo sem este pressuposto.
3.Independência estatística dos resíduos: \(Cov(\varepsilon_i, \varepsilon_j) = E(\varepsilon_i \cdot \varepsilon_j) = 0\) para \(i \neq j\), e, em particular, nenhuma correlação entre erros de observações sucessivas no caso de dados provenientes de uma série.
Este pressuposto estabelece que o erro associado a uma observação não fornece informação sobre o erro de outra observação. A violação deste pressuposto (autocorrelação ou correlação serial) é particularmente comum em: (i) séries temporais; (ii) dados espaciais; (iii) dados em painel (múltiplas séries), com observações repetidas da mesma unidade ao longo do tempo.
A presença de autocorrelação não enviesa os estimadores de MQO, mas os torna ineficientes, distorcendo os erros padrão resultando em intervalos de confiança artificialmente estreitos e rejeição de \(H_0\) em testes de hipóteses.
4.Homocedasticidade: \(Var(\varepsilon_i) = E(\varepsilon_i^2) = \sigma^2\) — a variância dos erros é constante quando analisada frente aos valores estimados pelo modelo (\(\hat{Y}\)), a variável preditora (\(X\)) ou o índice temporal \(t\) nos casos de dados provenientes de uma série.
Este pressuposto requer que a dispersão dos erros seja uniforme ao longo da faixa de variação de \(X\) ou \(\hat{Y}\).
A violação (heterocedasticidade) ocorre quando \(Var(\varepsilon_i) = \sigma_i^2\) varia sistematicamente.
Sob heterocedasticidade, os estimadores de MQO permanecem não-enviesados e consistentes, mas perdem eficiência, e os erros padrão ficam incorretos, comprometendo a inferência.
13.6.1 Propriedades dos Estimadores sob Erro Normal
Para o modelo \(Y_{i}=\alpha+\beta\cdot X_{i}+\varepsilon_{i}\), demonstra-se que:
- \(b\) é um estimador não tendencioso de \(\beta\):
\[ E\left(b\right)=\beta \\ \text{e} \\ Var\left(b\right)=\frac{{\sigma }^{2}}{{S}_{xx}} \]
- \(a\) é um estimador não tendencioso de \(\alpha\):
\[ E\left(a\right)=\alpha\\ \text{e} \\ Var\left(a\right)={\sigma }^{2}\cdot \left(\frac{1}{n}+\frac{{\stackrel{-}{x}}^{2}}{{S}_{xx}}\right) \]
- \(\hat{\sigma^{2}}\) é um estimador não tendencioso de \(\sigma^{2}\):
\[ S^{2} = \text{QMRes} = \frac{S_{yy} -b \cdot S_{xy}}{(n-2)} \]
Assim os desvios padrão dos estimadores \(a\) e \(b\) serão
\[ S_{b} = \sqrt{\frac{{\hat{\sigma}}^{2}}{{S}_{xx}}} = \\ \sqrt{\frac{\text{QMRes}}{S_{xx}}} \]
\[ S_{a} = \sqrt{{\hat{\sigma} }^{2}\cdot \left(\frac{1}{n}+\frac{{\stackrel{-}{x}}^{2}}{{S}_{xx}}\right)} = \\ \sqrt{\text{QMRes} \cdot \left(\frac{1}{n}+\frac{{\stackrel{-}{x}}^{2}}{{S}_{xx}}\right)} \]
lembrando que:
\[ S_{xx} = \sum_{i=1}^{n} (x_i - \bar{x})^2, \\ S_{yy} = \sum_{i=1}^{n} (y_i - \bar{y})^2,\\ S_{xy} = \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y}),\\ (n - 2) \text{ são os graus de liberdade perdidos pela estimação de }\alpha \text{ e } \beta. \]
13.6.2 Consequências da Normalidade
A normalidade dos erros \(\varepsilon_i\) garante que os estimadores \(a\) e \(b\) também sejam Normalmente distribuídos em amostras finitas — e não apenas assintoticamente —, o que é fundamental para realizar inferências sobre o fenômeno estudado (testes de hipóteses e intervalos de confiança) por meio de distribuições de referência exatas, como \(t\) e \(F\). Isso é especialmente relevante em amostras pequenas, nas quais, sendo \(\sigma^2\) desconhecido e estimado por \(S^2\), a razão \((b - \beta)/\hat{\sigma}_{b}\) segue exatamente uma distribuição \(t\) de Student somente sob a premissa de normalidade dos erros.
Na estimação de um modelo de regressão linear simples com erro Normal (na forma \(Y = \alpha + \beta X + \varepsilon\)), as premissas preliminarmente assumidas como válidas deverão ser efetivamente verificadas na etapa de diagnóstico do modelo, de modo a permitir que as inferências dele derivadas sejam dotadas de razoável segurança.
Se qualquer uma dessas premissas for violada, uma conclusão científica baseada em resultados advindos desse modelo poderá estar seriamente comprometida. Tais violações não podem ser detectadas pelas estatísticas de resumo usualmente disponíveis logo após a estimação do modelo — como as estatísticas \(t\) e \(F\) dos testes de significância ou o coeficiente de determinação \(R^2\) —, pois essas métricas avaliam ajuste e significância, sendo insensíveis a violações como heterocedasticidade, autocorrelação, não-normalidade dos resíduos ou presença de observações influentes.
Assim, é sobretudo fundamental examinar mais aprofundadamente o modelo de modo a assegurar, com razoável confiança, sua adequação aos dados antes de avançar com seu uso. A esse exame denominamos análise diagnóstica do modelo.
13.6.3 Expressão Matricial Geral de Modelos de Regressão
O modelo de regressão linear múltipla com \(p\) variáveis preditoras:
\[ Y=\beta_{0} + \beta_{1}X_{1} + \dots + \beta_{p}X_{p} + \varepsilon \]
pode ser estimado a partir da definição dos seguintes vetores e matrizes:
\[ Y = \begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_n \end{bmatrix}, \quad X = \begin{bmatrix} 1 & x_{11} & x_{12} & \cdots & x_{1p} \\ 1 & x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_{n1} & x_{n2} & \cdots & x_{np} \end{bmatrix}, \quad \boldsymbol{\beta} = \begin{bmatrix} \beta_0 \\ \beta_1 \\ \beta_2 \\ \vdots \\ \beta_p \end{bmatrix}, \quad \boldsymbol{\varepsilon} = \begin{bmatrix} \varepsilon_1 \\ \varepsilon_2 \\ \vdots \\ \varepsilon_n \end{bmatrix} \]
em que:
- \(Y\) é o vetor \(n \times 1\) das observações da variável resposta
- \(X\) é a matriz \(n \times (p+1)\) de planejamento (ou matriz de delineamento)
- \(\boldsymbol{\beta}\) é o vetor \((p+1) \times 1\) dos parâmetros do modelo
- \(\boldsymbol{\varepsilon}\) é o vetor \(n \times 1\) dos erros aleatórios
- \(n\) é o número de observações
Note que o número de colunas de \(X\) é \((p+1)\), igual ao número de parâmetros a serem estimados, e o número de linhas de \(X\) é \(n\), o tamanho da amostra.
A primeira coluna de \(X\) é um vetor com elementos iguais a 1, correspondente ao intercepto \(\beta_0\).
As demais colunas contêm os valores das \(p\) variáveis preditoras.
O vetor dos erros aleatórios \(\boldsymbol{\varepsilon}\) é composto de variáveis independentes, com distribuição normal \(\varepsilon \sim N(\boldsymbol{0}, \sigma^2 \boldsymbol{I})\).
O vetor esperança dos elementos de \(\boldsymbol{\varepsilon}\) é o vetor nulo de dimensão \(n\).
A matriz de variância-covariância de \(\boldsymbol{\varepsilon}\) possui na diagonal principal as variâncias \(\sigma^{2}\) e, nos demais elementos, as covariâncias \(Cov[\varepsilon_i, \varepsilon_j] = 0\) para \(i \neq j\), com \(i, j = 1, 2, \ldots, n\).
Assim, pode-se assumir o modelo de regressão linear da forma:
\[ \boldsymbol{Y} = \boldsymbol{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon} \]
Para um modelo de regressão linear simples (\(p=1\)), a notação matricial se reduz a:
\[ Y=\beta_{0} + \beta_{1}X + \varepsilon \]
\[ Y = \begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_n \end{bmatrix}, \quad X = \begin{bmatrix} 1 & x_1 \\ 1 & x_2 \\ \vdots & \vdots \\ 1 & x_n \end{bmatrix}, \quad \boldsymbol{\beta} = \begin{bmatrix} \beta_0 \\ \beta_1 \end{bmatrix}, \quad \boldsymbol{\varepsilon} = \begin{bmatrix} \varepsilon_1 \\ \varepsilon_2 \\ \vdots \\ \varepsilon_n \end{bmatrix} \] —
em que a matriz \(\boldsymbol{X}\) possui dimensão \(n \times 2\), com a primeira coluna de 1’s e a segunda coluna contendo os valores \(x_1, x_2, \ldots, x_n\) da única variável preditora.
O estimador de mínimos quadrados é:
\[ \hat{\boldsymbol{\beta}} = (X'X)^{-1}X'Y \]
Os valores ajustados (preditos) podem ser expressos como:
\[ \boldsymbol{\hat{Y}} = \boldsymbol{X}\hat{\boldsymbol{\beta}} = \boldsymbol{X}(\boldsymbol{X}'\boldsymbol{X})^{-1}\boldsymbol{X}'\boldsymbol{Y} = \boldsymbol{HY} \]
em que \(\mathbf{H=X(X'X)^{-1}X'}\) é a chamada matriz \(hat\) (chapéu). Propriedades da matriz chapéu:
- \(\boldsymbol{H}\) é simétrica: \(\boldsymbol{H' = H}\)
- \(\boldsymbol{H}\) é idempotente: \(\boldsymbol{HH = H}\)
X <- as.matrix(cbind(1, x)) # Matriz X
Y <- as.matrix(cbind(y)) # Matriz Y
XtX <- t(X) %*% X # (X'X)
XtY <- t(X) %*% Y # X'Y
INV <- solve(XtX) # Inversa da matriz (X'X)
Betas <- INV %*% XtY # Coeficientes
# Matriz Hat
H <- X %*% INV %*% t(X) # Matriz hat H = X(X'X)^{-1}X'
h_ii <- diag(H) # Elementos da diagonal (alavancagem)
# Valores ajustados e resíduos
Y_hat <- H %*% Y # Valores ajustados
residuos <- Y - Y_hat # Resíduos13.7 Análise Diagnóstica do Modelo de Regressão Linear
13.7.1 Tipos de Resíduos
Resíduos Padronizados são escalonados para que possuam variância aproximadamente unitária, mantendo a esperança nula inerente aos resíduos brutos. Consequentemente \(|d_i| > 3\) indica outliers.
\[ d_i = \frac{e_i}{S} = \frac{e_i}{\sqrt{QMRes}} \]
com \(i = 1, 2, \ldots, n\).
residuos <- modelo$residuals
QMRes <- (summary(modelo)$sigma)^2
respad <- residuos / sqrt(QMRes)
cat(paste0(" ", round(respad, 4), collapse = "\n"))-> -0.1271
-> 1.4763
-> -0.3231
-> -0.794
-> -0.8381
-> 0.606Resíduo na forma de Student (Studentized) – os resíduos padronizados e estudentizados são parecidos, mas em algumas situações os resíduos estudentizados são mais sensíveis para detectar outliers, dados por:
\[ r_i = \frac{e_i}{\sqrt{S^2(1-h_{ii})}} \]
com \(i = 1, 2, \ldots, n\) e, caso para \(|r_i| > 3\), há uma indicação de se tratarem de outliers.
residuos <- modelo$residuals
QMRes <- (summary(modelo)$sigma)^2
h <- hatvalues(modelo)
respad <- residuos / sqrt(QMRes * (1 - h))
cat(paste0(" ", round(respad, 4), collapse = "\n"))-> -0.2366
-> 1.625
-> -0.3592
-> -0.8764
-> -0.9773
-> 0.839813.7.2 Linearidade na relação entre a variável preditora \(X\) e a variável resposta \(Y\):
A violação da linearidade é extremamente grave pois um modelo ajustado a dados não lineares leva a previsões equivocadas não somente para valores situados além das fronteiras amostrais (como se usualmente observa) mas também para valores próximos ao seu centro.
Uma técnica para se verificar a linearidade da relação é através de dois gráficos:
- valores observados versus valores estimados; ou/e,
- resíduos obtidos versus valores estimados.
# Dados do Exemplo
dados <- data.frame(
Anuncios = c(74, 45, 48, 36, 27, 16),
Carros_vendidos = c(139, 108, 98, 76, 62, 57)
)
# Ajuste do modelo
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)
# Extração de elementos do modelo
residuos <- residuals(modelo)
n <- length(residuos) # ou length(carros_vendidos)
valores_ajustados <- fitted(modelo)
residuos_padronizados <- rstandard(modelo)
residuos_studentizados <- rstudent(modelo)plot(valores_ajustados, dados$Carros_vendidos,
xlab = "Valores estimados",
ylab = "Valores observados",
main = "Valores observados vs estimados",
pch = 19, col = "blue")
abline(a = 0, b = 1, col = "red", lwd = 2)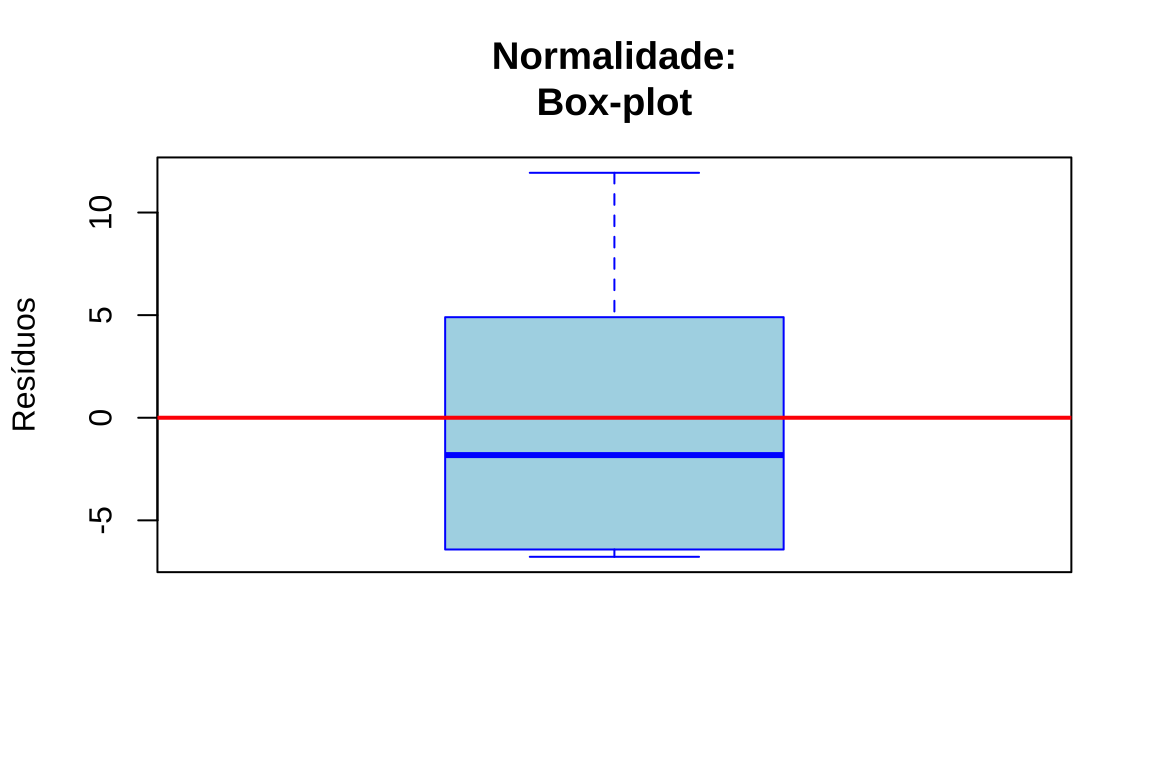
plot(valores_ajustados, residuos,
xlab = "Valores estimados",
ylab = "Resíduos",
main = "Resíduos vs valores estimados",
pch = 19, col = "blue")
abline(h = 0, col = "red", lwd = 2)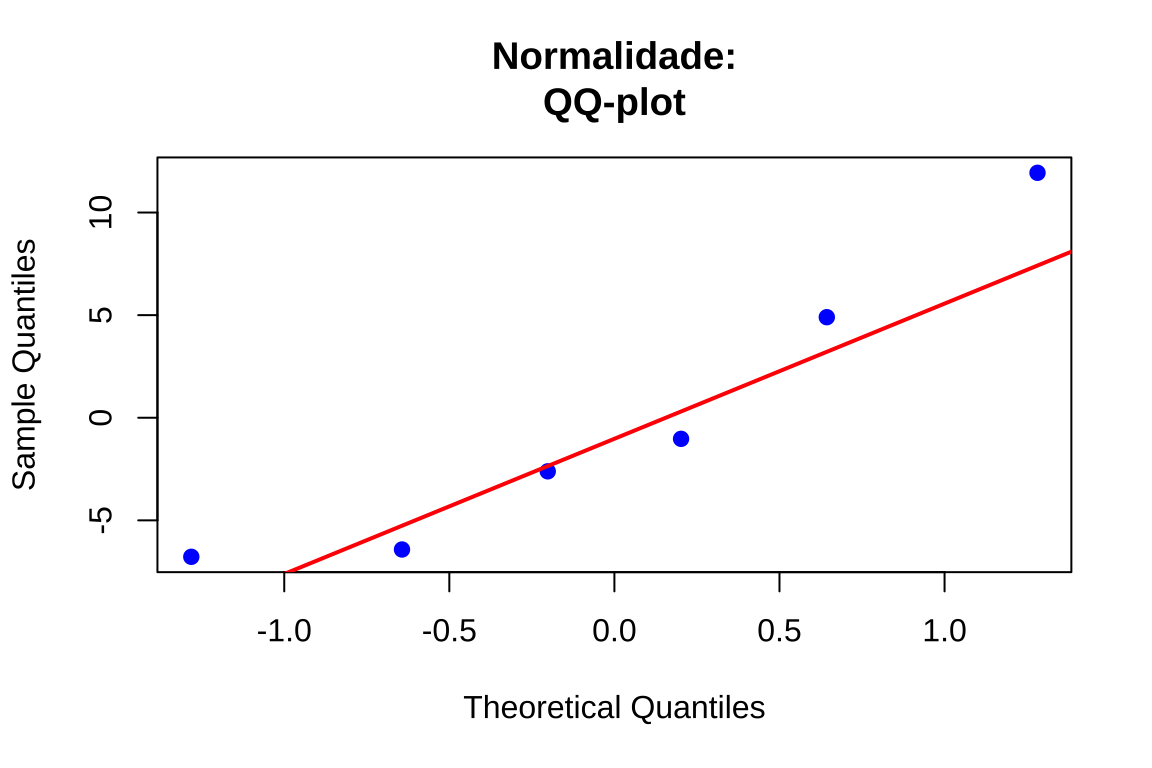
Os padrões desejados nos gráficos acima devem assemelhar-se a:
- pontos dispersos de modo aproximadamente simétrico em torno de uma linha diagonal; e,
- pontos dispersos de modo aproximadamente simétrico em torno de uma linha horizontal, com uma variância aproximadamente homogênea.
Relações não lineares devem ser tratadas por meio da aplicação de uma transformação não linear adequada ao padrão da relação na variável resposta ou no variável preditora.
Para dados estritamente positivos com uma relação não linear a transformação com a função logaritmo pode ser uma opção.
Se uma a transformação com o uso da função logaritmo é aplicada apenas à variável resposta isso equivalente a assumir que ela cresce (ou decai) exponencialmente como uma função da variável preditora.
Outra possibilidade a considerar é adicionar outra variável preditora na forma de uma função não linear como, por exemplo, nos padrões de dispersão que mostrem uma curva parabólica onde pode fazer sentido regredir \(Y\) em função de \(X\) e \(X^{2}\).
Uma relação não linear observada pode decorrer da omissão de outra(s) variável(is) importante(s) que explica(m) ou corrige(m) o padrão não linear quando então modelos de regressão linear múltipla devem ser estudados.
13.7.3 Homogeneidade da variância dos resíduos \(\varepsilon_i\) (homocedasticidade):
A violação da homogeneidade de variância dos resíduos (heterocedasticidade) resulta numa estimação imprecisa do verdadeiro desvio padrão dos erros das estimativas e acarreta em intervalos de confiança irreais: são mais amplos ou mais estreitos do que deveriam ser, e resultam em elevada imprecisão nas inferências feitas com estatísticas baseadas na variância (\(t\), \(F\)).
Com variância constante (homocedasticidade) temos que \(Var(\varepsilon|X_{i})=\sigma^{2}\); todavia o que se observa em muitas situações é que a variância está relacionada de algum modo funcional com a variável preditora (\(\sigma^{2}=\mathcal{f}(X)\)) e, assim:
\[ \begin{aligned} Var(\varepsilon_{i}|X_{i})=\sigma^{2}_{i} \\ E(\varepsilon_{i}^{2})=\sigma^{2}_{i} \end{aligned} \]
Na presença de heterocedasticidade nos resíduos, os estimadores de mínimos quadrados continuam sendo não viesados e consistentes, mas perdem eficiência. Equivale a dizer que haverá um outro estimador para os parâmetros do modelo que terá uma variância menor mantendo propriedade de não viés:
\[ \begin{aligned} Var(b^{*}) < Var(b) \end{aligned} \]
Uma técnica para se verificar a homocedasticidade dos resíduos é através dos gráficos:
- resíduos versus valores estimados; ou,
- resíduos versus a variável preditora
# Gráfico 1: Resíduos vs valores ajustados
plot(valores_ajustados, residuos,
xlab = "Valores estimados",
ylab = "Resíduos",
main = "Homocedasticidade:\nResíduos vs valores estimados",
pch = 19, col = "blue")
abline(h = 0, col = "red", lwd = 2)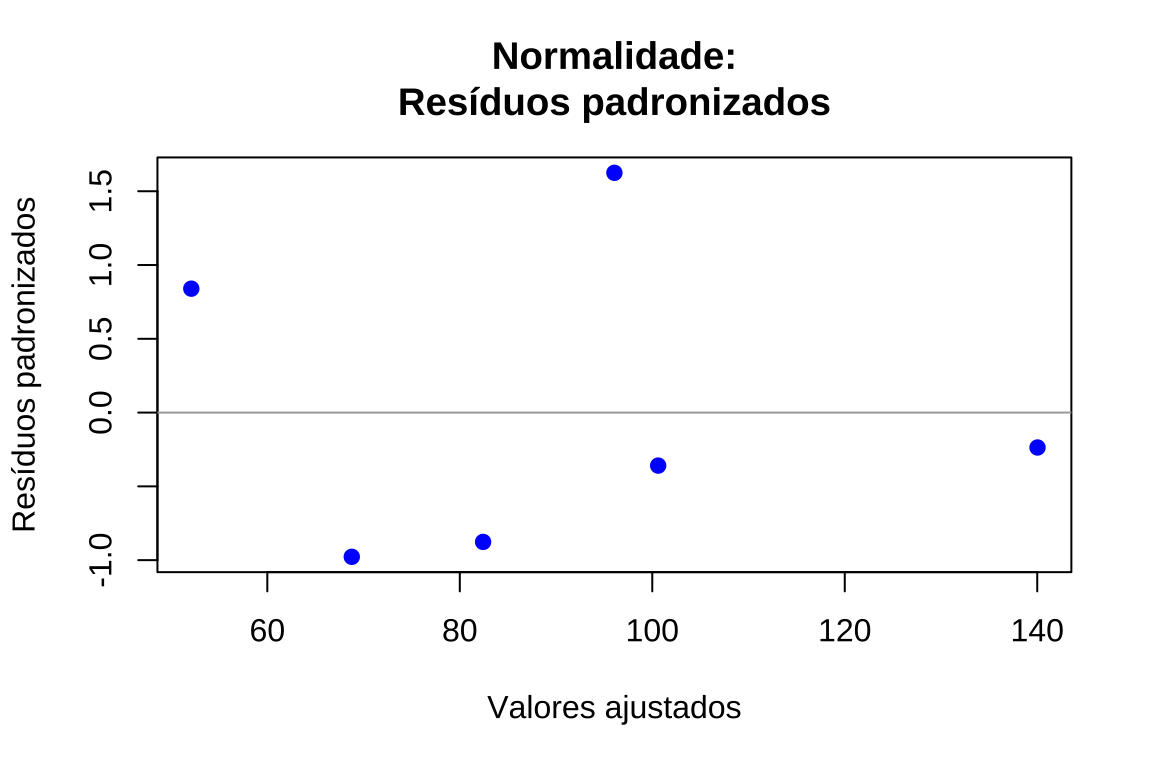
O padrão desejado no gráfico acima deve assemelhar-se a:
- pontos dispersos de modo aproximadamente simétrico em torno de um eixo horizontal e que não exibam, sistematicamente, nenhum padrão de crescimento ou decaimento na amplitude visual de sua dispersão como nas imagens acima.
Gráficos dos valores absolutos dos resíduos (ou do quadrado dos resíduos pois os sinais dos resíduos não são significativos para o propósito desse exame) contra a variável preditora \(X\) ou em relação aos valores ajustados também são úteis para o diagnóstico da heterocedasticidade da variância dos resíduos.
# Gráfico 2: Resíduos vs variável preditora
plot(anuncios, residuos,
xlab = "Variável preditra (Anúncios)",
ylab = "Resíduos",
main = "Homocedasticidade:\nResíduos vs variável preditora X",
pch = 19, col = "blue")
abline(h = 0, col = "red", lwd = 2)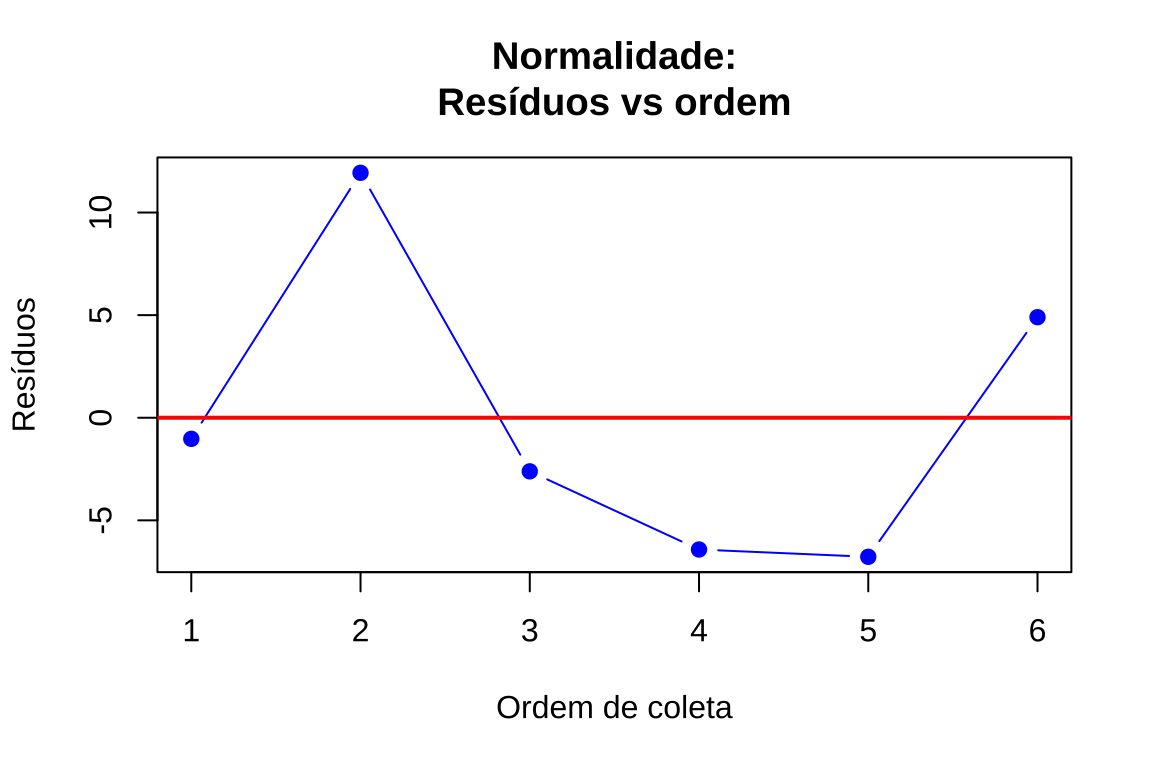
# Gráfico 3: Resíduos absolutos vs valores ajustados
plot(valores_ajustados, abs(residuos),
xlab = "Valores estimados",
ylab = "|Resíduos|",
main = "Homocedasticidade:\n|Resíduos| vs valores estimados",
pch = 19, col = "blue")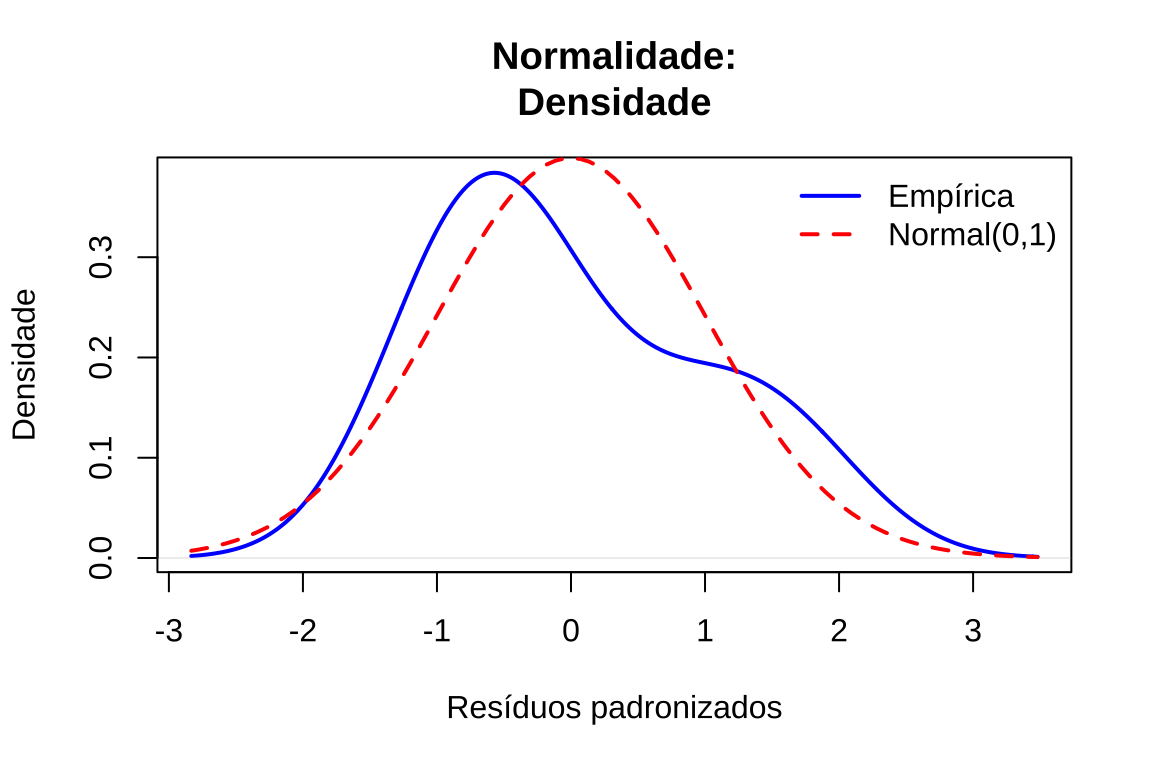
Esses gráficos são recomendados quando não há muitas observações no conjunto de dados pois a plotagem dos resíduos absolutos ou seus quadrados coloca as informações sobre a alteração das suas magnitudes acima da linha horizontal do zero o que facilita a inspeção visual de possíveis alterações de sua magnitude em relação a outra variável adotada no gráfico.
Testes formais de homocedasticidade
Embora a análise gráfica seja fundamental, testes de hipóteses formais complementam o diagnóstico:
- teste de Breusch-Pagan
- teste de Park
\[ \begin{cases} H_{0}: Var(\varepsilon|X_{i}) = \sigma^{2} \text{ ou seja, constante para todo } i \\ H_{1}: Var(\varepsilon|X_{i}) = \sigma^{2}_{i} \text{, varia com } i \end{cases} \]
# Teste de Breusch-Pagan
bp_test <- bptest(modelo)
cat("\nTeste de Breusch-Pagan para heterocedasticidade:\n")
print(bp_test)
if (bp_test$p.value > 0.05) {
cat("\nConclusão: p-valor =", round(bp_test$p.value, 4), "> 0,05. Não se rejeita H0: a variância é homogênea (homoscedasticidade).\n")
} else {
cat("\nConclusão: p-valor =", round(bp_test$p.value, 4), "< 0,05. Rejeita-se H0: há evidência de heterocedasticidade.\n")
}->
-> Teste de Breusch-Pagan para heterocedasticidade:
->
-> studentized Breusch-Pagan test
->
-> data: modelo
-> BP = 0.14, df = 1, p-value = 0.7
->
->
-> Conclusão: p-valor = 0.7055 > 0,05. Não se rejeita H0: a variância é homogênea (homoscedasticidade).# Teste de Park
# 1. Modelo original
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)
# 2. Resíduos ao quadrado
residuos_sq <- residuals(modelo)^2
# 3. Logaritmos
ln_residuos_sq <- log(residuos_sq)
ln_anuncios <- log(dados$Anuncios)
# 4. Regressão auxiliar (Teste de Park)
park_model <- lm(ln_residuos_sq ~ ln_anuncios)->
-> Call:
-> lm(formula = ln_residuos_sq ~ ln_anuncios)
->
-> Residuals:
-> 1 2 3 4 5 6
-> -1.696 2.359 -0.570 0.738 0.355 -1.186
->
-> Coefficients:
-> Estimate Std. Error t value Pr(>|t|)
-> (Intercept) 9.10 5.08 1.79 0.15
-> ln_anuncios -1.71 1.40 -1.22 0.29
->
-> Residual standard error: 1.65 on 4 degrees of freedom
-> Multiple R-squared: 0.272, Adjusted R-squared: 0.0896
-> F-statistic: 1.49 on 1 and 4 DF, p-value: 0.289park_summary <- summary(park_model)
p_valor_park <- park_summary$coefficients[2, 4]
if (p_valor_park > 0.05) {
cat("\nConclusão: p-valor =", round(p_valor_park, 4), "> 0,05. Não se rejeita H0: a variância é homogênea (homoscedasticidade).\n")
} else {
cat("\nConclusão: p-valor =", round(p_valor_park, 4), "< 0,05. Rejeita-se H0: há evidência de heterocedasticidade.\n")
}->
-> Conclusão: p-valor = 0.289 > 0,05. Não se rejeita H0: a variância é homogênea (homoscedasticidade).A heterocedasticidade pode ser consequência de uma violação significativa das premissas de linearidade e/ou independência, caso em que todas essas violações podem ser conjuntamente corrigidas com a aplicação de uma transformação de potência na variável dependente que terá como objetivos:
- linearizar o ajuste tanto quanto possível; e/ou,
- estabilizar a variância dos resíduos.
Algum cuidado e discernimento é requerido pois esses dois objetivos podem conflitar entre si. Geralmente opta-se em estabilizar a variância dos resíduos primeiramente para, só então analisar a linearização das relações.
As transformações sugeridas pela família Box-Cox (1964) em função do valor que maximiza a verossimilhança perfilada são:
- se \(\lambda\)=-2 \(\rightarrow\) \(\frac{1}{Y^{2}}\)
- se \(\lambda\)=-1 \(\rightarrow\) \(\frac{1}{Y}\)
- se \(\lambda\)=-0,5 \(\rightarrow\) \(\frac{1}{\sqrt{Y}}\)
- se \(\lambda\)=0 \(\rightarrow\) log(Y)
- se \(\lambda\)=0,50 \(\rightarrow\) \(\sqrt{Y}\)
- se \(\lambda\)=1 \(\rightarrow\) Y
- se \(\lambda\)=2 \(\rightarrow\) \(Y^{2}\)
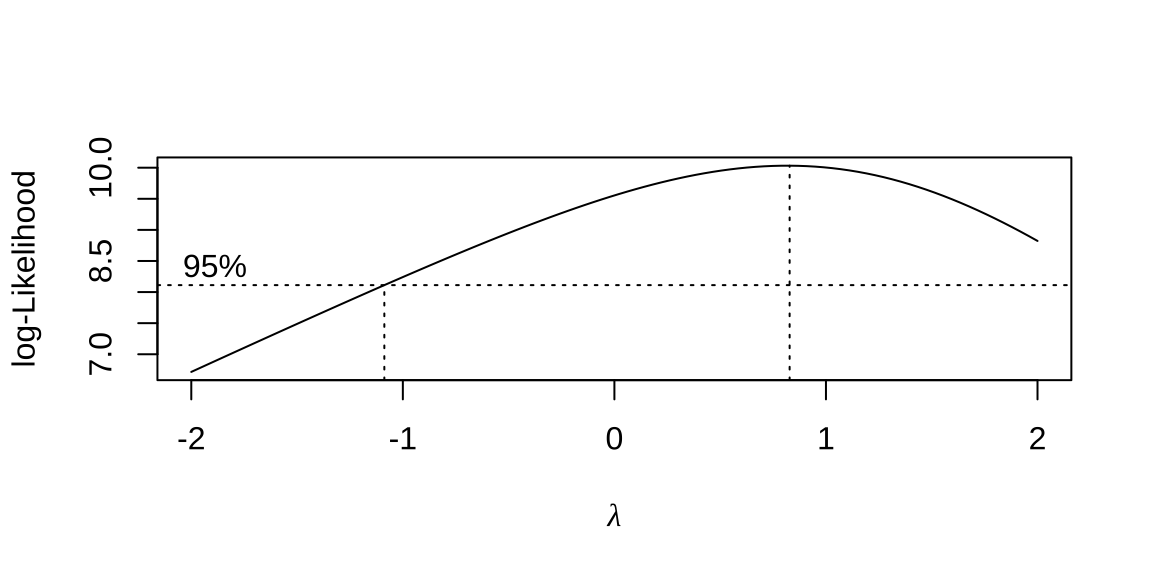
->
-> Lambda ótimo da transformação Box-Cox: 0.828313.7.4 Independência
Quando as observações da amostra são independentes o que se espera é que seus resíduos apresentem-se aleatoriamente dispersos em torno da linha horizontal (zero) quando dispostos na sequência em que foram coletadas.
O que se pretende aqui é verificar se há correlação serial entre os resíduos.
A autocorrelação pode ser definida como a correlação entre as observações em uma série ordenada no tempo ou no espaço quando então os resíduos de duas observações guardam correlação diferente de zero entre si:
\[ \begin{aligned} cov(e_{i}, e_{j}|x_{i}, x_{j}) \neq 0 \\ i \neq j \end{aligned} \]
A correlação serial pode decorrer:
- inércia: quando os efeitos na alteração da variável \(X\) demoram a se manifestar na variável \(Y\) (muito comum em dados econômicos);
- forma funcional do modelo incorreta;
- variáveis importantes foram omitidas.
Uma técnica para se verificar a ausência de correlação serial (independência dos resíduos \(\hat{\varepsilon}\)) é através do gráfico dos resíduos versus o tempo ou ordem no qual as observações foram realizadas.
# Dados do Exemplo
dados <- data.frame(
Anuncios = c(74, 45, 48, 36, 27, 16),
Carros_vendidos = c(139, 108, 98, 76, 62, 57)
)
# Ajuste do modelo
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)
# Extração de elementos do modelo
residuos <- residuals(modelo)
n <- length(residuos) # ou length(carros_vendidos)
par(mfrow = c(1, 2))# Gráfico: Resíduos vs ordem de coleta
plot(1:n, residuos,
xlab = "Ordem de coleta",
ylab = "Resíduos",
main = "Independência:\nResíduos vs ordem",
pch = 19, col = "blue", type = "b")
abline(h = 0, col = "red", lwd = 2)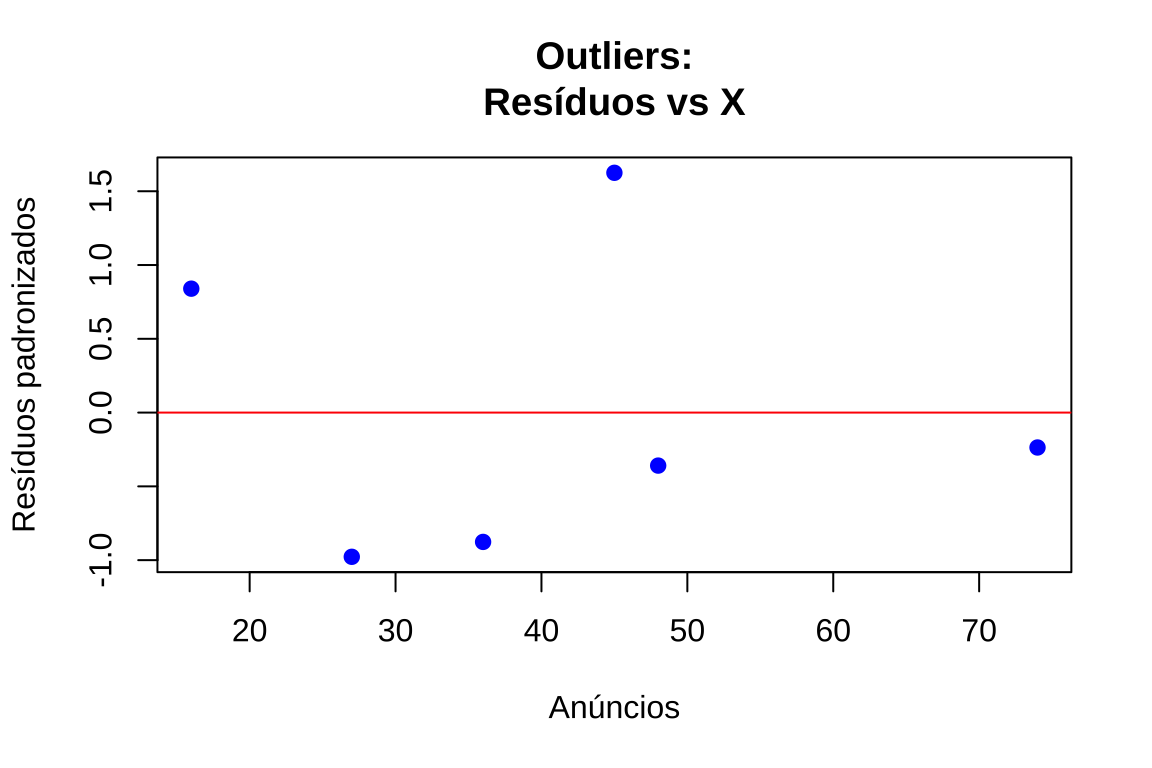
Testes formais de independência
A independência dos resíduos pode ser verificada formalmente pelo teste de Durbin-Watson, cujas hipóteses são:
\[ \begin{cases} H_{0}: \rho = 0 \text{ (ausência de autocorrelação serial)} \\ H_{1}: \rho \neq 0 \text{ (presença de autocorrelação serial)} \end{cases} \]
cuja estatística é dada por:
\[ d = \frac{\sum_{i=2}^{n}(e_i - e_{i-1})^2}{\sum_{i=1}^{n}e_i^2} \]
com \(d \in [0, 4]\), sendo que valores próximos de 2 indicam ausência de autocorrelação, valores próximos de 0 indicam autocorrelação positiva e valores próximos de 4 indicam autocorrelação negativa.
# Teste de Durbin-Watson
dw_test <- dwtest(modelo)
cat("Teste de Durbin-Watson para autocorrelação serial:\n")
print(dw_test)
if (dw_test$p.value > 0.05) {
cat("\nConclusão: p-valor =", round(dw_test$p.value, 4), "> 0,05. Não se rejeita H0: ausência de autocorrelação serial.\n")
} else {
cat("\nConclusão: p-valor =", round(dw_test$p.value, 4), "< 0,05. Rejeita-se H0: há evidência de autocorrelação serial.\n")
}-> Teste de Durbin-Watson para autocorrelação serial:
->
-> Durbin-Watson test
->
-> data: modelo
-> DW = 2, p-value = 0.3
-> alternative hypothesis: true autocorrelation is greater than 0
->
->
-> Conclusão: p-valor = 0.3116 > 0,05. Não se rejeita H0: ausência de autocorrelação serial.13.7.5 Normalidade dos Resíduos
A normalidade dos resíduos é essencial para a validade dos testes de hipóteses e intervalos de confiança em regressão. Embora pequenos afastamentos da normalidade não comprometam seriamente as inferências, desvios substanciais podem invalidar conclusões estatísticas, especialmente em amostras pequenas.
A análise gráfica constitui o primeiro passo para avaliar a normalidade dos resíduos. Os principais métodos incluem:
Comparação com frequências esperadas: Sob normalidade, espera-se que 68% dos resíduos padronizados estejam em \(\pm 1\) desvio padrão, 90% em \(\pm 1{,}65\) desvios padrão e 95% em \(\pm 1{,}96\) desvios padrão
Histograma: Permite visualizar a forma da distribuição e compará-la com a curva normal teórica
Gráfico de caixa: Identifica assimetria e presença de valores extremos
QQ-plot (gráfico quantil-quantil): Compara os quantis amostrais dos resíduos padronizados com os quantis teóricos da distribuição Normal padrão. Se os resíduos provêm de uma distribuição Normal, os pontos devem alinhar-se aproximadamente sobre uma reta
Gráfico com envoltória simulada: Proposto por Ripley (1977), fornece bandas de confiança para avaliar desvios da normalidade
# Gráfico 1: Histograma
hist(residuos,
main = "Normalidade:\nHistograma", xlab = "Resíduos", ylab = "Densidade", col = "lightblue", border = "blue", probability = TRUE)
curve(dnorm(x, mean = mean(residuos), sd = sd(residuos)), add = TRUE, col = "red", lwd = 2)
legend("topright", legend = "Normal teórica", col = "red", lwd = 2, bty = "n")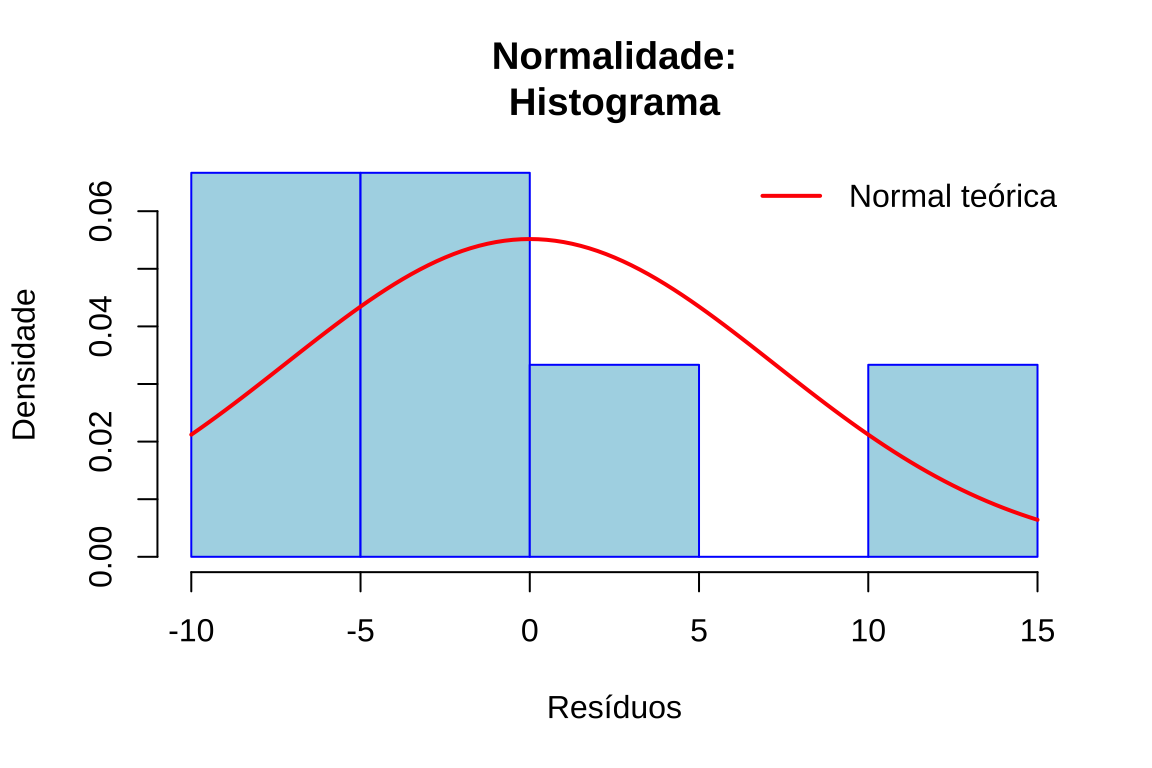
# Gráfico 2: Boxplot
boxplot(residuos, main = "Normalidade:\nBox-plot", ylab = "Resíduos", col = "lightblue", border = "blue")
abline(h = 0, col = "red", lwd = 2)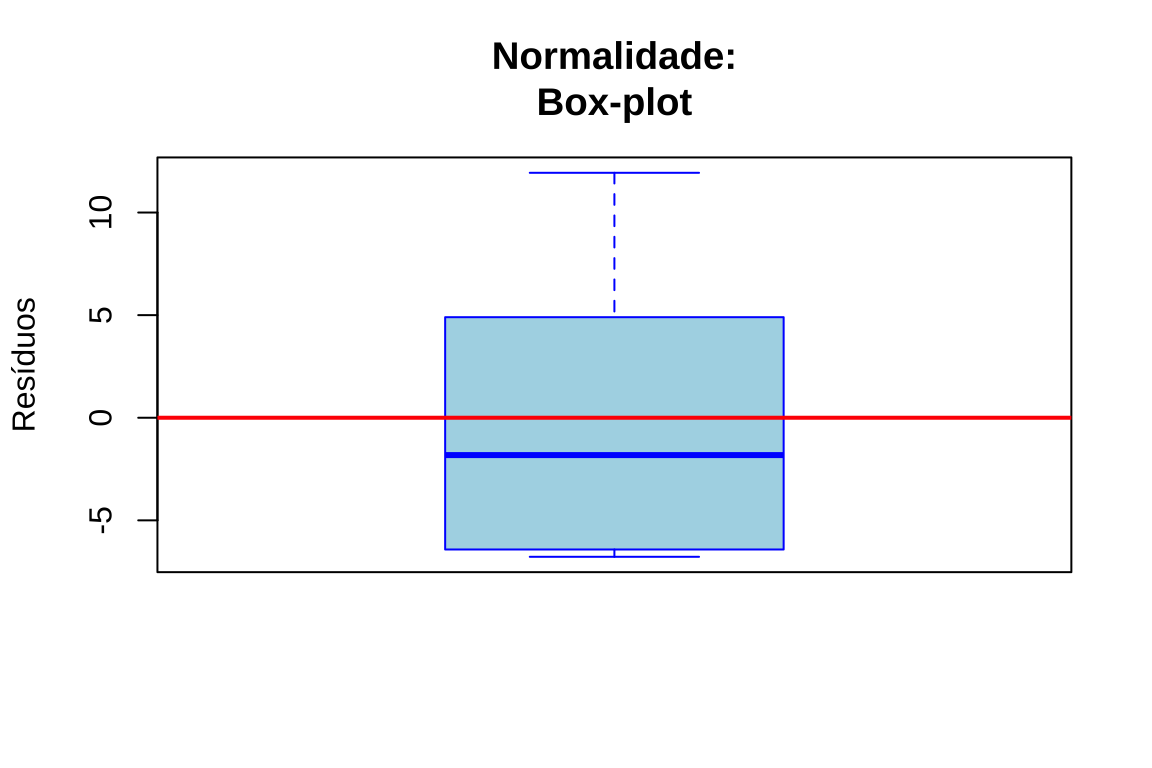
# Gráfico 3: QQ-plot
qqnorm(residuos, main = "Normalidade:\nQQ-plot", pch = 19, col = "blue")
qqline(residuos, col = "red", lwd = 2)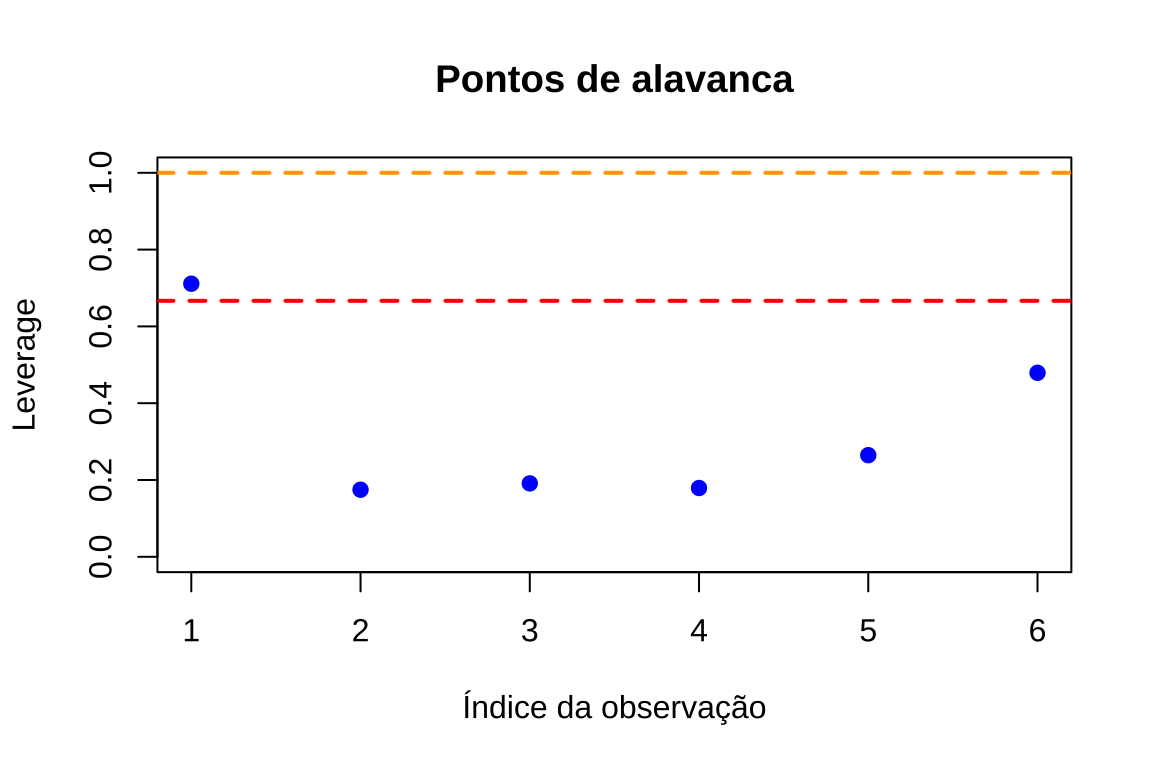
Interpretação do QQ-plot
O gráfico quantil-quantil compara os quantis amostrais ordenados dos resíduos padronizados com os quantis teóricos da distribuição \(N(0,1)\). Sob normalidade, os pontos devem dispor-se aproximadamente sobre uma linha reta. Padrões sistemáticos de afastamento indicam violações específicas:
Padrão “S”: Distribuição com caudas curtas (platicúrtica), indicando concentração excessiva de valores próximos à média.
Padrão “S invertido”: Distribuição com caudas longas (leptocúrtica), indicando presença de valores extremos além do esperado sob normalidade.
Padrão “J”: Assimetria positiva (cauda direita mais longa).
Padrão “J invertido”: Assimetria negativa (cauda esquerda mais longa).
# Gráfico 4: Resíduos padronizados vs valores ajustados
plot(valores_ajustados, residuos_padronizados, xlab = "Valores ajustados",ylab = "Resíduos padronizados", main = "Normalidade:\nResíduos padronizados", pch = 19, col = "blue")
abline(h = c(-1.96, 0, 1.96), col = c("red", "darkgray", "red"), lty = c(2, 1, 2), lwd = c(2, 1, 2))
text(x = max(valores_ajustados) * 0.95, y = 2.2, labels = "95%", col = "red", cex = 0.8)
text(x = max(valores_ajustados) * 0.95, y = -2.2, labels = "95%", col = "red", cex = 0.8)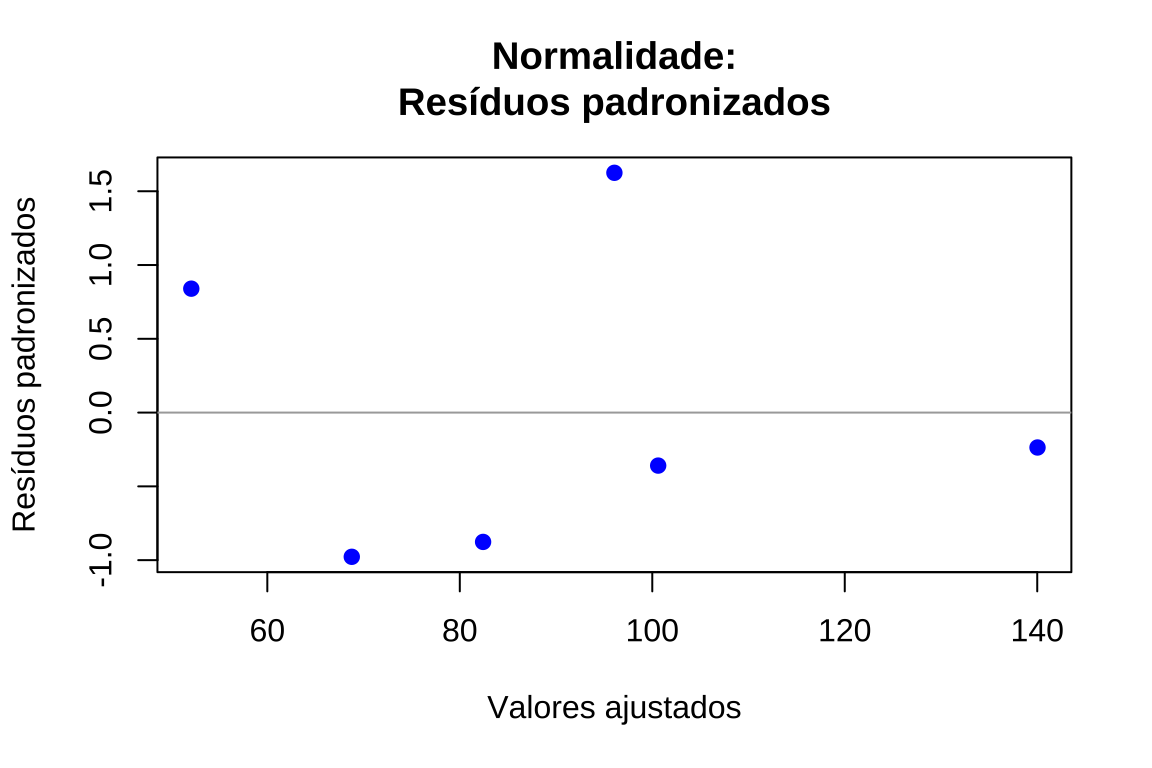
# Gráfico 5: Resíduos vs ordem de coleta (detecção de padrões)
plot(1:length(residuos), residuos, xlab = "Ordem de coleta", ylab = "Resíduos", main = "Normalidade:\nResíduos vs ordem", pch = 19, col = "blue", type = "b")
abline(h = 0, col = "red", lwd = 2)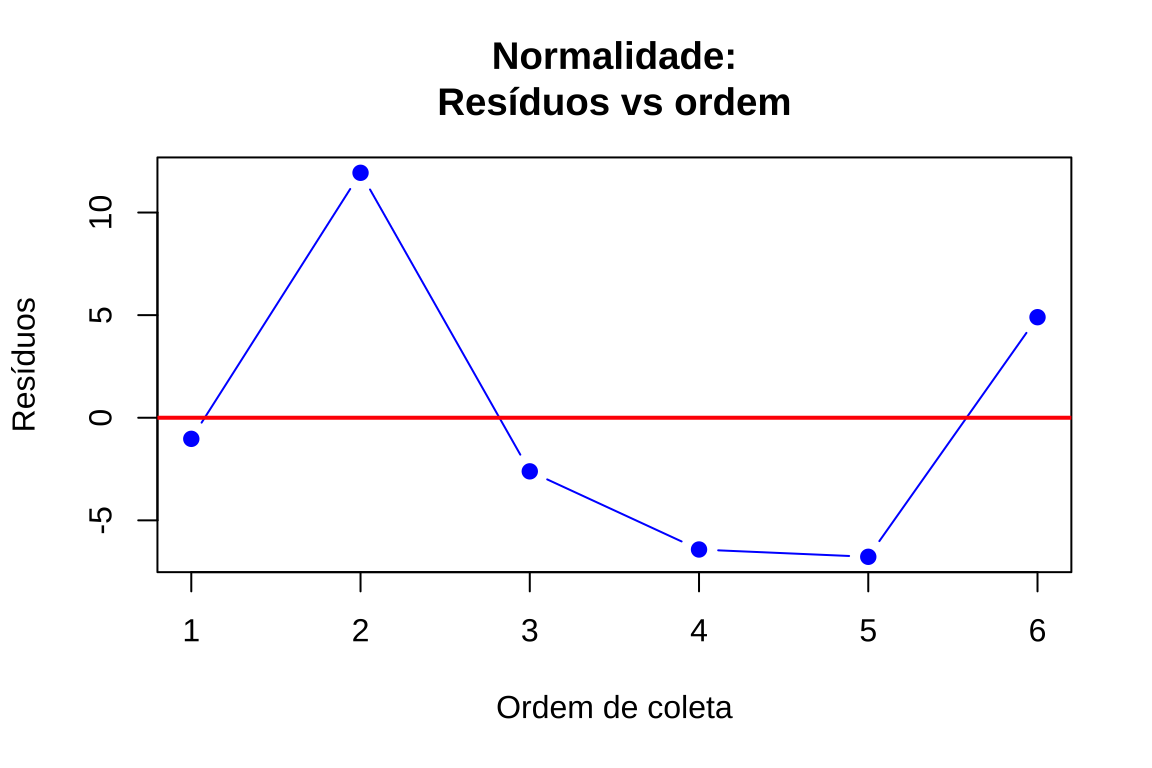
# Gráfico 6: Densidade empírica vs teórica
plot(density(residuos_padronizados), main = "Normalidade:\nDensidade", xlab = "Resíduos padronizados", ylab = "Densidade", lwd = 2, col = "blue")
curve(dnorm(x, 0, 1), add = TRUE, col = "red", lwd = 2, lty = 2)
legend("topright", legend = c("Empírica", "Normal(0,1)"), col = c("blue", "red"), lwd = 2, lty = c(1, 2), bty = "n")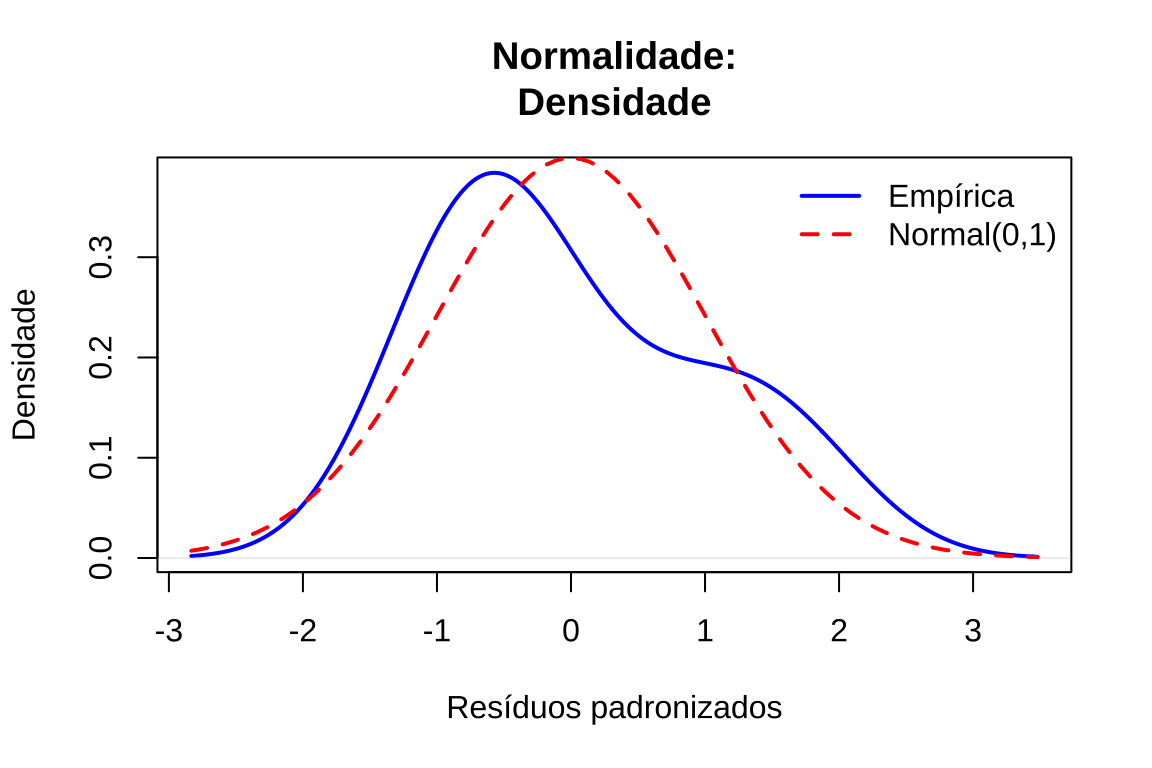
# Verificação das frequências esperadas
prop_1sd <- mean(abs(residuos_padronizados) <= 1)
prop_1.65sd <- mean(abs(residuos_padronizados) <= 1.65)
prop_1.96sd <- mean(abs(residuos_padronizados) <= 1.96)
cat("\nFrequências observadas vs esperadas (sob normalidade):\n")
cat("Dentro de ±1,00 DP:", sprintf("%5.1f%%", prop_1sd * 100),
"(esperado: 68,0%)\n")
cat("Dentro de ±1,65 DP:", sprintf("%5.1f%%", prop_1.65sd * 100),
"(esperado: 90,0%)\n")
cat("Dentro de ±1,96 DP:", sprintf("%5.1f%%", prop_1.96sd * 100),
"(esperado: 95,0%)\n")->
-> Frequências observadas vs esperadas (sob normalidade):
-> Dentro de ±1,00 DP: 83.3% (esperado: 68,0%)
-> Dentro de ±1,65 DP: 100.0% (esperado: 90,0%)
-> Dentro de ±1,96 DP: 100.0% (esperado: 95,0%)Considerações sobre diagnóstico de normalidade
A avaliação da normalidade dos resíduos apresenta desafios práticos:
Tamanho amostral: Em amostras pequenas (\(n < 30\)), a variação aleatória dificulta a distinção entre flutuações amostrais e desvios reais da normalidade. Para amostras muito grandes (\(n \gtrsim 300\), as inferências tornam-se aproximadamente válidas mesmo com desvios moderados da normalidade devido à normalidade assintótica dos estimadores dos coeficientes de regressão.
Outros desvios: Inadequação da forma funcional ou heterocedasticidade podem distorcer a distribuição dos resíduos, confundindo o diagnóstico de normalidade.
Tolerância a desvios: Pequenos afastamentos da normalidade são aceitáveis e não comprometem seriamente as inferências, especialmente em amostras moderadas a grandes.
Testes formais de normalidade
Embora a análise gráfica seja fundamental, testes de hipóteses formais complementam o diagnóstico:
\[ \begin{cases} H_0: \text{os resíduos seguem distribuição Normal} \\ H_1: \text{os resíduos não seguem distribuição Normal} \end{cases} \]
- Shapiro-Wilk (Shapiro e Wilk, 1965): Recomendado para amostras pequenas a moderadas (\(n \lesssim 200\))
- Kolmogorov-Smirnov (Kolmogorov, 1933; Smirnov, 1948): Baseado na máxima diferença entre funções de distribuição empírica e teórica
- Lilliefors (Lilliefors, 1967): Modificação do teste de Kolmogorov-Smirnov quando parâmetros são estimados
- Anderson-Darling (Anderson e Darling, 1954): Dá maior peso às caudas da distribuição
- Jarque-Bera (Jarque e Bera, 1987): Baseado em assimetria e curtose amostrais
- Teste \(K^2\) de D’Agostino (D’Agostino, 1970)
- Teste de Cramér-von Mises (Cramér, 1946; von Mises, 1928)
- Teste de Shapiro-Francia (Shapiro e Francia, 1972)
- Teste \(\chi^2\) de Pearson (Pearson, 1900)
- Teste de correlação linear entre resíduos ordenados e quantis teóricos
->
-> Testes formais de normalidade:
->
-> Teste de Shapiro-Wilk:
-> Estatística W = 0.9009
-> p-valor = 0.3795
->
-> Interpretação: p-valor > 0,05 indica não rejeição de H₀ (normalidade)-> Teste de Lilliefors (Kolmogorov-Smirnov):
-> Estatística D = 0.2232
-> p-valor = 0.4584
->
-> Interpretação: p-valor > 0,05 indica não rejeição de H₀ (normalidade)
->
-> Teste de Anderson-Darling: não aplicável (requer n > 7)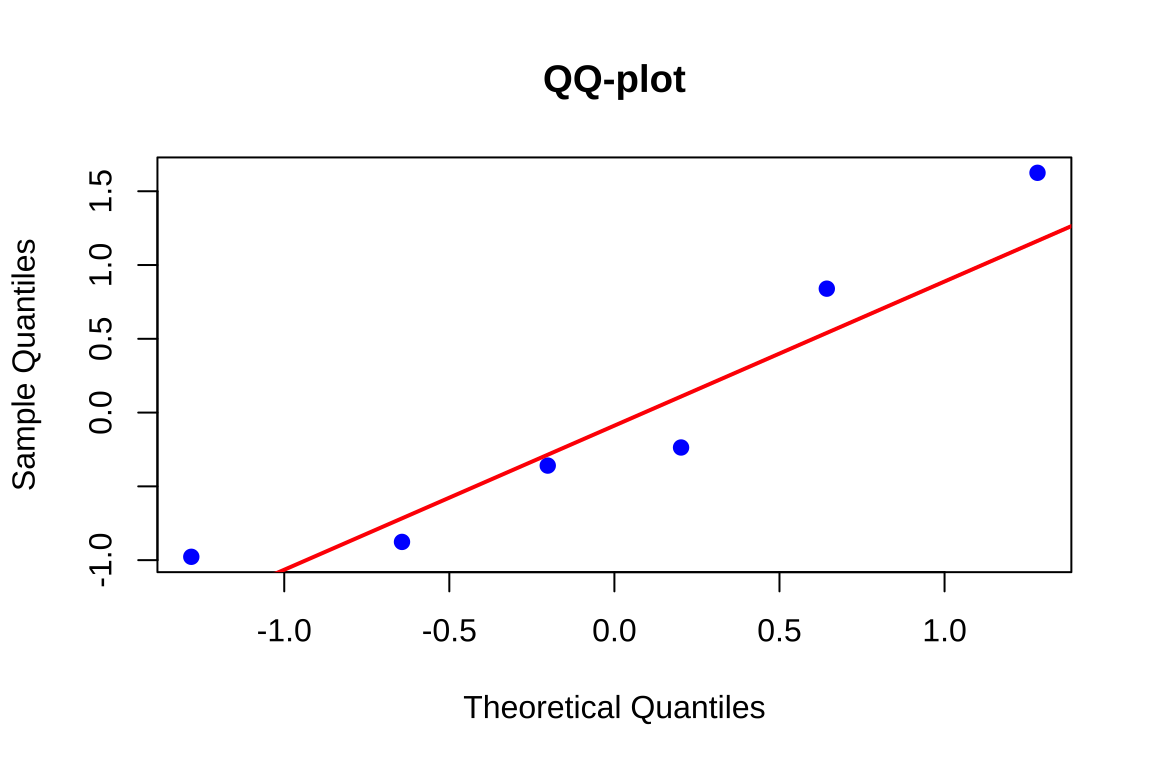
-> O QQ-plot compara os quantis amostrais dos resíduos padronizados
-> com os quantis teóricos de N(0,1).
-> Sob normalidade, os pontos devem alinhar-se sobre a reta.
-> Afastamentos sistemáticos indicam violações.13.7.6 Observações Inconsistentes
Outliers são observações que se afastam substancialmente do padrão geral dos dados. Contudo, nem toda observação distante do centroide dos dados necessariamente é uma observação problemática: é fundamental distinguir observações naturalmente extremas de erros que comprometam a validade do modelo.
Observações extremas podem originar-se de:
- Erros não amostrais: falhas na coleta, registro ou processamento dos dados (instrumentos descalibrados, erros de transcrição, observadores diferentes, equipamentos diversos)
- Variabilidade natural do fenômeno: observações legítimas que refletem eventos raros, mas genuínos, do processo estudado
A distinção entre essas situações é crucial: enquanto erros não amostrais devem ser corrigidos ou excluídos quando identificados, observações extremas legítimas fornecem informação valiosa sobre a variabilidade do fenômeno e não devem ser descartadas arbitrariamente.
Embora a identificação de observações inconsistentes deva iniciar na análise exploratória dos dados (EDA), muitos erros só se tornam evidentes após o ajuste do modelo, quando a análise dos resíduos revela padrões anômalos.
Outliers devem ser removidos da análise apenas quando há evidência objetiva de que representam erros de coleta, registro, cálculo ou circunstâncias análogas.
Observações extremas que refletem variabilidade genuína do fenômeno não devem ser descartadas, mesmo que exerçam influência no modelo, pois sua remoção resultaria em perda de informação relevante sobre o processo estudado.
Uma técnica para se verificar a presença de observações inconsistentes é através dos seguintes gráficos:
- Gráfico de caixa ( box-plot) dos resíduos padronizados: identifica observações afastadas da distribuição central por meio de análise univariada
- Resíduos padronizados versus valores ajustados: permite identificar simultaneamente outliers (\(|d_i| > 3\)) e avaliar homocedasticidade
- Resíduos padronizados versus variável preditora: complementa a análise anterior, revelando se outliers concentram-se em regiões específicas de \(X\)
- Resíduos estudentizados versus valores ajustados: mais sensíveis para detectar pontos de alta alavancagem e influência (\(∣r_i∣>3\))
# Dados do Exemplo
dados <- data.frame(
Anuncios = c(74, 45, 48, 36, 27, 16),
Carros_vendidos = c(139, 108, 98, 76, 62, 57)
)
# Ajuste do modelo
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)
# Extração de elementos do modelo
residuos <- residuals(modelo)
n <- length(residuos) # ou length(carros_vendidos)
valores_ajustados <- fitted(modelo)
residuos_padronizados <- rstandard(modelo)
residuos_studentizados <- rstudent(modelo)# Gráfico 1: Box-plot dos resíduos padronizados
boxplot(residuos_padronizados, main = "Outliers:\nBox-plot dos resíduos", ylab = "Resíduos padronizados", col = "lightblue",
border = "blue", outcol = "red", outpch = 19)
abline(h = c(-3, 3), col = "red", lty = 2, lwd = 1)
abline(h = 0, col = "darkgray", lwd = 1)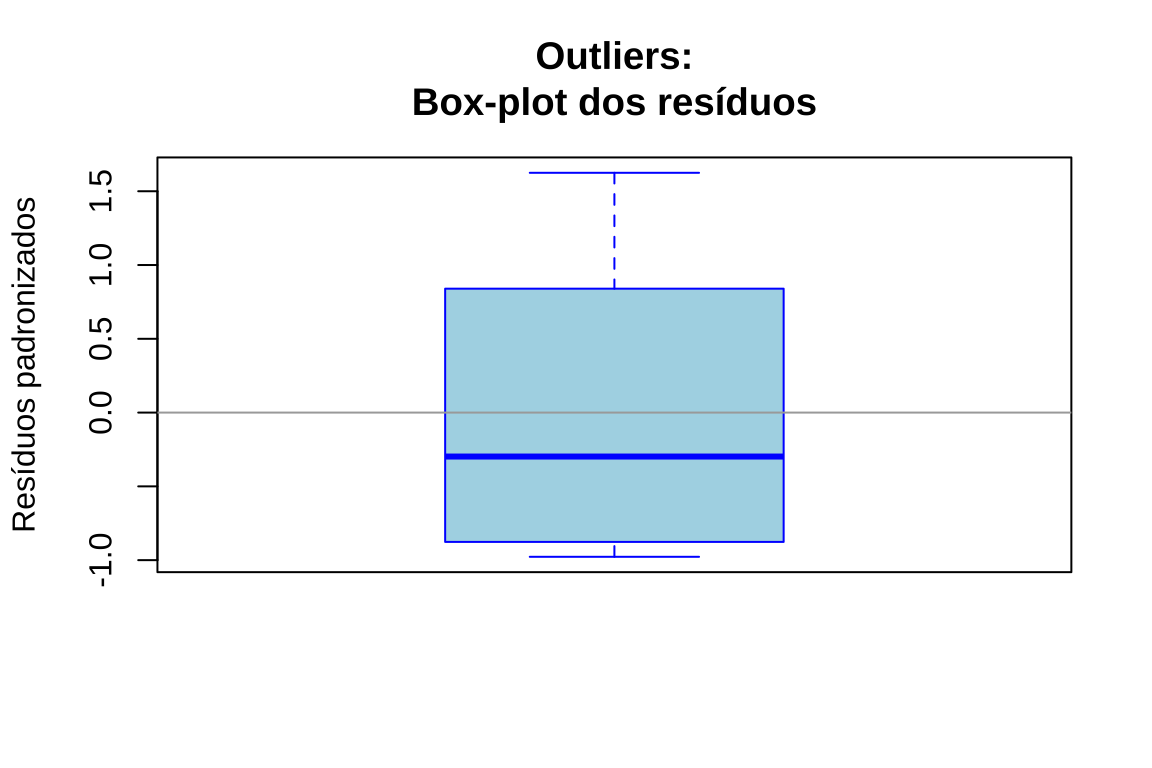
# Gráfico 2: Resíduos padronizados vs valores ajustados
plot(valores_ajustados, residuos_padronizados, xlab = "Valores ajustados", ylab = "Resíduos padronizados", main = "Outliers:\nResíduos vs ajustados", pch = 19, col = "blue")
abline(h = c(-3, 3), col = "red", lty = 2, lwd = 2)
abline(h = 0, col = "red", lwd = 1)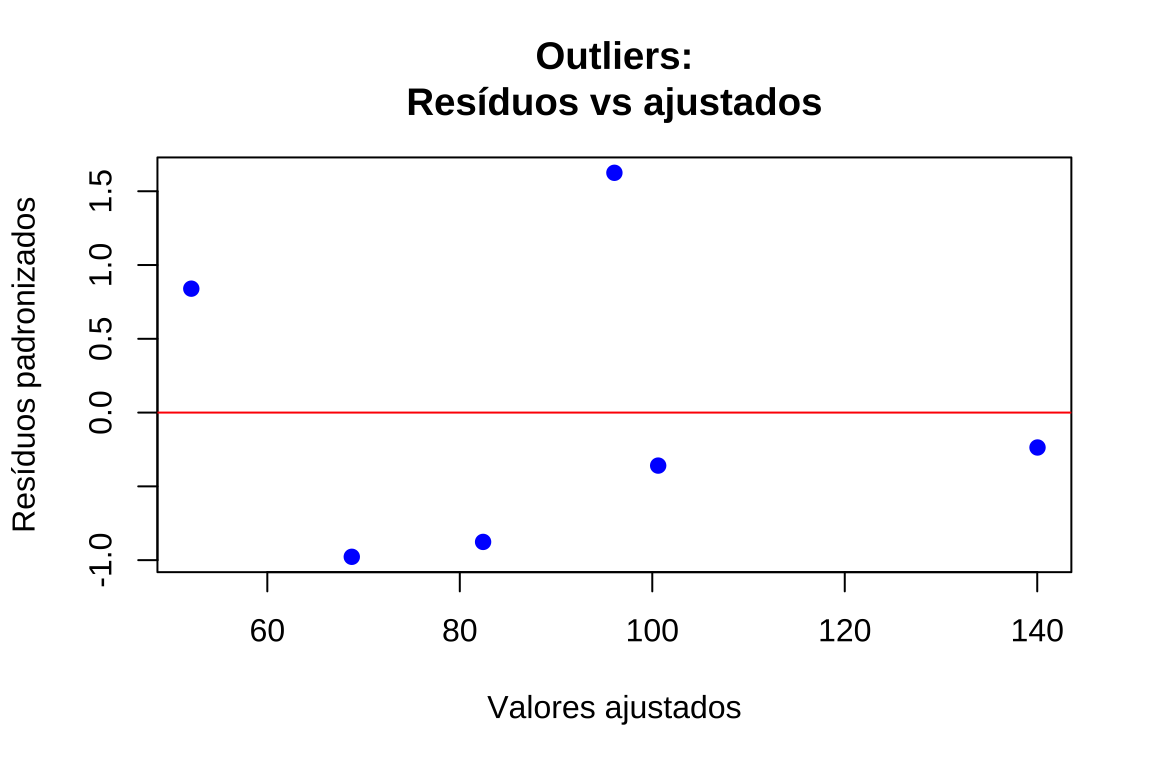
# Gráfico 3: Resíduos padronizados vs variável preditora
plot(anuncios, residuos_padronizados, xlab = "Anúncios", ylab = "Resíduos padronizados", main = "Outliers:\nResíduos vs X",
pch = 19, col = "blue")
abline(h = c(-3, 3), col = "red", lty = 2, lwd = 2)
abline(h = 0, col = "red", lwd = 1)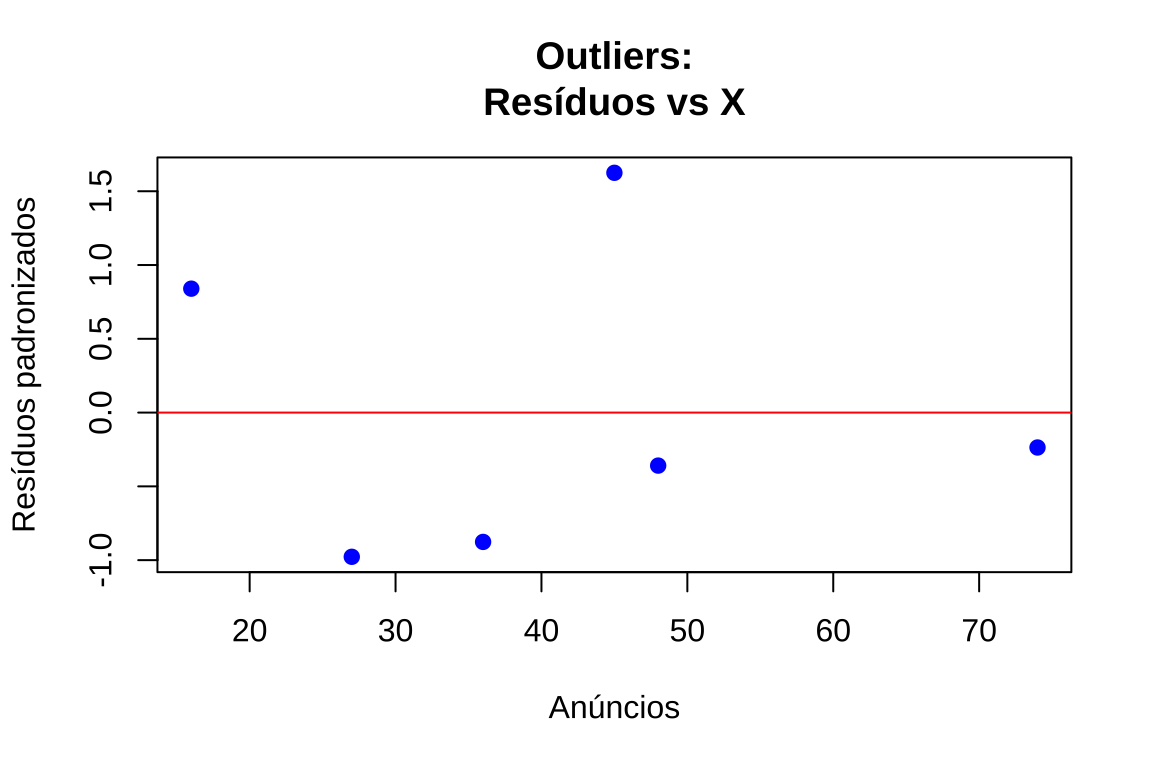
# Gráfico 4: Resíduos studentizados vs valores ajustados
plot(valores_ajustados, residuos_studentizados, xlab = "Valores ajustados", ylab = "Resíduos studentizados", main = "Outliers:\nResíduos studentizados", pch = 19, col = "blue")
abline(h = c(-3, 3), col = "red", lty = 2, lwd = 2)
abline(h = 0, col = "red", lwd = 1)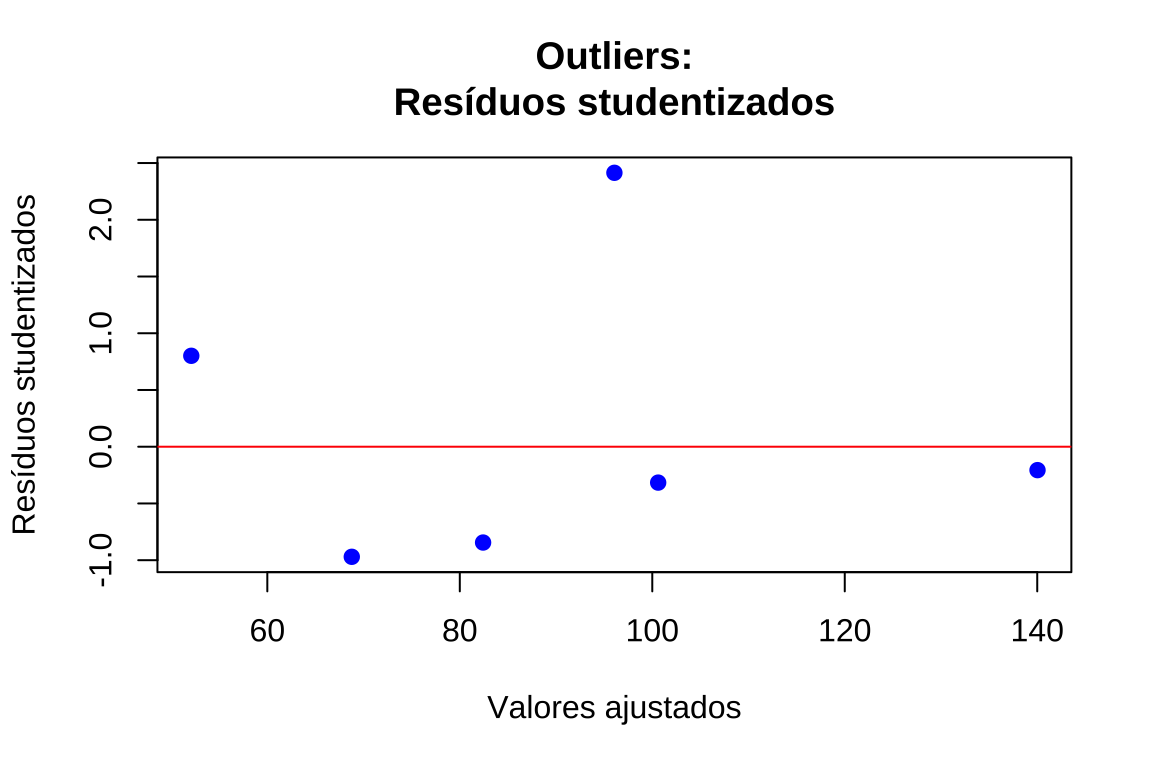
13.7.7 Observações Influentes
Uma observação é considerada influente quando sua presença ou ausência no conjunto de dados altera substancialmente as estimativas dos parâmetros do modelo. A detecção de pontos influentes é crucial devido ao impacto que causam no ajuste do modelo e nos pressupostos, devendo ser analisada em conjunto com as análises de resíduo. A presença de outliers pode:
- Distorcer as estimativas dos coeficientes
- Inflar a variância residual
- Violar pressupostos do modelo (normalidade, homocedasticidade)
A matriz \(\boldsymbol{H}\) (matriz Hat ou matriz chapéu) tem importante papel no diagnóstico de pontos influentes, determinando as variâncias e covariâncias do valor estimado \((\hat{Y})\) e dos erros. Os elementos \(h_{ii}\) da diagonal da matriz de projeção \(H\) são escritos como:
\[ h_{ii} = \boldsymbol{x_i'(X'X})^{-1}x_i \]
em que \(\boldsymbol{x'_i}\) é o vetor transposto da \(i\)-ésima observação do centro no espaço das variáveis preditoras.
Há diferentes opiniões sobre os valores críticos para essa medida:
- \(h_{ii}>2\frac{p}{n}\) (Hoaglin, D. C. and Welsch, R. E, 1978. The hat matrix in regression and ANOVA)
- \(h_{ii}> 3\frac{p}{n}\)
em que \(p\) é o número de parâmetros estimados no modelo (\(\hat{\beta_{0}}\) e \(\hat{\beta_{1}}\): 2 para uma regressão linear simples). Tradicionalmente assume-se que valores de \(h_{ii}\) que excedem \((2p/n)\) indicam pontos influentes que merecem investigação mais detalhada.
David Sam Jayakumar e A. Sulthan (Exact distribution of Hat Values and Identification of Leverage Points, 2014) propuseram a distribuição teóricas exata para os valores da diagonal da matriz de projeção link de acesso ao recurso.
# Dados do Exemplo
dados <- data.frame(
Anuncios = c(74, 45, 48, 36, 27, 16),
Carros_vendidos = c(139, 108, 98, 76, 62, 57)
)
# Ajuste do modelo
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)
# Calcular leverage (hat values)
n <- length(dados$Anuncios)
p <- 2 # número de parâmetros (beta0 e beta1)
hat_values <- hatvalues(modelo)
# Limites críticos
limite_hoaglin <- 2 * p / n
limite_alternativo <- 3 * p / ncat("\nPontos de alavanca (leverage):\n")
cat("Limite de Hoaglin (2p/n):", limite_hoaglin, "\n")
cat("Limite alternativo (3p/n):", limite_alternativo, "\n")
cat("\nValores de leverage:\n")
print(hat_values)
cat("\nPontos com leverage alto (>", limite_hoaglin, "):\n")
print(which(hat_values > limite_hoaglin))->
-> Pontos de alavanca (leverage):
-> Limite de Hoaglin (2p/n): 0.6667
-> Limite alternativo (3p/n): 1
->
-> Valores de leverage:
-> 1 2 3 4 5 6
-> 0.7112 0.1747 0.1912 0.1792 0.2647 0.4792
->
-> Pontos com leverage alto (> 0.6667 ):
-> 1
-> 1# Gráfico: Leverage
plot(1:n, hat_values, xlab = "Índice da observação", ylab = "Leverage", main = "Pontos de alavanca", pch = 19, col = "blue",
ylim=c(0,1))
abline(h = limite_hoaglin, col = "red", lty = 2, lwd = 2)
abline(h = limite_alternativo, col = "orange", lty = 2, lwd = 2)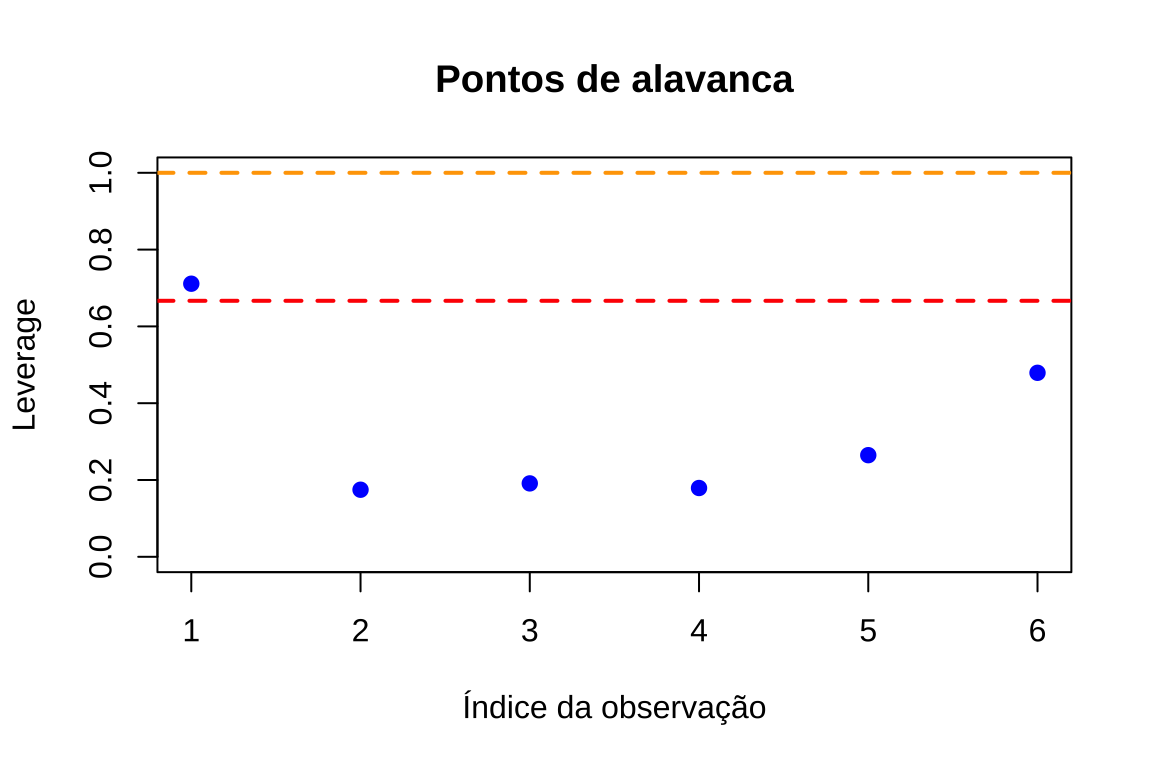
13.7.7.1 DFBetas (Difference in Betas)
A estatística DFBetas indica o quanto cada coeficiente de regressão \(\hat{\beta}_j\) se modifica, em unidades de desvio padrão, se a \(i\)-ésima observação for removida, refletindo a taxa de mudança provocada em \(\hat{\boldsymbol{\beta}}\) pela retirada da observação \(i\):
\[ DFBeta_{j,i} = \frac{\hat{\beta}_j - \hat{\beta}_{j(i)}}{\sqrt{S_{(i)}^2 C_{jj}}} \]
com \(i = 1, 2, \ldots, n\), sendo \(C_{jj}\) o \(j\)-ésimo elemento da diagonal da matriz \(\boldsymbol{C = (X'X)}^{-1}\) e:
\[ S_{(i)}^2 = \frac{(n-p-1)QMRes - e_i^2(1-h_{ii})}{(n-p-1)} \]
onde \(h_{ii}\) é o \(i\)-ésimo componente da diagonal da matriz \(H\).
A observação \(i\) tem influência no \(j\)-ésimo coeficiente de regressão quando \(|DFBeta_{j,i}| > \frac{2}{\sqrt{n}}\), valores esses que requerem exame mais detalhado. O R, por sua vez, adota o critério \(|DFBeta_{j,i}| > 1\), que é menos conservador e, em amostras pequenas, tende a identificar menos observações como influentes.
# DFBetas
dfbetas_valores <- dfbetas(modelo)
# Critério Belsley et al. (1980)
limite_dfbetas_b <- 2 / sqrt(n)
# Critério R
limite_dfbetas_r <- 1
influentes_b <- apply(abs(dfbetas_valores) > limite_dfbetas_b, 1, any)
influentes_r <- apply(abs(dfbetas_valores) > limite_dfbetas_r, 1, any)
obs_influentes_b <- which(influentes_b)
obs_influentes_r <- which(influentes_r)cat("Critério Belsley et al. (1980):\n")
cat(" Limite crítico (2/√n) :", round(limite_dfbetas_b, 4), "\n")
cat(" Observações influentes :", length(obs_influentes_b), "\n\n")
cat("Critério R (influence.measures):\n")
cat(" Limite crítico (1) :", limite_dfbetas_r, "\n")
cat(" Observações influentes :", length(obs_influentes_r), "\n")
cat("Número de observações:", n, "\n")
cat("Número de parâmetros :", p, "\n")-> Critério Belsley et al. (1980):
-> Limite crítico (2/√n) : 0.8165
-> Observações influentes : 0
->
-> Critério R (influence.measures):
-> Limite crítico (1) : 1
-> Observações influentes : 0
-> Número de observações: 6
-> Número de parâmetros : 2cat("\nValores de DFBetas por observação:\n")
cat(sprintf("%-6s %-12s %-12s %-10s %-10s\n", "Obs", "DFBeta(a)", "DFBeta(b)", "Belsley", "R"))
cat(rep("-", 54), "\n", sep="")
for (i in 1:n) {marcador_b <- ifelse(influentes_b[i], "*", " ")
marcador_r <- ifelse(influentes_r[i], "*", " ")
cat(sprintf("%-6d %-12.4f %-12.4f %-10s %-10s\n", i, dfbetas_valores[i, 1], dfbetas_valores[i, 2], marcador_b, marcador_r))}
cat("\n* excede o limite crítico\n")->
-> Valores de DFBetas por observação:
-> Obs DFBeta(a) DFBeta(b) Belsley R
-> ------------------------------------------------------
-> 1 0.1950 -0.2833
-> 2 0.2242 0.2377
-> 3 -0.0081 -0.0550
-> 4 -0.2500 0.1042
-> 5 -0.5114 0.3541
-> 6 0.7514 -0.6207
->
-> * excede o limite crítico13.7.7.2 DFFits (Difference in fits)
A estatística DFFits investiga a influência da \(i\)-ésima observação nos valores ajustados (preditos), refletindo o quanto o valor ajustado se modifica, em unidades de desvio padrão, se a \(i\)-ésima observação for removida:
\[ DFFits_i = \frac{\hat{Y}_i - \hat{Y}_{(i)}}{\sqrt{S_{(i)}^2 h_{ii}}} = \left(\frac{h_{ii}}{1-h_{ii}}\right)^{1/2} r_i \]
com \(i = 1, 2, \ldots, n\), em que \(r_i\) são os resíduos estudentizados, \(\hat{Y}_i\) é o valor predito e \(\hat{Y}_{(i)}\) é o valor predito sem o uso da \(i\)-ésima observação.
Observações com \(|DFFits_i| > 2\sqrt{p/n}\) requerem exame mais detalhado. O R, por sua vez, adota o critério \(|DFFits_i| > 3\sqrt{p/(n-p)}\), que é menos conservador e, em amostras pequenas, tende a identificar menos observações como influentes.
# DFFits
dffits_valores <- dffits(modelo)
# Critério Belsley et al. (1980)
limite_dffits_b <- 2 * sqrt(p / n)
# Critério R
limite_dffits_r <- 3 * sqrt(p / (n - p))
influentes_b <- abs(dffits_valores) > limite_dffits_b
influentes_r <- abs(dffits_valores) > limite_dffits_r
obs_influentes_b <- which(influentes_b)
obs_influentes_r <- which(influentes_r)cat("Critério Belsley et al. (1980):\n")
cat(" Limite crítico (2√(p/n)) :", round(limite_dffits_b, 4), "\n")
cat(" Observações influentes :", length(obs_influentes_b), "\n\n")
cat("Critério R (influence.measures):\n")
cat(" Limite crítico (3√(p/(n-p))) :", round(limite_dffits_r, 4), "\n")
cat(" Observações influentes :", length(obs_influentes_r), "\n")
cat("Número de observações:", n, "\n")
cat("Número de parâmetros :", p, "\n")-> Critério Belsley et al. (1980):
-> Limite crítico (2√(p/n)) : 1.155
-> Observações influentes : 0
->
-> Critério R (influence.measures):
-> Limite crítico (3√(p/(n-p))) : 2.121
-> Observações influentes : 0
-> Número de observações: 6
-> Número de parâmetros : 2cat("\nValores de DFFits por observação:\n")
cat(sprintf("%-6s %-12s %-10s %-10s\n", "Obs", "DFFits", "Belsley", "R"))
cat(rep("-", 42), "\n", sep="")
for (i in 1:n) {marcador_b <- ifelse(influentes_b[i], "*", " ")
marcador_r <- ifelse(influentes_r[i], "*", " ")
cat(sprintf("%-6d %-12.4f %-10s %-10s\n", i, dffits_valores[i], marcador_b, marcador_r))}
cat("\n* excede o limite crítico\n")->
-> Valores de DFFits por observação:
-> Obs DFFits Belsley R
-> ------------------------------------------
-> 1 -0.3238
-> 2 1.1105
-> 3 -0.1537
-> 4 -0.3945
-> 5 -0.5820
-> 6 0.7686
->
-> * excede o limite crítico13.7.7.3 Distância de Cook:
A estatística proposta por Dennis R. Cook mede a influência de uma observação sobre as estimativas dos parâmetros do modelo, quantificando o quanto a linha de regressão se alteraria caso esse dado fosse removido da análise. É uma medida da distância ao quadrado entre a estimativa usual de mínimos quadrados de \(\boldsymbol{\beta}\), baseada em todas observações, e a estimativa obtida quando o \(i\)-ésimo ponto for removido, \(\hat{\boldsymbol{\beta}}_{(i)}\):
\[ D_i = \frac{(\hat{\boldsymbol{\beta}} - \hat{\boldsymbol{\beta}}_{(i)})'(X'X)(\hat{\boldsymbol{\beta}} - \hat{\boldsymbol{\beta}}_{(i)})}{p\hat{\sigma}^2} \]
com \(i = 1, 2, \ldots, n\).
A medida da distância de Cook pode também ser expressa por:
\[ D_i = \frac{r_i^2}{p} \cdot \frac{h_{ii}}{(1-h_{ii})} \]
com \(i = 1, 2, \ldots, n\), onde \(D_i\) consiste no quadrado do resíduo estudentizado, refletindo quão bem o modelo se ajusta à \(i\)-ésima observação \(Y_i\), e o termo \((h_{ii}/(1-h_{ii}))\) é uma medida de distância do \(i\)-ésimo ponto do centroide dos \((n-1)\) pontos restantes.
Na regressão múltipla pode ocorrer de algum subconjunto de observações influenciarem por estarem longe da vizinhança onde o restante dos dados foi coletado, afetando a determinação do \(R^2\), as estimativas dos coeficientes de regressão e a magnitude da média quadrática dos erros. A influência na locação pode ser investigada pelo gráfico das distâncias de Cook contra os valores ajustados.
Há vários critérios para se definir um valor limite para a estatística de Cook:
- \(D_{i}>1\): Cook e Weisberg, 1982 e Chatterjee, Hadi e Price, 2000
- Duas vezes a média das distâncias de Cook
- \(D_{i}> \frac{4}{n}\): Bollen et al, 1990
- Valor crítico do quantil da distribuição F para uma significância igual a 0.5 com df1=p e df2=n-p
Quando \(D_i\) for alto, indica que o \(i\)-ésimo ponto exerce influência; se \(D_i > 1\), indica que o ponto exerce grande influência. O R, por sua vez, adota o critério \(D_i > F_{0{,}5;\, p,\, n-p}\), correspondente ao percentil 50% da distribuição \(F_{p,\, n-p}\), que é mais conservador que o limite \(D_i > 1\) em amostras pequenas.
# Distância de Cook
cook_valores <- cooks.distance(modelo)
# Critério Cook e Weisberg (1982)
limite_cook_b <- 1
# Critério R
limite_cook_r <- qf(0.5, p, n - p)
influentes_b <- cook_valores > limite_cook_b
influentes_r <- cook_valores > limite_cook_r
obs_influentes_b <- which(influentes_b)
obs_influentes_r <- which(influentes_r)cat("Critério Cook e Weisberg (1982):\n")
cat(" Limite crítico (D_i > 1) :", limite_cook_b, "\n")
cat(" Observações influentes :", length(obs_influentes_b), "\n\n")
cat("Critério R (influence.measures):\n")
cat(" Limite crítico F(0,5; p, n-p) :", round(limite_cook_r, 4), "\n")
cat(" Observações influentes :", length(obs_influentes_r), "\n")
cat("Número de observações:", n, "\n")
cat("Número de parâmetros :", p, "\n")-> Critério Cook e Weisberg (1982):
-> Limite crítico (D_i > 1) : 1
-> Observações influentes : 0
->
-> Critério R (influence.measures):
-> Limite crítico F(0,5; p, n-p) : 0.8284
-> Observações influentes : 0
-> Número de observações: 6
-> Número de parâmetros : 2cat("\nValores da Distância de Cook por observação:\n")
cat(sprintf("%-6s %-12s %-10s %-10s\n", "Obs", "D_i", "CW(1982)", "R"))
cat(rep("-", 42), "\n", sep="")
for (i in 1:n) { marcador_b <- ifelse(influentes_b[i], "*", " ")
marcador_r <- ifelse(influentes_r[i], "*", " ")
cat(sprintf("%-6d %-12.4f %-10s %-10s\n", i, cook_valores[i], marcador_b, marcador_r))}
cat("\n* excede o limite crítico\n")->
-> Valores da Distância de Cook por observação:
-> Obs D_i CW(1982) R
-> ------------------------------------------
-> 1 0.0689
-> 2 0.2794
-> 3 0.0152
-> 4 0.0838
-> 5 0.1719
-> 6 0.3244
->
-> * excede o limite crítico13.7.7.4 Influência na Precisão da Estimação
As medidas \(D_i\), \(DFBetas_{j,i}\) e \(DFFits_i\) fornecem uma visão do efeito de cada observação nos coeficientes estimados e nos valores ajustados. Não fornecem, contudo, qualquer informação sobre a precisão geral da estimação. Para expressar o papel da \(i\)-ésima observação na precisão da estimação, utiliza-se a medida:
\[ COVRATIO_i = \frac{|(\boldsymbol{X'_{(i)}X_{(i)}})^{-1}S_{(i)}^2|}{|(\boldsymbol{X'X})^{-1}QMRes|} = \left(\frac{S_i^2}{QMres}\right)^p \cdot \frac{1}{1-h_{ii}} \]
\(i = 1, 2, \ldots, n\) em que \(h_{ii}\) é o \(i\)-ésimo componente da diagonal da matriz \(\boldsymbol{H}\).
Belsley et al. (1980) sugeriram que se: \(1 - 3p/n < COVRATIO_i < 1 + 3p/n\) então, o \(i\)-ésimo ponto é um possível ponto influente. Em geral, esses pontos de corte são mais apropriados para amostras grandes. O R, por sua vez, adota o critério \(1 - 3p/(n-p) < COVRATIO_i < 1 + 3p/(n-p)\), que é menos conservador e, em amostras pequenas, tende a identificar menos observações como influentes.
covratio_valores <- covratio(modelo)
# Critério Belsley et al. (1980)
limite_superior_b <- 1 + (3 * p / n)
limite_inferior_b <- 1 - (3 * p / n)
# Critério R
limite_superior_r <- 1 + (3 * p / (n - p))
limite_inferior_r <- 1 - (3 * p / (n - p))
influentes_b <-
(covratio_valores > limite_superior_b) | (covratio_valores < limite_inferior_b)
influentes_r <-
(covratio_valores > limite_superior_r) | (covratio_valores < limite_inferior_r)
obs_influentes_b <- which(influentes_b)
obs_influentes_r <- which(influentes_r)cat("Critério Belsley et al. (1980):\n")
cat(" Limite superior (1 + 3p/n) :", round(limite_superior_b, 4), "\n")
cat(" Limite inferior (1 - 3p/n) :", round(limite_inferior_b, 4), "\n")
cat(" Observações influentes :", length(obs_influentes_b), "\n\n")
cat("Critério R (influence.measures):\n")
cat(" Limite superior (1 + 3p/(n-p)):", round(limite_superior_r, 4), "\n")
cat(" Limite inferior (1 - 3p/(n-p)):", round(limite_inferior_r, 4), "\n")
cat(" Observações influentes :", length(obs_influentes_r), "\n")
cat("Número de observações:", n, "\n") ; cat("Número de parâmetros :", p, "\n")-> Critério Belsley et al. (1980):
-> Limite superior (1 + 3p/n) : 2
-> Limite inferior (1 - 3p/n) : 0
-> Observações influentes : 3
->
-> Critério R (influence.measures):
-> Limite superior (1 + 3p/(n-p)): 2.5
-> Limite inferior (1 - 3p/(n-p)): -0.5
-> Observações influentes : 1
-> Número de observações: 6
-> Número de parâmetros : 2cat("\nValores de COVRATIO por observação:\n")
cat(sprintf("%-6s %-12s %-10s %-10s\n", "Obs", "COVRATIO", "Belsley", "R"))
cat(rep("-", 42), "\n", sep="")
for (i in 1:n) { marcador_b <- ifelse(influentes_b[i], "*", " ")
marcador_r <- ifelse(influentes_r[i], "*", " ")
cat(sprintf("%-6d %-12.4f %-10s %-10s\n", i, covratio_valores[i], marcador_b, marcador_r))}
cat("\n* excede os limites críticos\n")->
-> Valores de COVRATIO por observação:
-> Obs COVRATIO Belsley R
-> ------------------------------------------
-> 1 5.9840 * *
-> 2 0.2488
-> 3 2.0584 *
-> 4 1.4139
-> 5 1.4009
-> 6 2.3159 *
->
-> * excede os limites críticosinflm.model <- influence.measures(modelo)
colnames(inflm.model$infmat) <- c("dfb.beta0", "dfb.beta1", "dffit", "cov.r", "cook.d", "hat")
inflm.model-> Influence measures of
-> lm(formula = Carros_vendidos ~ Anuncios, data = dados) :
->
-> dfb.beta0 dfb.beta1 dffit cov.r cook.d hat inf
-> 1 0.19504 -0.283 -0.324 5.984 0.0689 0.711 *
-> 2 0.22417 0.238 1.111 0.249 0.2794 0.175
-> 3 -0.00812 -0.055 -0.154 2.058 0.0152 0.191
-> 4 -0.24997 0.104 -0.394 1.414 0.0838 0.179
-> 5 -0.51140 0.354 -0.582 1.401 0.1719 0.265
-> 6 0.75140 -0.621 0.769 2.316 0.3244 0.47913.7.8 Multicolinearidade: Fator de Inflação da Variância (VIF)
Na regressão linear múltipla, além das dependências entre a variável resposta \(Y\) e os regressores \(X_j\), frequentemente ocorrem dependências entre os próprios regressores. Quando duas variáveis preditoras apresentam correlação perfeita, a matriz \((X^TX)\) torna-se singular (determinante = 0), impedindo a estimação dos coeficientes por mínimos quadrados.
set.seed(42)
n <- 100
x1 <- rnorm(n)
x2 <- 2 * x1 # Correlação perfeita
y <- 3 + 5*x1 + rnorm(n, 0, 0.1)
# Correlação
cat("A correlação entre as variáveis é:", cor(x1,x2), "\n")
# Tentativa de ajuste (o R remove uma variável)
cat("No ajuste do modelo, o R remove automaticamente variáveis redundantes (nota `NA` no seu coeficiente)","\n")
modelo <- lm(y ~ x1 + x2)-> A correlação entre as variáveis é: 1
-> No ajuste do modelo, o R remove automaticamente variáveis redundantes (nota `NA` no seu coeficiente)Consequências
- Coeficientes indeterminados (infinitas soluções)
- Variância infinita dos estimadores
- Inferência estatística impossível
A presença da multicolinearidade pode ser detectada de várias maneiras:
- Critério do VIF: quanto maior o VIF, mais severa é a multicolinearidade. Valores de \(VIF_j > 10\) indicam multicolinearidade problemática, enquanto \(VIF_j > 5\) já sugere atenção.
- Inconsistência nos testes: se o teste F para significância global da regressão for significativo, mas os testes t individuais dos coeficientes não forem significativos, então a multicolinearidade está presente.
- Sinais dos coeficientes: coeficientes com sinais contrários à expectativa teórica podem indicar multicolinearidade.
Soluções:
- Aumentar o tamanho amostral com novas observações especificamente projetadas para fragmentar as dependências lineares
- Remover variáveis altamente correlacionadas do modelo (com a desvantagem de perder informação)
- Utilizar métodos alternativos de estimação menos sensíveis à multicolinearidade, como Regressão Ridge ou Regressão de Componentes Principais
Não situações onde a multicolinearidade não é perfeita, uma medida de sua intensidade é dada pelo Fator de Inflação da Variância (Variance Inflation Factor-VIF). O VIF quantifica a multicolinearidade de cada preditor:
\[ VIF_j = \frac{1}{1 - R_j^2} \]
onde \(R_j^2\) é o coeficiente de determinação da regressão de \(x_j\) contra os demais preditores.
Interpretação
- VIF = 1: Sem correlação
- VIF < 5: Aceitável
- VIF ≥ 10: Multicolinearidade problemática
Por que “Inflação”?
\[ \text{Var}(\hat{\beta}_j) = \frac{\sigma^2}{(n-1)s_j^2} \cdot VIF_j \]
O VIF multiplica a variância do estimador.
library(car);set.seed(42)
n <- 100;x1 <- rnorm(n)
x2 <- x1 + rnorm(n, 0, 0.1) # Correlacionada com x1
x3 <- rnorm(n)
y <- 2 + 3*x1 + 4*x3 + rnorm(n)
modelo <- lm(y ~ x1 + x2 + x3)->
-> Call:
-> lm(formula = y ~ x1 + x2 + x3)
->
-> Residuals:
-> Min 1Q Median 3Q Max
-> -1.794 -0.587 -0.104 0.619 2.328
->
-> Coefficients:
-> Estimate Std. Error t value Pr(>|t|)
-> (Intercept) 2.0315 0.0891 22.79 <2e-16 ***
-> x1 2.9695 0.9964 2.98 0.0037 **
-> x2 0.0883 0.9890 0.09 0.9291
-> x3 3.9684 0.0888 44.68 <2e-16 ***
-> ---
-> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
->
-> Residual standard error: 0.887 on 96 degrees of freedom
-> Multiple R-squared: 0.968, Adjusted R-squared: 0.967
-> F-statistic: 953 on 3 and 96 DF, p-value: <2e-16cat("Os VIF das variáveis são:","\n")
vif(modelo)
# x1 e x2 terão VIF alto (~100)
# x3 terá VIF próximo de 1
# Correlação entre preditores
cat("A correlação linear par a par das variáveis é:","\n")
cor(data.frame(x1, x2, x3))-> Os VIF das variáveis são:
-> x1 x2 x3
-> 135.569 135.292 1.027
-> A correlação linear par a par das variáveis é:
-> x1 x2 x3
-> x1 1.0000 0.9963 -0.1448
-> x2 0.9963 1.0000 -0.1377
-> x3 -0.1448 -0.1377 1.0000Observações:
- o VIF só se aplica a modelos de regressão múltipla (com duas ou mais variáveis preditoras). Em regressão linear simples, não há razão para se falar em multicolinearidade.
- ele não indica qual variável remover
->
-> ========================================
-> FATOR DE INFLAÇÃO DA VARIÂNCIA (VIF)
-> ========================================
-> Critério: VIF > 10 indica multicolinearidade severa
-> VIF > 5 sugere atenção
->
-> x1 x2 x3
-> 135.569 135.292 1.027
->
-> Variáveis com multicolinearidade severa (VIF > 10):
-> - x1 : 135.57
-> - x2 : 135.2913.8 Métricas de Aferição da Qualidade de Ajuste de uma Regressão Linear
13.8.1 Coeficiente de determinação \(R^{2}\) da Regressão Linear
O coeficiente de determinação (\(R^{2}\)) é uma medida estatística que informa o quanto da variação observada na variável \(Y\) está sendo explicada no modelo pela relação linear estabelecida com a variável \(X\).
\[ R^{2} = \frac{\text{variação explicada}}{\text{variação total}} \]
\[ R^{2} = \frac{\sum_{i=1}^{n} (\hat{y}_i - \bar{y})^{2}}{\sum_{i=1}^{n} (y_i - \bar{y})^{2}} = \frac{SQReg}{SQTotal} = \frac{SQReg}{S_{yy}} \]
\[
R^{2} = \frac{b \cdot S_{xy}}{S_{yy}}
\]
\[
R^{2}_{ajustado} = 1 - \frac{(1-R^2)(n-1)}{n-p-1}
\]
em que \(n\) é o número de observações, \(p\) é o número de variáveis independentes.
->
-> ========================================
-> COEF. DE DETERMINAÇÃO
-> ========================================
-> R²: 0.9675
-> R² ajustado: 0.966513.8.2 AIC (Akaike Information Criterion) e RMSE (Root Mean Squared Error)
O AIC é um critério de informação que equilibra a qualidade do ajuste com a complexidade do modelo, penalizando a inclusão de parâmetros adicionais.
O RMSE representa a raiz quadrada da média dos quadrados dos resíduos, fornecendo uma medida da dispersão dos erros na mesma escala da variável resposta, facilitando a interpretação da magnitude dos erros de predição.
Menores valores de AIC e de RMSE indicam melhor modelo, sendo particularmente úteis na comparação.
# Cálculo das métricas
aic_valor <- AIC(modelo)
rmse_valor <- sqrt(mean(residuals(modelo)^2))
# Relatório textual
cat("AIC:", round(aic_valor, 4), "\n")-> AIC: 265.7-> RMSE: 0.868813.9 Testes de Hipóteses da Regressão Linear
13.9.1 Análise de Variância da Regressão - ANOVA (Teste F)
A análise de variância comprova estatisticamente se os dados apresentam a suposta relação linear entre a variável preditora \(X\) e a variável resposta \(Y\). O procedimento estatístico consiste em testar a hipótese:
\[ \begin{cases} H_0: \beta = 0 \hspace{0.5cm} \text{(não há regressão)} \\ H_1: \beta \neq 0 \end{cases} \]
Sob \(H_0\), a estatística do teste \(F_{calc}\) pode ser calculada pela tabela ANOVA:
| Causa de Variação | GL | Soma de Quadrados | Quadrado Médio | F |
|---|---|---|---|---|
| Regressão | \(1\) | \(SQReg\) | \(QMReg = SQReg\) | \(\frac{QMReg}{QMRes}\) |
| Resíduo | \(n-2\) | \(SQRes\) | \(QMRes = \frac{SQRes}{n-2}\) | |
| Total | \(n-1\) | \(SQTotal\) |
em que \(F_{calc}\) segue a distribuição F de Fisher-Snedecor com \(1\) grau de liberdade no numerador e \((n-2)\) graus de liberdade no denominador.
Regra de decisão: Rejeita-se \(H_0\) ao nível de significância \(\alpha\) se \(F_{calc} \geq F_{tab}[1, (n-2); \alpha]\), concluindo-se que existe regressão significativa.
Ao realizar a análise de variância, o procedimento é particionar a variação total em duas componentes:
\[ \underbrace{\sum_{i=1}^{n}(y_i - \bar{y})^2}_{SQTotal} = \underbrace{\sum_{i=1}^{n}(y_i - \hat{y}_i)^2}_{SQRes} + \underbrace{\sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2}_{SQReg} \]
em que:
- \(SQTotal\): variação total de \(Y\) em torno da média
- \(SQRes\): variação de \(Y\) em torno dos valores ajustados (variação não explicada)
- \(SQReg\): variação dos valores ajustados em torno da média (variação explicada pelo modelo)
Note que \(SQTotal\) pode ser expressa equivalentemente como:
\[ SQTotal = \sum_{i=1}^{n}(y_i - \bar{y})^2 = S_{yy}, \]
em que \(S_{yy}\) é a soma de quadrados dos desvios de \(y\):
\[ S_{yy} = \sum_{i=1}^{n} y_i^{2} - \frac{\left(\sum_{i=1}^{n} y_{i}\right)^2}{n}. \]
Analogamente, \(SQRes\) e \(SQReg\) podem ser expressas como:
\[ SQRes = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2 = S_{yy} - b \cdot S_{xy} \]
\[ SQReg = \sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2 = b \cdot S_{xy}. \]
Portanto, a decomposição pode ser reescrita como:
\[ S_{yy} = SQRes + SQReg. \]
# Dados do Exemplo
dados <- data.frame(
Anuncios = c(74, 45, 48, 36, 27, 16),
Carros_vendidos = c(139, 108, 98, 76, 62, 57)
)
# Ajuste do modelo
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)anova_resultado <- anova(modelo);print(anova_resultado)
p_valor_anova <- anova_resultado$`Pr(>F)`[1]
if (p_valor_anova < 0.05) { cat("\nConclusão: p-valor =", round(p_valor_anova, 4), "< 0,05.\n Rejeita-se H0: a regressão é estatisticamente significativa.\n")} else { cat("\nConclusão: p-valor =", round(p_valor_anova, 4), "> 0,05. \nNão se rejeita H0: a regressão não é estatisticamente significativa.\n")}-> Analysis of Variance Table
->
-> Response: Carros_vendidos
-> Df Sum Sq Mean Sq F value Pr(>F)
-> Anuncios 1 4597 4597 70.3 0.0011 **
-> Residuals 4 261 65
-> ---
-> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
->
-> Conclusão: p-valor = 0.0011 < 0,05.
-> Rejeita-se H0: a regressão é estatisticamente significativa.Para regressão linear simples (\(p=1\)), os graus de liberdade da regressão são 1 e do resíduo \(n-2\), e o teste F é equivalente ao teste t do coeficiente (\(F = t^2\)).
13.9.2 Extensão da ANOVA para Regressão Múltipla
No caso de regressão múltipla, com \(p\) variáveis independentes \((X_1, X_2, \ldots, X_p)\), o modelo é:
\[ Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \ldots + \beta_p X_{ip} + \varepsilon_i \]
As hipóteses testadas são:
\[ \begin{cases} H_0: \beta_1 = \beta_2 = \ldots = \beta_p = 0 \hspace{0.5cm} \text{(não há regressão)} \\ H_1: \text{pelo menos um } \beta_j \neq 0 \end{cases} \]
A tabela ANOVA se modifica para:
| Causa de Variação | GL | Soma de Quadrados | Quadrado Médio | F |
|---|---|---|---|---|
| Regressão | \(p\) | \(SQReg\) | \(QMReg = \frac{SQReg}{p}\) | \(\frac{QMReg}{QMRes}\) |
| Resíduo | \(n-p-1\) | \(SQRes\) | \(QMRes = \frac{SQRes}{n-p-1}\) | |
| Total | \(n-1\) | \(SQTotal\) |
em que \(F_{calc} \sim F_{(p, n-p-1)}\) sob \(H_0\).
Regra de decisão: Rejeita-se \(H_0\) ao nível de significância \(\alpha\) se \(F_{calc} \geq F_{tab}[p, (n-p-1); \alpha]\).
A decomposição da variabilidade permanece válida:
\[ SQTotal = SQRes + SQReg. \]
A estimação das expressões explícitas para \(SQReg\) e \(SQRes\) envolvem álgebra matricial.
13.9.3 Testes de Hipóteses para os Parâmetros do Modelo de Regressão
Os testes de hipóteses sobre os parâmetros do modelo de regressão linear partem da validação do pressuposto de que os erros \(\varepsilon_i \sim NID(0, \sigma^2)\).
13.9.3.1 Coeficiente Linear (\(\alpha\))
O procedimento para se testar a hipótese sobre o intercepto é:
\[ \begin{cases} H_0: \alpha = \alpha_{0} \\ H_1: \alpha \neq \alpha_{0} \end{cases} \]
para o qual se usa a estatística \(t_{calc}\):
\[ t_{calc} = \frac{a - \alpha_0}{\sqrt{QMRes\left(\frac{1}{n} + \frac{\bar{x}^2}{S_{xx}}\right)}} \]
que sob \(H_0\) segue uma distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade. Rejeita-se \(H_0\) se \(|t_{calc}| > t_{\alpha/2;\,(n-p-1)}\), em que \(t_{\alpha/2;\,(n-p-1)}\) é o quantil \((1-\alpha/2)\) da distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade, para um nível de significância \(\alpha\).
Para a regressão linear simples, os graus de liberdade reduzem-se a \((n-2)\).
13.9.3.2 Regressão (\(\beta_j\))
O teste de hipóteses de um regressor \(\beta_j\) contra um valor \(\beta_{j,0}\) é:
\[ \begin{cases} H_0: \beta_j = \beta_{j,0} \\ H_1: \beta_j \neq \beta_{j,0} \end{cases} \]
para o qual se usa a estatística \(t_{calc_j}\):
\[ t_{calc_j} = \frac{\hat{\beta}_j - \beta_{j,0}}{\sqrt{QMRes \cdot C_{jj}}} \]
em que \(C_{jj}\) é o \(j\)-ésimo elemento da diagonal da matriz \((X'X)^{-1}\), que sob \(H_0\) segue uma distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade. Rejeita-se \(H_0\) se \(|t_{calc_j}| > t_{\alpha/2;\,(n-p-1)}\), em que \(t_{\alpha/2;\,(n-p-1)}\) é o quantil \((1-\alpha/2)\) da distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade, para um nível de significância \(\alpha\).
Um caso especial importante é testar \(H_0: \beta_j = 0\) versus \(H_1: \beta_j \neq 0\), cuja hipótese está relacionada com a significância individual do preditor. Se \(H_0: \beta_j = 0\) não for rejeitada, isto implica que a variável \(x_j\) não contribui significativamente para o modelo na presença das demais variáveis.
Para a regressão linear simples a hipótese se reduz a:
\[ \begin{cases} H_0: \beta = \beta_0 \\ H_1: \beta \neq \beta_0 \end{cases} \]
e como \(C_{11} = 1/S_{xx}\), os graus de liberdade são \((n-2)\), e a estatística de teste se reduz a:
\[ t_{calc} = \frac{b - \beta_0}{\sqrt{QMRes/S_{xx}}} \]
Rejeita-se \(H_0\) se \(|t_{calc}| > t_{\alpha/2;\,(n-2)}\), em que \(t_{\alpha/2;\,(n-2)}\) é o quantil \((1-\alpha/2)\) da distribuição \(t\) de Student com \((n-2)\) graus de liberdade, para um nível de significância \(\alpha\).
->
-> Call:
-> lm(formula = Carros_vendidos ~ Anuncios, data = dados)
->
-> Residuals:
-> 1 2 3 4 5 6
-> -1.03 11.94 -2.61 -6.42 -6.78 4.90
->
-> Coefficients:
-> Estimate Std. Error t value Pr(>|t|)
-> (Intercept) 27.844 8.114 3.43 0.0265 *
-> Anuncios 1.516 0.181 8.39 0.0011 **
-> ---
-> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
->
-> Residual standard error: 8.09 on 4 degrees of freedom
-> Multiple R-squared: 0.946, Adjusted R-squared: 0.933
-> F-statistic: 70.3 on 1 and 4 DF, p-value: 0.0011113.10 Intervalos de Confiança para os Parâmetros do Modelo de Regressão Linear
Nota: apenas nesta seção adotaremos \(\gamma\) para o nível de significância do intervalo de confiança de modo a não ser confundido com o coeficiente linear (\(\alpha\)) do modelo.
13.10.1 Coeficiente Linear (\(\alpha\))
O intervalo de confiança de \((1-\gamma)100\%\) para o coeficiente linear é dado por:
\[ IC(\alpha; (1-\gamma)) = a \pm t_{\gamma/2;(n-p-1)} \sqrt{QMRes\left(\frac{1}{n} + \frac{\bar{x}^2}{S_{xx}}\right)} \]
em que \(t_{\gamma/2;(n-p-1)}\) é o quantil \((1-\gamma/2)\) da distribuição t de Student com \((n-p-1)\) graus de liberdade. Para regressão linear simples, os graus de liberdade são \((n-2)\).
13.10.2 Regressor (\(\beta_j\))
O intervalo de confiança de \((1-\gamma)100\%\) para um regressor \(\beta_j\) é dado por:
\[ IC(\beta_j; 1-\gamma) = \hat{\beta}_j \pm t_{\gamma/2;(n-p-1)} \sqrt{QMRes \cdot C_{jj}} \]
em que \(C_{jj}\) é o \(j\)-ésimo elemento da diagonal da matriz \((X'X)^{-1}\) e \(t_{\gamma/2;(n-p-1)}\) é o quantil \((1-\gamma/2)\) da distribuição t de Student com \((n-p-1)\) graus de liberdade.
Para regressão linear simples, \(C_{11} = 1/S_{xx}\), os graus de liberdade são \((n-2)\), e o intervalo se reduz a:
\[ IC(\beta; 1-\gamma) = b \pm t_{\gamma/2;(n-2)} \sqrt{\frac{QMRes}{S_{xx}}} \]
-> 2.5 % 97.5 %
-> (Intercept) 5.315 50.373
-> Anuncios 1.014 2.01813.10.3 Variância (\(\sigma^2\))
Se os erros são independentes e normalmente distribuídos, a distribuição amostral de \(\frac{(n-p-1)QMRes}{\sigma^2}\) é qui-quadrado com \((n-p-1)\) graus de liberdade, ou seja:
\[ P\left\{\chi^2_{1-\gamma/2;(n-p-1)} \leq \frac{(n-p-1)QMRes}{\sigma^2} \leq \chi^2_{\gamma/2;(n-p-1)}\right\} = (1-\gamma) \]
e consequentemente, o intervalo de confiança de \((1-\gamma)100\%\) para \(\sigma^2\) é dado por:
\[ IC(\sigma^2; 1-\gamma) = \left[\frac{(n-p-1)QMRes}{\chi^2_{\gamma/2;(n-p-1)}}, \frac{(n-p-1)QMRes}{\chi^2_{1-\gamma/2;(n-p-1)}}\right] \]
em que \(\chi^2_{\gamma/2;(n-p-1)}\) e \(\chi^2_{1-\gamma/2;(n-p-1)}\) são os quantis \((\gamma/2)\) e \((1-\gamma/2)\) da distribuição qui-quadrado com \((n-p-1)\) graus de liberdade, respectivamente. Para regressão linear simples, os graus de liberdade são \((n-2)\).
# Dados do Exemplo
dados <- data.frame(Anuncios = c(74, 45, 48, 36, 27, 16), Carros_vendidos = c(139, 108, 98, 76, 62, 57))
# Ajuste do modelo
modelo <- lm(Carros_vendidos ~ Anuncios, data = dados)
n <- length(dados$Anuncios) ; gl <- n - 2
QMRes <- (summary(modelo)$sigma)^2
ICvar <- QMRes * (gl) / qchisq(c(0.025, 0.975), df = gl, lower.tail = FALSE)
# Relatório textual
cat("Graus de liberdade:", gl, "\n")
cat("QMRes:", round(QMRes, 4), "\n")
cat("Nível de confiança: 95%\n")
cat("IC(σ²; 0.95) = [", round(ICvar[1], 4), ";", round(ICvar[2], 4), "]\n")-> Graus de liberdade: 4
-> QMRes: 65.37
-> Nível de confiança: 95%
-> IC(σ²; 0.95) = [ 23.47 ; 539.8 ]13.10.4 Intervalo de Confiança para o Valor Esperado de uma Observação: \(E[Y|\mathbf{X}]\)
A esperança de \(Y\), dados valores específicos \(\mathbf{x}_0\) das variáveis regressoras, é dada por \(E[Y|\mathbf{x}_0] = \beta_0 + \beta_1 x_{01} + \beta_2 x_{02} + \ldots + \beta_p x_{0p}\), sob o modelo de regressão linear múltipla, onde \(\beta_0\) é o intercepto e \(\beta_j\) são os coeficientes angulares.
Na forma matricial, com \(\boldsymbol{\theta} = [\beta_0, \beta_1, \beta_2, \ldots, \beta_p]'\) sendo o vetor de parâmetros, pode-se definir um intervalo de confiança para \(E[Y|\mathbf{x}_0]\) através da seguinte quantidade pivotal:
\[ \frac{\mathbf{x}_0'\hat{\boldsymbol{\theta}} - \mathbf{x}_0'\boldsymbol{\theta}}{\sqrt{QMRes \cdot \mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0}} \]
que tem distribuição \(t\) de Student com \((n-p-1)\) graus de liberdade, onde \(\mathbf{x}_0 = [1, x_{01}, x_{02}, \ldots, x_{0p}]'\) é o vetor de valores específicos das variáveis preditoras (incluindo o 1 para o intercepto).
Portanto, o intervalo de confiança de \((1-\gamma)100\%\) para \(E[Y|\mathbf{x}_0]\) é dado por:
\[ IC(E[Y|\mathbf{x}_0]; 1-\gamma) = \mathbf{x}_0'\hat{\boldsymbol{\theta}} \pm t_{\gamma/2;(n-p-1)} \sqrt{QMRes \cdot \mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0} \]
em que \(t_{\gamma/2;(n-p-1)}\) é o quantil \((1-\gamma/2)\) da distribuição t de Student com \((n-p-1)\) graus de liberdade. A amplitude deste intervalo é:
\[ 2 \cdot t_{\gamma/2;(n-p-1)} \sqrt{QMRes \cdot \mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0} \]
Para regressão linear simples, \(\mathbf{x}_0 = [1, x_0]'\), \(\hat{\boldsymbol{\theta}} = [\hat{\alpha}, \hat{\beta}]'\), \(\mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0 = \frac{1}{n} + \frac{(x_0-\bar{x})^2}{S_{xx}}\), os graus de liberdade são \((n-2)\), e o intervalo se reduz a:
\[ IC(E[Y|x_0]; 1-\gamma) = \hat{\alpha} + \hat{\beta} x_0 \pm t_{\gamma/2;(n-2)} \sqrt{QMRes\left[\frac{1}{n} + \frac{(x_0-\bar{x})^2}{S_{xx}}\right]} \]
O intervalo de confiança fornece informação sobre a precisão das estimativas, no sentido de que quanto menor a amplitude do intervalo maior a precisão.
Com os cálculos dos intervalos de confiança para alguns valores de \(x\), pode-se esboçar uma região em torno da reta estimada, indicando os limites superiores e inferiores desses intervalos.
Essa região também é chamada de bandas de confiança.
# Cálculo dos intervalos de confiança
icconf <- predict(modelo, interval = "confidence", level = 0.95)
ordem <- order(dados$Anuncios)
x_ord <- dados$Anuncios[ordem]library(ggplot2)
icconf_df <- as.data.frame(icconf)
icconf_df$Anuncios <- dados$Anuncios
plt <- ggplot(icconf_df, aes(x = Anuncios)) +
geom_point(aes(y = dados$Carros_vendidos), color = "blue", size = 3) +
geom_line(aes(y = fit), color = "red", linewidth = 1) +
geom_line(aes(y = lwr), color = "darkgreen", linetype = "dashed", linewidth = 1) +
geom_line(aes(y = upr), color = "darkgreen", linetype = "dashed", linewidth = 1) +
geom_ribbon(aes(ymin = lwr, ymax = upr), fill = "green", alpha = 0.2) +
labs(title = "Regressão Linear com Bandas de Confiança (95%)",
x = "Anúncios",
y = "Carros Vendidos") +
theme_minimal()
->
-> Intervalos de Confiança para E[Y|x]:
-> fit lwr upr
-> 1 140.03 121.10 158.96
-> 2 96.06 86.68 105.45
-> 3 100.61 90.80 110.43
-> 4 82.42 72.92 91.92
-> 5 68.78 57.23 80.32
-> 6 52.10 36.56 67.6413.10.5 Intervalo de Confiança para a Predição do Valor de um Dado não Observado
Suponha que estamos interessados em fazer uma predição para um valor de \(Y_0\) (não observado) correspondente a valores específicos \(\mathbf{x}_0\) das variáveis preditoras.
Este intervalo frequentemente é mais relevante para o cientista do que o intervalo de confiança para as respostas médias, pois incorpora tanto a incerteza na estimação dos parâmetros quanto a variabilidade aleatória individual.
Para o modelo de regressão linear bem ajustado, \(\hat{Y}_0 = \mathbf{x}_0'\hat{\boldsymbol{\theta}}\) é a predição de \(Y_0\), onde \(\hat{\boldsymbol{\theta}} = [\hat{\beta_0}, \hat{\beta}_1, \ldots, \hat{\beta}_p]'\) é o vetor de parâmetros estimados. Note que a predição de \(Y_0\) é igual ao estimador do valor esperado de \(Y\) para \(\mathbf{x} = \mathbf{x}_0\).
O erro de predição é definido por \((Y_0 - \hat{Y}_0)\), o qual será a base para construirmos o intervalo de predição. Como \(Y_0\) não faz parte da amostra utilizada no ajuste do modelo, é independente de \(\hat{Y}_0\). Portanto:
\[ E[Y_0 - \hat{Y}_0] = 0 \]
\[ V[Y_0 - \hat{Y}_0] = \sigma^2\left[1 + \mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0\right] \]
em que o termo adicional \(1\) representa a variabilidade individual de uma nova observação.
Como \([Y_0 - \hat{Y}_0]\) segue uma distribuição normal, o intervalo de predição de \((1-\gamma)100\%\) para um novo valor \(Y_0\) dado \(\mathbf{x}_0\) é definido por:
\[ IP(Y_0|\mathbf{x}_0; 1-\gamma) = \mathbf{x}_0'\hat{\boldsymbol{\theta}} \pm t_{\gamma/2;(n-p-1)} \sqrt{QMRes\left[1 + \mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0\right]} \]
em que \(t_{\gamma/2;(n-p-1)}\) é o quantil \((1-\gamma/2)\) da distribuição t de Student com \((n-p-1)\) graus de liberdade.
A amplitude do intervalo de predição é:
\[ 2 \cdot t_{\gamma/2;(n-p-1)} \sqrt{QMRes\left[1 + \mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0\right]} \] —
Diferença fundamental: Enquanto o intervalo de confiança refere-se ao valor esperado \(E[Y|\mathbf{x}_0]\) (uma constante populacional), o intervalo de predição tem probabilidade \((1-\gamma)\) de conter um futuro valor individual \(Y_0\) da variável aleatória, sendo portanto sempre mais amplo devido ao termo adicional \(1\) na variância.
As bandas de confiança e as bandas de predição têm formato hiperbólico, o que enfatiza o risco de fazer extrapolações (predições fora do intervalo observado das variáveis \(X\)). Portanto, os modelos devem ser usados com cautela para fazer previsões sobre a variável resposta.
Para regressão linear simples, \(\mathbf{x}_0 = [1, x_0]'\), \(\mathbf{x}_0'(X'X)^{-1}\mathbf{x}_0 = \frac{1}{n} + \frac{(x_0-\bar{x})^2}{S_{xx}}\), os graus de liberdade são \((n-2)\), e o intervalo se reduz a:
\[ IP(Y_0|x_0; 1-\gamma) = \hat{\alpha} + \hat{\beta} x_0 \pm t_{\gamma/2;(n-2)} \sqrt{QMRes\left(1 + \frac{1}{n} + \frac{(x_0-\bar{x})^2}{S_{xx}}\right)} \]
# Bloco 1 — Cálculo dos intervalos
icconf <- predict(modelo, interval = "confidence", level = 0.95)
icpred <- predict(modelo, interval = "prediction", level = 0.95)cat("\nIntervalos de Confiança para E[Y|x]:\n");print(round(icconf, 2))
cat("\nIntervalos de Predição para Y₀:\n");print(round(icpred, 2))->
-> Intervalos de Confiança para E[Y|x]:
-> fit lwr upr
-> 1 140.03 121.10 158.96
-> 2 96.06 86.68 105.45
-> 3 100.61 90.80 110.43
-> 4 82.42 72.92 91.92
-> 5 68.78 57.23 80.32
-> 6 52.10 36.56 67.64
->
-> Intervalos de Predição para Y₀:
-> fit lwr upr
-> 1 140.03 110.66 169.39
-> 2 96.06 71.73 120.39
-> 3 100.61 76.11 125.11
-> 4 82.42 58.04 106.80
-> 5 68.78 43.53 94.02
-> 6 52.10 24.80 79.40# Bloco 2 — Preparação dos dados para o ggplot
library(ggplot2)
ordem <- order(dados$Anuncios)
df_plot <- data.frame(
x = dados$Anuncios,
y = dados$Carros_vendidos,
fit = icconf[, "fit"],
ci_l = icconf[, "lwr"],
ci_u = icconf[, "upr"],
pi_l = icpred[, "lwr"],
pi_u = icpred[, "upr"]
)[ordem, ]# Bloco 3 — Gráfico
pt=ggplot(df_plot, aes(x = x, y = y)) +
geom_ribbon(aes(ymin = pi_l, ymax = pi_u, fill = "IP 95% para Y₀"),
alpha = 0.10) +
geom_ribbon(aes(ymin = ci_l, ymax = ci_u, fill = "IC 95% para E[Y|x]"),
alpha = 0.20) +
geom_line(aes(y = fit, color = "Reta ajustada"), linewidth = 1) +
geom_point(aes(color = "Dados observados"), size = 2) +
scale_fill_manual(name = NULL,
values = c("IC 95% para E[Y|x]" = "darkgreen",
"IP 95% para Y₀" = "purple")) +
scale_color_manual(name = NULL,
values = c("Dados observados" = "blue",
"Reta ajustada" = "red")) +
labs(title = "Bandas de Confiança vs Bandas de Predição (95%)",
x = "Anúncios", y = "Carros Vendidos") +
theme_minimal() +
theme(legend.position = "top")
Diferença conceitual entre Intervalo de Confiança e Intervalo de Predição:
Para um mesmo valor das variáveis preditoras (por exemplo, 50 anúncios), diferentes vendas podem ocorrer na população devido à variabilidade natural do fenômeno.
Intervalo de Confiança para \(E[Y|x_0]\): Estima a média de todas as vendas possíveis quando fazemos 50 anúncios. É um valor fixo (constante) que queremos estimar. A incerteza vem apenas de não conhecermos perfeitamente os parâmetros do modelo.
Intervalo de Predição para \(Y_0\): Prevê quantos carros venderemos especificamente na próxima vez que fizermos 50 anúncios. Como cada venda individual varia naturalmente (mesmo mantendo x fixo), o intervalo precisa ser mais amplo para capturar essa variabilidade adicional.
Por que o Intervalo de Predição é mais largo?
Porque incorpora duas fontes de incerteza:
- Não sabemos exatamente onde está a média (igual ao IC)
- Mesmo sabendo a média exata, os valores individuais variam ao redor dela (variabilidade natural do fenômeno)
Analogia: Se você joga um dado 100 vezes, consegue estimar bem a média (≈3.5). Mas prever o resultado do próximo lançamento específico é muito mais incerto!